本文主要针对天池大数据竞赛之“O2O优惠券使用预测”的冠军队伍的思路和源码分析。在此感谢无私的前辈(诗人都藏在水底)[https://github.com/wepe/O2O-Coupon-Usage-Forecast]。
本文主要对模型训练xgb.py 做一些详细的分析。
文件:O2O-Coupon-Usage-Forecast/code/wepon/season one
xgb.py 训练xgboost模型,生成特征重要性文件,生成预测结果。单模型第一赛季A榜AUC得分0.798.
import包
首先作者import xgboost,因此我们需要安装一下它。
XGBoost是数据挖掘中用到一个新型的数据分析包,相对其它Boosting模型更加高效。
安装教程xgboost install on windows
导入数据
#将数据集导入
dataset1 = pd.read_csv('data/dataset1.csv')
dataset2 = pd.read_csv('data/dataset2.csv')
dataset3 = pd.read_csv('data/dataset3.csv')dataset1、dataset2有56个特征,图是前十个。
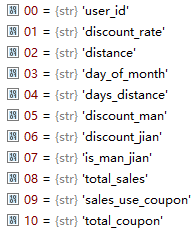
dataset3有57个特征
#将dataset1的label列的-1都换成0
dataset1.label.replace(-1,0,inplace=True)
dataset2.label.replace(-1,0,inplace=True)
#删除重复项
dataset1.drop_duplicates(inplace=True)
dataset2.drop_duplicates(inplace=True)
dataset3.drop_duplicates(inplace=True)将dataset1和dataset2连起来
dataset12 = pd.concat([dataset1,dataset2],axis=0)dataset1_y赋值为dataset1的label列
dataset1_y = dataset1.label删除dataset1的'user_id','label','day_gap_before','day_gap_after'字段,赋值给dataset1_x
dataset1_x = dataset1.drop(['user_id','label','day_gap_before','day_gap_after'],axis=1) # 'day_gap_before','day_gap_after' cause overfitting, 0.77
dataset2_y = dataset2.label
dataset2_x = dataset2.drop(['user_id','label','day_gap_before','day_gap_after'],axis=1)
dataset12_y = dataset12.label
dataset12_x = dataset12.drop(['user_id','label','day_gap_before','day_gap_after'],axis=1)
dataset3_preds = dataset3[['user_id','coupon_id','date_received']]
dataset3_x = dataset3.drop(['user_id','coupon_id','date_received','day_gap_before','day_gap_after'],axis=1)用shape属性来显示数据的格式
print dataset1_x.shape,dataset2_x.shape,dataset3_x.shape若输出:(8618,36) 表示这个表格有8618行和36列的数据,其中dimensions[0]为8618,dimensions[1]为36
加载数据到xgboost
dataset1、dateset2、dateset3 为xgb的DMatrix
dataset1 = xgb.DMatrix(dataset1_x,label=dataset1_y)
dataset2 = xgb.DMatrix(dataset2_x,label=dataset2_y)
dataset12 = xgb.DMatrix(dataset12_x,label=dataset12_y)
dataset3 = xgb.DMatrix(dataset3_x)设置参数
params={'booster':'gbtree',
'objective': 'rank:pairwise',
'eval_metric':'auc',
'gamma':0.1,
'min_child_weight':1.1,
'max_depth':5,
'lambda':10,
'subsample':0.7,
'colsample_bytree':0.7,
'colsample_bylevel':0.7,
'eta': 0.01,
'tree_method':'exact',
'seed':0,
'nthread':12
}训练模型
model = xgb.train(params,dataset12,num_boost_round=3500,evals=watchlist) 预测测试集
dataset3_preds['label'] = model.predict(dataset3)
dataset3_preds.label = MinMaxScaler().fit_transform(dataset3_preds.label)
dataset3_preds.sort_values(by=['coupon_id','label'],inplace=True)
dataset3_preds.to_csv("xgb_preds.csv",index=None,header=None)
print dataset3_preds.describe()保存特征评分
feature_score = model.get_fscore()
feature_score = sorted(feature_score.items(), key=lambda x:x[1],reverse=True)
fs = []
for (key,value) in feature_score:
fs.append("{0},{1}\n".format(key,value))
with open('xgb_feature_score.csv','w') as f:
f.writelines("feature,score\n")
f.writelines(fs)总结
这次算是对自己之前的各种理论知识进行了一次梳理,感觉平时过于注重算法的研究,并没有注意到宏观上的操作。以后要多加注意