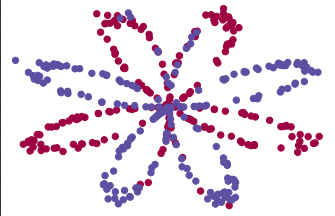
# 这个函数原本在panar_utils.py里 defload_planar_dataset(): np.random.seed(1) m = 400# 样本数量 N = int(m/2) # 每个类别的数量 D = 2# 维度 # 初始化X,Y X = np.zeros((m,D)) Y = np.zeros((m,1),dtype='uint8') a = 4# 花儿最大长度 for j inrange(2): ix = range(N*j,N*(j+1)) t = np.linspace(j*3.12,(j+1)*3.12,N) + np.random.randn(N)*0.2# theta r = a*np.sin(4*t) + np.random.randn(N)*0.2# radius X[ix] = np.c_[r*np.sin(t), r*np.cos(t)] Y[ix] = j X = X.T Y = Y.T
return X, Y
X,Y = load_planar_dataset() print X.shape,Y.shape
(2L, 400L) (1L, 400L)
此时你得到了:
一个numpy-array(matrix) X,包括特征(X1,X2)
一个numpy-arrya(vector) Y,包含一列标签(0或1)
接下来用matplotlib将这个“花儿”数据集可视化,其中: - y = 0 -> 红色 - y = 1 -> 蓝色
defplot_decision_boundary(model, X, y): # Set min and max values and give it some padding x_min, x_max = X[0, :].min() - 1, X[0, :].max() + 1 y_min, y_max = X[1, :].min() - 1, X[1, :].max() + 1 h = 0.01 # Generate a grid of points with distance h between them xx, yy = np.meshgrid(np.arange(x_min, x_max, h), np.arange(y_min, y_max, h)) # Predict the function value for the whole grid Z = model(np.c_[xx.ravel(), yy.ravel()]) Z = Z.reshape(xx.shape) # Plot the contour and training examples plt.contourf(xx, yy, Z, cmap=plt.cm.Spectral) plt.ylabel('x2') plt.xlabel('x1') plt.scatter(X[0, :], X[1, :], c=y, cmap=plt.cm.Spectral)
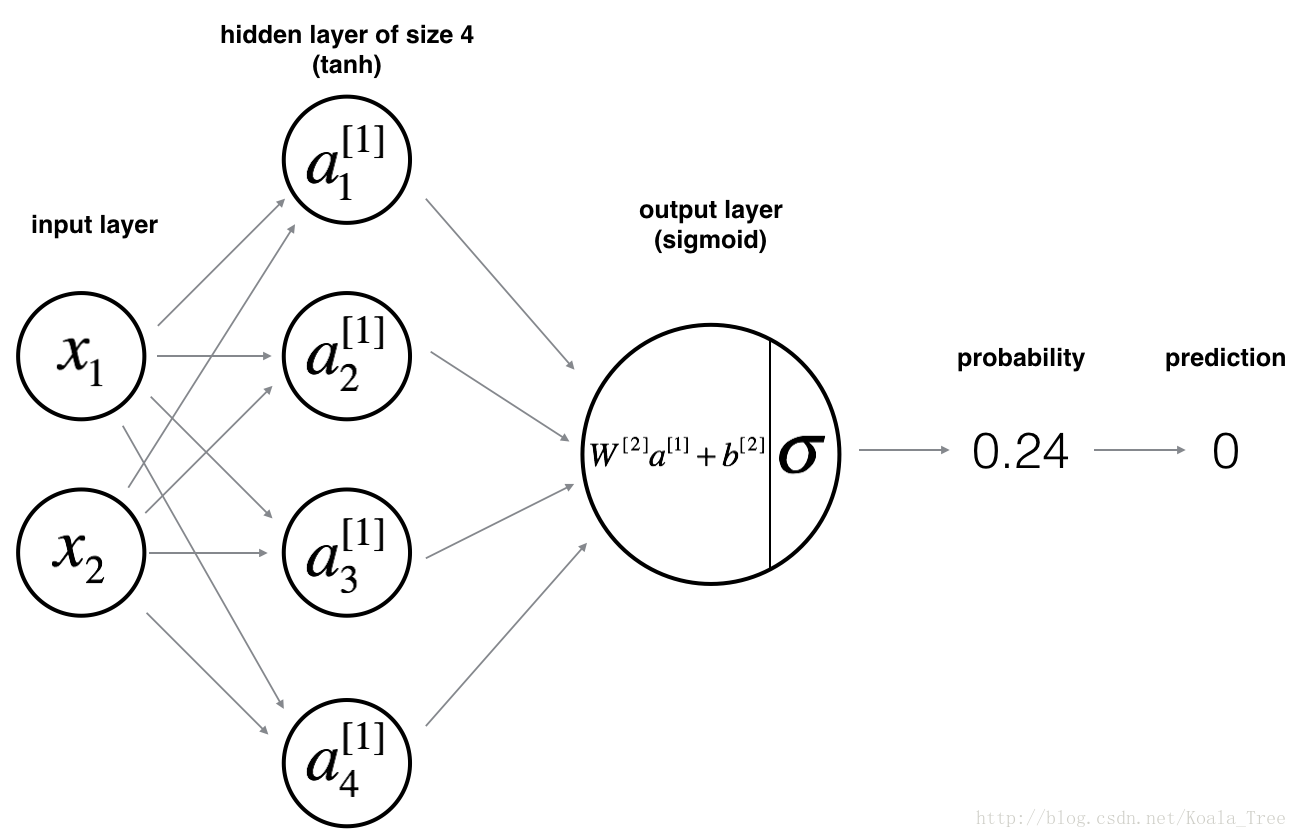
deflayer_sizes(X, Y): """ Arguments: X -- input dataset of shape (input size, number of examples) Y -- labels of shape (output size, number of examples) Returns: n_x -- the size of the input layer n_h -- the size of the hidden layer n_y -- the size of the output layer """ ### START CODE HERE ### (≈ 3 lines of code) n_x = X.shape[0] # size of input layer n_h = 4 n_y = Y.shape[0]# size of output layer ### END CODE HERE ### return (n_x, n_h, n_y) n_x, n_h, n_y = layer_sizes(X,Y)
Exercise: Implement the function initialize_parameters().
Instructions: - Make sure your parameters’ sizes are right. Refer to the neural network figure above if needed. - You will initialize the weights matrices with random values. - Use: np.random.randn(a,b) * 0.01 to randomly initialize a matrix of shape (a,b). - You will initialize the bias vectors as zeros. - Use: np.zeros((a,b)) to initialize a matrix of shape (a,b) with zeros.
Instructions: - Look above at the mathematical representation of your classifier. - You can use the function sigmoid(). It is built-in (imported) in the notebook. - You can use the function np.tanh(). It is part of the numpy library. - The steps you have to implement are: 1. Retrieve each parameter from the dictionary "parameters" (which is the output of initialize_parameters()) by using parameters[".."]. 2. Implement Forward Propagation. Compute \(Z^{[1]}, A^{[1]}, Z^{[2]}\) and \(A^{[2]}\) (the vector of all your predictions on all the examples in the training set). - Values needed in the backpropagation are stored in "cache". The cache will be given as an input to the backpropagation function.
defforward_propagation(X, parameters): """ Argument: X -- input data of size (n_x, m) parameters -- python dictionary containing your parameters (output of initialization function) Returns: A2 -- The sigmoid output of the second activation cache -- a dictionary containing "Z1", "A1", "Z2" and "A2" """ # Retrieve each parameter from the dictionary "parameters" ### START CODE HERE ### (≈ 4 lines of code) # 参数获取 W1 = parameters["W1"] b1 = parameters["b1"] W2 = parameters["W2"] b2 = parameters["b2"] ### END CODE HERE ###
# Implement Forward Propagation to calculate A2 (probabilities) ### START CODE HERE ### (≈ 4 lines of code) # 计算预测值 Z1 = np.dot(W1, X) + b1 A1 = np.tanh(Z1) Z2 = np.dot(W2, A1) + b2 A2 = sigmoid(Z2) ### END CODE HERE ###
# Note: we use the mean here just to make sure that your output matches ours. print(np.mean(cache['Z1']) ,np.mean(cache['A1']),np.mean(cache['Z2']),np.mean(cache['A2']))
Exercise: Implement compute_cost() to compute the value of the cost \(J\).
Instructions: - There are many ways to implement the cross-entropy loss. To help you, we give you how we would have implemented \(- \sum\limits_{i=0}^{m} y^{(i)}\log(a^{[2](i)})\):
1 2
logprobs = np.multiply(np.log(A2),Y) cost = - np.sum(logprobs) # no need to use a for loop!
(you can use either np.multiply() and then np.sum() or directly np.dot()).
defcompute_cost(A2, Y, parameters): """ Computes the cross-entropy cost given in equation (13) Arguments: A2 -- The sigmoid output of the second activation, of shape (1, number of examples) Y -- "true" labels vector of shape (1, number of examples) parameters -- python dictionary containing your parameters W1, b1, W2 and b2 Returns: cost -- cross-entropy cost given equation (13) """
m = Y.shape[1] # number of example
# Compute the cross-entropy cost ### START CODE HERE ### (≈ 2 lines of code) # 误差计算 logprobs = np.multiply(np.log(A2), Y) + np.multiply(np.log(1-A2), (1-Y)) cost = -(1.0/m)*np.sum(logprobs) ### END CODE HERE ###
cost = np.squeeze(cost) # makes sure cost is the dimension we expect. # E.g., turns [[17]] into 17 assert(isinstance(cost, float))
Using the cache computed during forward propagation, you can now implement backward propagation.
Question: Implement the function backward_propagation().
Instructions: Backpropagation is usually the hardest (most mathematical) part in deep learning. To help you, here again is the slide from the lecture on backpropagation. You'll want to use the six equations on the right of this slide, since you are building a vectorized implementation.
To compute dZ1 you'll need to compute \(g^{[1]'}(Z^{[1]})\). Since \(g^{[1]}(.)\) is the tanh activation function, if \(a = g^{[1]}(z)\) then \(g^{[1]'}(z) = 1-a^2\). So you can compute \(g^{[1]'}(Z^{[1]})\) using (1 - np.power(A1, 2)).
defbackward_propagation(parameters, cache, X, Y): """ Implement the backward propagation using the instructions above. Arguments: parameters -- python dictionary containing our parameters cache -- a dictionary containing "Z1", "A1", "Z2" and "A2". X -- input data of shape (2, number of examples) Y -- "true" labels vector of shape (1, number of examples) Returns: grads -- python dictionary containing your gradients with respect to different parameters """ m = X.shape[1]
# First, retrieve W1 and W2 from the dictionary "parameters". # 获取参数 W1 = parameters["W1"] W2 = parameters["W2"]
Question: Implement the update rule. Use gradient descent. You have to use (dW1, db1, dW2, db2) in order to update (W1, b1, W2, b2).
General gradient descent rule: $ = - $ where \(\alpha\) is the learning rate and \(\theta\) represents a parameter.
Illustration: The gradient descent algorithm with a good learning rate (converging) and a bad learning rate (diverging). Images courtesy of Adam Harley.
defnn_model(X, Y, n_h, num_iterations = 10000, print_cost=False): """ Arguments: X -- dataset of shape (2, number of examples) Y -- labels of shape (1, number of examples) n_h -- size of the hidden layer num_iterations -- Number of iterations in gradient descent loop print_cost -- if True, print the cost every 1000 iterations Returns: parameters -- parameters learnt by the model. They can then be used to predict. """
defpredict(parameters, X): """ Using the learned parameters, predicts a class for each example in X Arguments: parameters -- python dictionary containing your parameters X -- input data of size (n_x, m) Returns predictions -- vector of predictions of our model (red: 0 / blue: 1) """
# Computes probabilities using forward propagation, and classifies to 0/1 using 0.5 as the threshold. ### START CODE HERE ### (≈ 2 lines of code) A2, cache = forward_propagation(X, parameters) predictions = (A2 > 0.5) ### END CODE HERE ###
return predictions
parameters, X_assess = predict_test_case()
predictions = predict(parameters, X_assess) print("predictions mean = " + str(np.mean(predictions)))
predictions mean = 0.666666666667
应用模型
将上面这个模型用在数据集上:
1 2 3 4 5 6 7 8 9 10
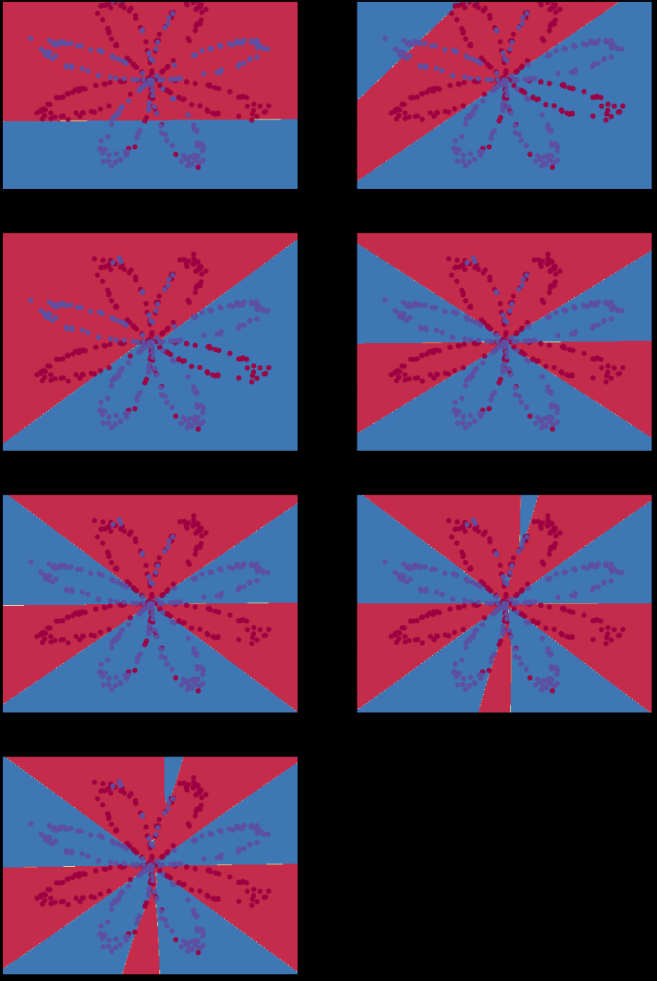
# Build a model with a n_h-dimensional hidden layer parameters = nn_model(X, Y, n_h = 4, num_iterations = 10000, print_cost=True)
# Plot the decision boundary plot_decision_boundary(lambda x: predict(parameters, x.T), X, Y) plt.title("Decision Boundary for hidden layer size " + str(4))