最近学校出了个科学上网的小网站,但流量有限,可以通过每天打卡来获取几十兆流量。奈何自己记性很差,总忘记打卡。因此决定写一个自动打卡的小程序。
思路总结
- 用抓包工具仔细分析下登陆以及回帖时post了哪些数据,这些数据从何而来(chrome)
- python requests库,用requests.Session().post来登陆和回帖,用get来读取页面内容;
- 登陆之后,正则找到“签到”或"不能签到",来进行下一步
- 若能签到,就发出签到URL的请求(因为链接从原来上来说是一种URL)
- 记录每次签到的log
- 最后的最后,使用写个.sh脚本,里面运行这个python程序,配置个相应的plist,每天自动执行(MAC OS)
模拟登陆原理
浏览器访问服务器的过程
一次完整的HTTP请求过程从TCP三次握手建立连接成功后开始。
- 用户发起请求(点击等)
- 浏览器向WEB服务器发出一个请求Http Request(请求)
- Web服务器发相应Http Response
- 浏览器解析
HTTP消息
更多关于HTTP请求过程,见参考资料一次完整的HTTP请求过程
HTTP 是一种无状态的协议,协议本身不保留之前的一切请求信息和响应信息,也就是说,对于一个刚刚发送了 HTTP 请求的客户端再次发起请求时,服务端并不知道之前访问过。这样设计的理由是为了更快地处理大量事务,确保协议的可伸缩性,而特意把 HTTP 协议设计如此简单。 但是,无状态导致业务处理就变得棘手了,一个简单的例子就是网上购物的时候,当我在一个页面把商品加入购物车的时候,正当我要跳转到支付页面时,如果没有一种机制来保持我的登录状态,那么之前选的商品全部丢失了。 因此,为了在无状态的HTTP协议之上维护会话状态,使服务器可以知道当前是和哪个客户端打交道,于是Cookie技术应运而生,Cookie通俗的理解就是服务端分配给客户端的一个标识。
Cookie原理
Cookie原理其实也非常简单,总共4个步骤维护HTTP会话。 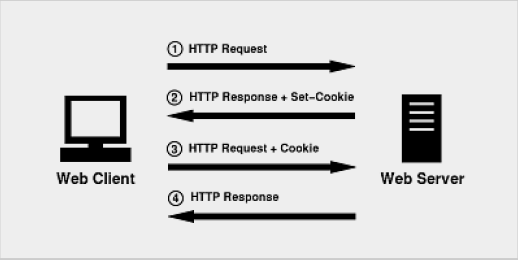 1. 浏览器第一次发起HTTP请求时,没有携带任何Cookie信息,服务器收到请求并返回给浏览器的HTTP响应,同时HTTP响应包括了一个响应头Set-Cookie字段,它的值是要设置的Cookie。 2. 浏览器收到来自服务器的HTTP响应,响应头中发现有Set-Cookie字段,就会将该字段的值保存在内存或者硬盘中。 3. 浏览器下次给该服务器发送HTTP请求时,会将Cookie信息附加在HTTP请求的头字段Cookie中。 4. 服务器收到这个HTTP请求,发现请求头中有Cookie字段,便知道之前就和这个用户打过交道了。
1. 浏览器第一次发起HTTP请求时,没有携带任何Cookie信息,服务器收到请求并返回给浏览器的HTTP响应,同时HTTP响应包括了一个响应头Set-Cookie字段,它的值是要设置的Cookie。 2. 浏览器收到来自服务器的HTTP响应,响应头中发现有Set-Cookie字段,就会将该字段的值保存在内存或者硬盘中。 3. 浏览器下次给该服务器发送HTTP请求时,会将Cookie信息附加在HTTP请求的头字段Cookie中。 4. 服务器收到这个HTTP请求,发现请求头中有Cookie字段,便知道之前就和这个用户打过交道了。
理解了Cookie的基本原理之后,我们就可以尝试用Python来实现模拟登录。
点击登陆后,究竟发生了什么?
为了看看浏览器究竟做了什么,我们首先进入登录界面,随便输入一个密码,点击登录。打开Chrome开发者工具条(F12)。选择Network下的Headers: 
从上图我们可以发现以下关键信息: 1. 登陆的URL地址是General下面的Request URL的那个。 2. 登录需要提供的表单(Form Data)有三个,email(用户名),passwd(密码),remember_me(就是那个“记住我”的选项,我们可以从它的html中搜索得出,如下图)。 
到这里,基本上摸清了浏览器登录时所需要的数据是如何获取的了,那么现在就可以开始撸代码用Python模拟浏览器来登录。
由于我今天登陆的网站实在是太简易了,也不需要分析header就可以登陆。所以此处省略header的分析。
我打算基于python的requests库来完成这一过程。
python实现模拟登陆
1
2
3
4
5
6
7
8
9
10
11
email='jiayi797@163.com'
password='这里加密了'
loginurl = 'https://ssr.0v0.loan/auth/login'
# 这行代码,是用来维持cookie的,你后续的操作都不用担心cookie,他会自动带上相应的cookie
s = requests.Session()
# 我们需要带表单的参数
loginparams={'email':email,'passwd':password,'remember_me':'ture'}
# post 数据实现登录
r = s.post(loginurl,data=loginparams)
# 验证是否登陆成功,抓取首页看看内容
r = s.get(loginurl)
运行完这些后,我们发现r已经有内容了。接下来我们进行自动签到。
签到
我们查看r._content的内容,是主页的html内容。很长。为了方便分析,我只拿出“签到”标签下的内容:
1 | <div class="col-md-6"> |
需要注意的还有以下这个脚本:
1 | <script> |
从脚本中我们读到,签到的类型是post,url是/user/checkin, 因此我们试一下post一个这样的url会有什么后果。
1
2
3
checkinUrl="https://ssr.0v0.loan/user/checkin"
r=s.post(checkinUrl)#执行签到
r = s.get(loginurl)#查看签到结果
我们发现,签到栏的HTML已经变成了;
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
<div class="col-md-6">
<div class="box box-primary">
<div class="box-header">
<i class="fa fa-pencil"></i>
<h3 class="box-title">签到获取流量</h3>
</div>
<!-- /.box-header -->
<div class="box-body">
<p> 每24小时可以签到一次。</p>
<p>上次签到时间:<code>2017-04-05 14:08:02</code></p>
<p><a class="btn btn-success btn-flat disabled" href="#">不能签到</a></p>
<p id="checkin-msg"></p>
</div>
<!-- /.box-body -->
</div>
<!-- /.box -->
</div>
<!-- /.col (right) -->
即:
<button id="checkin" class="btn btn-success btn-flat">签到</button>变成了:
<a class="btn btn-success btn-flat disabled" href="#">不能签到</a>大题框架搭完了。接下来要做的就是一些细节。
判断是否已签到
接下来要做的就是用正则,找到“签到”或者“不能签到”的对应标签,来获得一个当前状态。
首先我想到的是最简单的方式,用python自带的re.search()。
1
2
3
4
5
6
7
8
9
10
11
12
def check(str):
hasCheckIn='<button id="checkin" class="btn btn-success btn-flat">'
noChecked='<a class="btn btn-success btn-flat disabled" href="#">'
yes=re.search(hasCheckIn,str)
if yes==None:
no=re.search(noChecked,str)
if no==None:
return -1 #什么都没找到
else:
return 0#找到了“不能签到”
else:
return 1#找到了“签到”
获取当前流量
先找到流量的对应标签:
1 | <dl class="dl-horizontal"> |
想要获取标签内的内容(而不是暴力地匹配字符串),我们就需要用到另一种匹配方式——正则表达式
1 | #正则表达式获取<tr></tr>之间内容 |
其中,res是匹配模式。 r’是匹配模式的开头, <tr是先匹配字符串<tr .是匹配任意字符,除了换行符 *是匹配0个或多个的表达式 ?是匹配0个或1个由前面的正则表达式定义的片段,非贪婪方式 依次类推
re.S使.匹配包括换行在内的所有字符 re.M:多行匹配,影响 ^ 和 $
因此,我们的思路是,匹配<dt>总流量</dt>到</dd></dl>之间的内容。
改写以上匹配式子为:
1 | def match_flows(str): |
记录当前操作
首先
import logging然后:
# 配置日志文件和日志级别
logging.basicConfig(filename='logger.log', level=logging.INFO)
nowtime=time.strftime('%Y-%m-%d',time.localtime(time.time()))#获取当前时间
str= nowtime+',\t总流量:'+lastFlows[0]+',\t已用流量:'+lastFlows[1]+',\t剩余流量:'+lastFlows[2]
logging.info(str)#写入日志操作系统定期执行Python脚本
见参考文献4.
全部代码
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
#! /usr/bin/env python
# coding:utf-8
import sys
import re
import requests
import logging
import time
# 配置日志文件和日志级别
logging.basicConfig(filename='logger.log', level=logging.INFO)
def check(str):
hasCheckIn='<button id="checkin" class="btn btn-success btn-flat">'
noChecked='<a class="btn btn-success btn-flat disabled" href="#">'
yes=re.search(hasCheckIn,str)
if yes==None:
no=re.search(noChecked,str)
if no==None:
return -1 #什么都没找到
else:
return 0#找到了“不能签到”
else:
return 1#找到了“签到”
def match_flows(str):
res = r'<dl class="dl-horizontal">(.*?)</dl>'
mm = re.findall(
res, str, re.S | re.M)
res=r'<dd>(.*?)</dd>'
mm= re.findall(
res, mm[0], re.S | re.M)
return mm
## 这段代码是用于解决中文报错的问题
reload(sys)
sys.setdefaultencoding("utf8")
email='你的账号'
password='你的密码'
loginurl = 'https://ssr.0v0.loan/auth/login'
# 这行代码,是用来维持cookie的,你后续的操作都不用担心cookie,他会自动带上相应的cookie
s = requests.Session()
# 我们需要带表单的参数
loginparams={'email':email,'passwd':password,'remember_me':'ture'}
# post 数据实现登录
r = s.post(loginurl,data=loginparams)
# 验证是否登陆成功,抓取首页看看内容
r = s.get(loginurl)
res=check(r.content)#0=不能签到;1=可以签到;-1=什么都没找到;
if(res==1):#可以签到
checkinUrl="https://ssr.0v0.loan/user/checkin"
r=s.post(checkinUrl)
r = s.get(loginurl)
lastFlows=match_flows(r.content)
nowtime=time.strftime('%Y-%m-%d',time.localtime(time.time()))#获取当前时间
str= nowtime+',\t总流量:'+lastFlows[0]+',\t已用流量:'+lastFlows[1]+',\t剩余流量:'+lastFlows[2]
print str
logging.info(str)
参考文献
签到成功后: