推荐系统根据用户过去的购买和搜索历史,以及其他用户的行为,自主地为各个用户识别推荐内容。
常见的推荐系统有以下几类: - 协同过滤推荐 - 基于内容的推荐 - 混合推荐
参考文献协同过滤和基于内容推荐有什么区别?给出了一个很好的例子,来区分协同过滤和内容推荐: 举个简单的小例子,我们已知道: 用户u1喜欢的电影是A,B,C 用户u2喜欢的电影是A, C, E, F 用户u3喜欢的电影是B,D
我们需要解决的问题是:决定对u1是不是应该推荐F这部电影
基于内容的做法:要分析F的特征和u1所喜欢的A、B、C的特征,需要知道的信息是A(战争片),B(战争片),C(剧情片),如果F(战争片),那么F很大程度上可以推荐给u1,这是基于内容的做法,你需要对item进行特征建立和建模。
协同过滤的办法:那么你完全可以忽略item的建模,因为这种办法的决策是依赖user和item之间的关系,也就是这里的用户和电影之间的关系。我们不再需要知道ABCF哪些是战争片,哪些是剧情片,我们只需要知道用户u1和u2按照item向量表示,他们的相似度比较高,那么我们可以把u2所喜欢的F这部影片推荐给u1
下面我们对这几种推荐算法进行简介。
协同过滤推荐算法
简介
简介:通过在用户的一系列行为中寻找特定模式来产生用户特殊推荐。 输入:仅仅依赖于惯用数据(例如评价、购买、下载等用户偏好行为)。 方式:可通过单个用户行为单独构造模型;也可以通过其他用户行为,使用群组知识并基于相似用户来形成推荐内容。 类型: - 基于领域的协同过滤(user-based或item-based) - 基于模型的协同过滤(矩阵因子分解、受限玻尔兹曼机、贝叶斯网络等等)
实例
为了更好地理解,我们以博客推荐为例。 已知用户已订阅并阅读博客的信息,可以根据用户偏好来对他们进行分组。例如可以将阅读多篇相同博客的用户分到一个组。基于组信息,可识别出该组阅读了哪些最流行的博客,然后对于群组中的某个用户,可以向他推荐他还未阅读也未订阅的最流行的博客。
- 在下图的表中,行是一组博客,列是用户,表是该用户阅读该文章的数量。
- 通过根据用户的阅读习惯来为用户划分集群。比如使用一个 nearest-neighbor 算法:找到与当前用户user口味相近的k各用户;对用户u没有见过的博客p,利用k个近邻对p进行预测评分。
- 用以上算法我们得到两个分别包含两个用户的cluster,每个cluster中的成员都有相似的阅读习惯:Marc 和 Elise(他们都阅读了多篇关于 Linux® 和云计算的文章)形成 Cluster 1。Cluster 2 中包含 Megan 和 Jill,他们都阅读了多篇关于 Java™ 和敏捷性的文章。

nearest-nerghbor算法
刚才说到了用nearest-nerghbor算法来计算user-based的user相似度,然后再进行推荐,那么就带来了两个问题: - 如何度量user之间的相似性? - 如何推荐博客?
- 首先解决第一个问题,如何度量相似性?
先说结论:采用改进的余弦相似度来进行度量。
首先我们看一下Pearson相关系数和余弦相似度。 pearson相关系数用来描诉两组向量一同变化的趋势,取值从+1(强正相关)到-1(强负相关)。用户a和用户b的相似度: 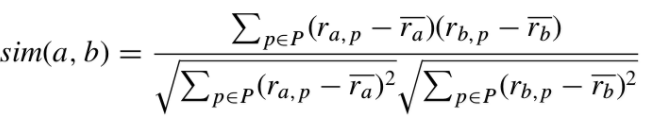 其中: - \(r_{a,p}\)表示用户a对博客p的阅读量; - \(\overline{r_a}\)表示用户a的平均阅读量; - pearson相关系数越接近于1,那么用户a、b月相似。
其中: - \(r_{a,p}\)表示用户a对博客p的阅读量; - \(\overline{r_a}\)表示用户a的平均阅读量; - pearson相关系数越接近于1,那么用户a、b月相似。
然而,这并不完美,pearson相关系数存在以下缺陷: - 未考虑博客的数量对相似度的影响; 例如:用户a与b有两个重叠项,用户a与c有10个重叠项;但有可能出现\(sim(a,c)< sim(a,b)\)的情况,因为计算pearson系数时,重叠项的个数没有影响。但这并不能说明用户b更与a相似。 - 如果只有一个重叠项,或所有重叠项的评分都相等,就无法计算pearson相关系数(分子或分母为0)。
接下来我们看看另一种相似度度量方式——余弦相似度。 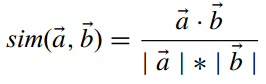 这代表两个user向量的夹角。但这与向量的大小无关,因此伟大的科学家们提出了改进的余弦相似度:
这代表两个user向量的夹角。但这与向量的大小无关,因此伟大的科学家们提出了改进的余弦相似度: 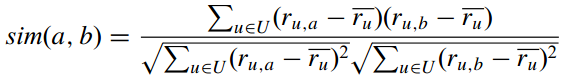 它的取值范围在\([-1,1]\)。
它的取值范围在\([-1,1]\)。
- 接下来我们来解决第二个问题,如何推荐博客?
先选取k个用户的近邻,利用这k个近邻的阅读排行来做推荐。
其实,这个方法是基于user-based的。它并不是完美的。有两个问题:数据稀疏(用户看过的博客非常少)和算法复杂度高。而这两个问题可以通过item-based方法来解决。具体内容见参考文献基于物品的协同过滤推荐算法——读“Item-Based Collaborative Filtering Recommendation Algorithms”
协同过滤的方法
上面提到的方法是基于领域(记忆)的方法,而还有一类叫基于模型的方法——即隐语义模型。矩阵分解就是实现隐语义模型的成果实现。参考文献个性化推荐中的矩阵分解技术给出了矩阵分解的方法。 矩阵分解的核心思想认为用户的兴趣只受少数几个因素的影响,因此将稀疏且高维的User-Item评分矩阵分解为两个低维矩阵,即通过User、Item评分信息来学习到的用户特征矩阵P和物品特征矩阵Q,通过重构的低维矩阵预测用户对产品的评分。
基于内容的推荐
基于内容的推荐是指根据用户的行为来推荐内容。
基于内容推荐的过程: - item Representation:为每个item抽取特征(也就是item的内容)来表示item; - Profile Learning:利用用户过去喜欢(及不喜欢)的item的特征数据,来学习出此用户的喜好特征(profile); - Recommendation Generation:通过比较上一步得到的用户profile与候选item的特征,为此用户推荐一组相关性最大的item。
上面三个步骤有一张很细致的流程图(第一步对应着Content Analyzer,第二步对应着Profile Learner,第三步对应着Filtering Component): 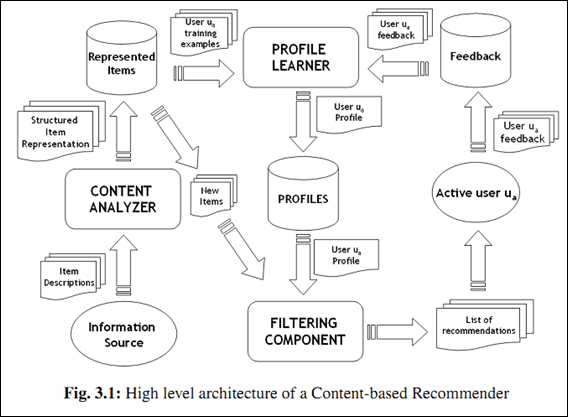 举个例子,对于博客推荐来说,一个item就是一篇博客; - 第一步,首先从文章内容中抽取文章的特征。常用算法就是利用这篇文章的关键词来代表这篇文章,而每个词对应的权重往往使用tf-idf来计算。利用这种方法,将一篇文章用一个向量来表示即可; - 第二步,根据用户过去喜好来刻画用户profile。最简单的方法可以把用户所有喜欢的文章对应的向量的平均值作为此用户的profile。比如某个用户经常关注与推荐系统有关的文章,那么他的profile中“CB”、“CF”和“推荐”对应的权重值就会较高。 - 第三步,利用所有item与用户profile的相关度进行推荐。一个常用的相关度计算方法是向量的cos夹角。最终把候选item里与此用户最相关(cosine值最大)的N个item作为推荐返回给此用户。
举个例子,对于博客推荐来说,一个item就是一篇博客; - 第一步,首先从文章内容中抽取文章的特征。常用算法就是利用这篇文章的关键词来代表这篇文章,而每个词对应的权重往往使用tf-idf来计算。利用这种方法,将一篇文章用一个向量来表示即可; - 第二步,根据用户过去喜好来刻画用户profile。最简单的方法可以把用户所有喜欢的文章对应的向量的平均值作为此用户的profile。比如某个用户经常关注与推荐系统有关的文章,那么他的profile中“CB”、“CF”和“推荐”对应的权重值就会较高。 - 第三步,利用所有item与用户profile的相关度进行推荐。一个常用的相关度计算方法是向量的cos夹角。最终把候选item里与此用户最相关(cosine值最大)的N个item作为推荐返回给此用户。
接下来我们来详细了解一下以上三个步骤。 ## item representation 想用属性来描述item时,我们会遇到两种属性: - 结构化(structured)属性:取值固定,例如身高、学历、籍贯等; - 非结构化(unstructured)属性:如文章;
接下来我们针对如何将非结构化的属性转化为结构化属性。我们采用最常用的向量空间模型(Vector Space Model,简称VSM): 已知: - 所有文章集合\(D={d_1,d_2,...,d_N}\) - 所有文章中出现的词的集合\(T={t_1,t_2,...,t_n}\)
目标:用向量表示文章: - 第j篇文章被表示为\(d_j={w_{1j},w_{2j},...,w_{nj}}\),其中\(w_{nj}\)表示第\(n\)个词在文章\(j\)中的权重。
最简单的表示权重\(w_{nj}\)的方式是直接统计出现次数。但一般来说我们还是使用tf-idf: \[TFIDF(t_k,d_j)=TF(t_k,d_j)log \frac{N}{n_k}\] 其中: - \(TF(t_k,d_j)\)是词频,表示第\(k\)个词在文章\(j\)中出现的次数; - \(log \frac{N}{n_k}\)是逆文档词频,其中\(n_k\)是所有文章中包括第\(k\)个词的文章数量;\(N\)是文章数量。
最终第\(k\)个词在文章\(j\)中的权重由下面公式获得: \[w_{k,j}=\frac{TFIDF(t_k,d_j)}{\sqrt{\sum_{s=1}^{|T|}TFIDF(t_k,d_j)^2}}\] 做归一化的好处是不同文章之间的表示向量被归一到一个量级上,便于下面步骤的操作。
Profile Learning
假设用户u已经对一些item给出了他的喜好判断,喜欢其中的一部分item,不喜欢其中的另一部分。 那么,这一步要做的就是通过用户u过去的这些喜好判断,为他产生一个模型。有了这个模型,我们就可以根据此模型来判断用户u是否会喜欢一个新的item。所以,我们要解决的是一个典型的有监督分类问题,理论上机器学习里的分类算法都可以照搬进这里。
下面我们简单介绍下CB里常用的一些学习算法: 1. KNN 2. Rocchio 3. 决策树(DT) 4. 线性分类(LC) 5. 朴素贝叶斯(NB)
Recommendation Generation
如果上一步Profile Learning中使用的是分类模型(如DT、LC和NB),那么我们只要把模型预测的用户最可能感兴趣的n个item作为推荐返回给用户即可。而如果Profile Learning中使用的直接学习用户属性的方法(如Rocchio算法),那么我们只要把与用户属性最相关的n个item作为推荐返回给用户即可。其中的用户属性与item属性的相关性可以使用如cosine等相似度度量获得。
基于内容的推荐的优缺点
优点 1. 用户之间的独立性(User Independence):既然每个用户的profile都是依据他本身对item的喜好获得的,自然就与他人的行为无关。而协同过滤就需要利用很多其他人的数据。因此这种用户独立性带来的一个显著好处是别人不管对item如何作弊(比如利用多个账号把某个产品的排名刷上去)都不会影响到自己。 2. 好的可解释性(Transparency):如果需要向用户解释为什么推荐了这些产品给他,你只要告诉他这些产品有某某属性,这些属性跟你的品味很匹配等等。 3. 新的item可以立刻得到推荐(New Item Problem):只要一个新item加进item库,它就马上可以被推荐,被推荐的机会和老的item是一致的。而协同过滤对于新item就很无奈,只有当此新item被某些用户喜欢过(或打过分),它才可能被推荐给其他用户。所以,如果一个纯CF的推荐系统,新加进来的item就永远不会被推荐:( 。这也就是常说的item冷启动问题。
缺点 1. item的特征抽取一般很难(Limited Content Analysis):如果系统中的item是文档(如个性化阅读中),那么我们现在可以比较容易地使用信息检索里的方法来“比较精确地”抽取出item的特征。但很多情况下我们很难从item中抽取出准确刻画item的特征,比如电影推荐中item是电影,社会化网络推荐中item是人,这些item属性都不好抽。其实,几乎在所有实际情况中我们抽取的item特征都仅能代表item的一些方面,不可能代表item的所有方面。这样带来的一个问题就是可能从两个item抽取出来的特征完全相同,这种情况下基于内容的推荐就完全无法区分这两个item了。比如如果只能从电影里抽取出演员、导演,那么两部有相同演员和导演的电影对于基于内容的推荐来说就完全不可区分了。 2. 无法挖掘出用户的潜在兴趣(Over-specialization):既然CB的推荐只依赖于用户过去对某些item的喜好,它产生的推荐也都会和用户过去喜欢的item相似。如果一个人以前只看与推荐有关的文章,那基于内容的推荐只会给他推荐更多与推荐相关的文章,它不会知道用户可能还喜欢数码。 3. 无法为新用户产生推荐(New User Problem):新用户没有喜好历史,自然无法获得他的profile,所以也就无法为他产生推荐了。当然,这个问题协同过滤也有。