系统设计面试
- 设计某系统
- 设计微博
- 设计Facebook
- 设计滴滴、Uber
- 设计微信
- 设计点评
- 设计短网址系统 Tiny URL
- 设计NoSQL数据库
- 找问题
- 网站挂了怎么办
- 网站太慢怎么办
- 流量增长怎么办
设计新鲜事系统——类似微博、twitter的系统。
- 什么是新鲜事系统?news feed ?
- 朋友圈、微博的信息流
- 朋友信息集合
- 核心因素?
- 关注、被关注
- 每个人看到的新鲜事是不同的
常见错误:扮演关键词大师(负载均衡、Memcache、NodeJS、MongoDB、MySQL、Sharding、Consistent Hashing、Master Slave、HDFS、Hadoop...)
思考:或许只有两个用户呢?
系统设计面试评分标准:

系统设计4S分析法
- Scenario 场景
- 需要设计哪些功能、到哪个程度
- 询问
- Service 服务
- 将大系统拆分为小服务
- 拆分、Application、模块化
- Storage 存储(比较核心的部分)
- 数据如何存储与访问
- Schema/Data/SQL/NoSQL/File System
- Scale 升级
- 解决缺陷,处理可能遇到的问题
- Sharding/ Optimize / Special Case
设计Twitter
场景
场景连问
- 需要设计哪些功能?
- 需要承受多大访问量?
- DAU - 150M+ (日活跃用户 - DAU - Daily Active User)
- MAU 313M
场景
- 并发用户
- 日活跃*每个用户平均请求次数/一天多少秒 = ... = 100k
- 峰值 Peak = Average Concurrent User * 3 ~ 300k
- 快速增长的产品 —— MAX peak users in 3 mouth = Peak users * 2
- 读频率 —— Read QPS (Queries Per Second)
- 300k
- 写频率 —— Write QPS
- 5K
分析
- 枚举功能
- 注册、登录
- 用户个人主页
- 发、分享微博
- 上传图片、视频
- 搜索
- 时间线、信息流
- 关注、取关
- 对功能排序
分析出QPS有什么用?
- QPS = 100 :
- 笔记本做Web服务器就可以
- QPS = 1K
- 好点的Web服务器就行
- 需要考虑Single Point Failure(万一某服务挂了)
- QPS = 1M
- 考虑建设一个1000台的Web服务器集群
- 需要考虑维护问题(万一一台挂了)
QPS和Web Server(服务器) / Database(数据库) 之间的关系
- 一台Web Server承受量大约为1k的QPS (考虑到逻辑处理时间以及数据库查询的瓶颈)
- 一台SQL Database 承受量是1k的QPS (如果JOIN和INDEX 请求比较多,这个值会更小)
- 一台NoSQL Database (Cassandra) 约承受量是10k的QPS
- 一台NoSQL Database (内存cache型的) 约承受量是1M的QPS
服务
将大系统拆分为小服务
- Replay 重放需求
- Merge 归并需求
什么是服务 Service?
- 可以认为是逻辑处理的整合
- 对于同一类问题的逻辑处理归并在一个 Service 中
- 把整个 System 细分为若干个小的 Service
服务拆解
一个总路由,对应四个模块:
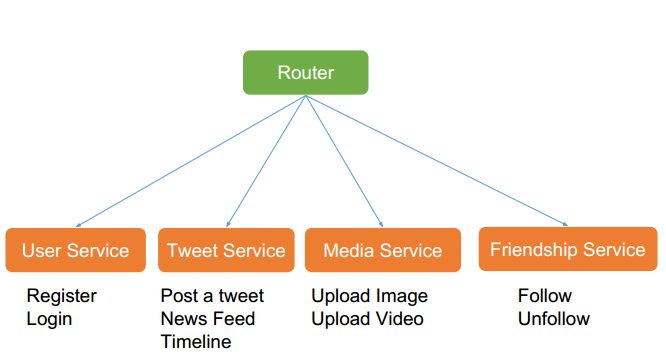
存储 —— 最重要
数据如何存储与访问
- 为每个 Service 选择存储结构
- 细化表结构
程序 = 算法 + 数据结构
系统 = 服务 + 数据存储
数据如何存储与访问
- 内存
- 一些临时的,丢了没关系的数据,可以不用持久化
- 关系型数据库 SQL Database
- 结构化数据 适合放在关系型数据库中
- 用户信息 User Table
- 非关系型数据库 NoSQL Database
- 小调查:Twitter的哪些信息适合放在非关系型数据库中?
- 推文 Tweets
- 社交图谱 Social Graph (followers)
- 文件系统 File System
- 小调查:非结构化数据 适合放在文件系统中
- 图片、视频 Media Files
也就是可以按照如下图所示设计Twitter的数据存储:

结构化数据如何细化表结构?

获取feed
Pull模型 —— 主动模型
用户查看news feed时,获取每个好友前100条微博,合并出前100条——K路归并算法
复杂度:
- News Feed --> 假如有N个关注对象,则复杂度 = N次db read(不可接受的复杂度) + K路归并(可忽略)
- Post a tweet --> 一次db write
pull 原理图:
- 用户请求消息
- 获取关注列表
- 获取关注列表的前100tweets
- merge之后返回
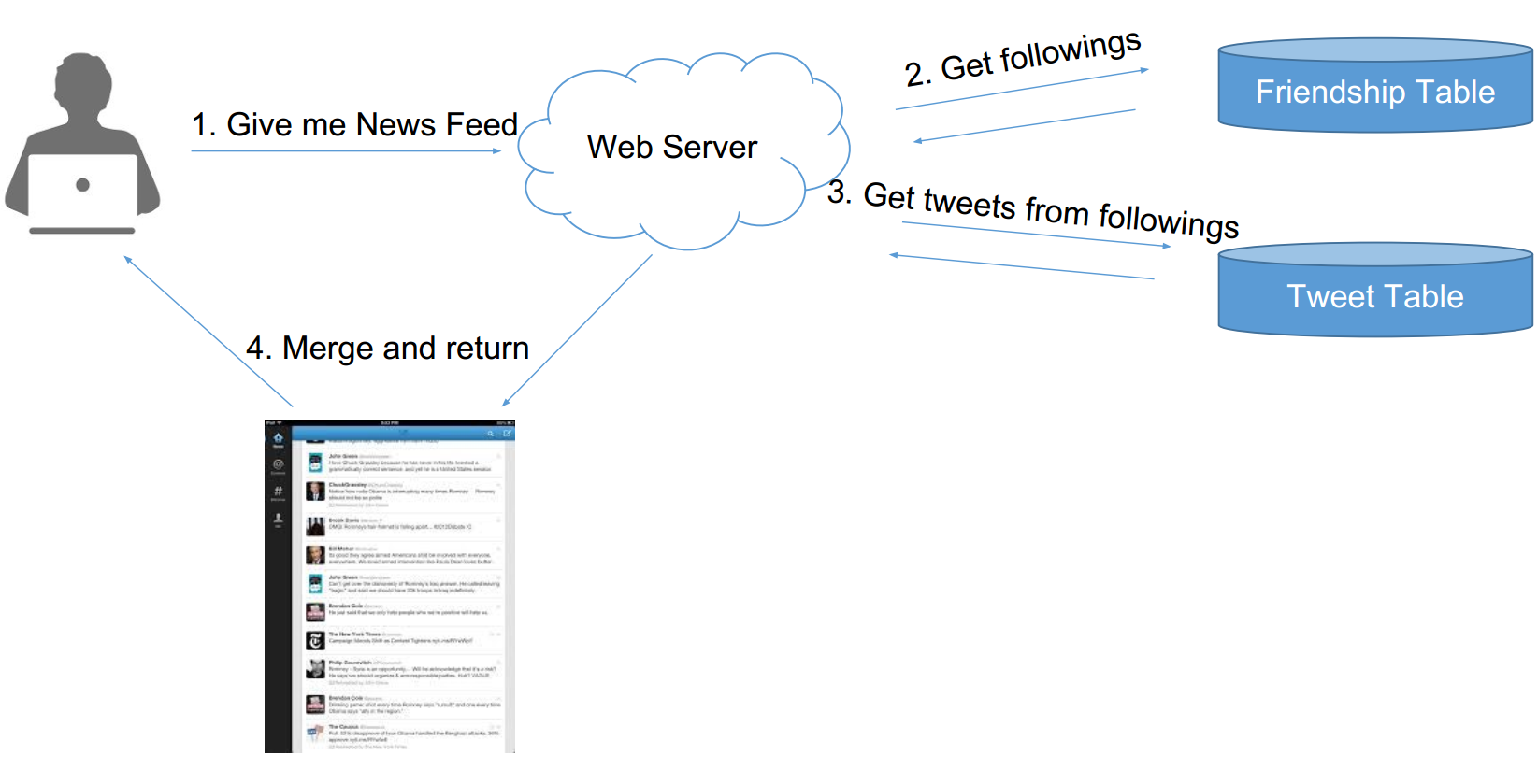
pull模型的缺陷:N次db reads太慢了,而且它发生在用户获得news feed的请求过程中,简直致命
Push模型 —— 被动模型
- 为用户建一个list,每个用户的好友发的tweets都在这个用户的list里。(叫做fanout)
- 用户想看时,只需要从该list里读取最新的100条即可
复杂度分析:
- News feed --> 1次db read
- post a tweet --> n个粉丝,需要n次db writes ,虽然没有read快,但是可以异步执行的
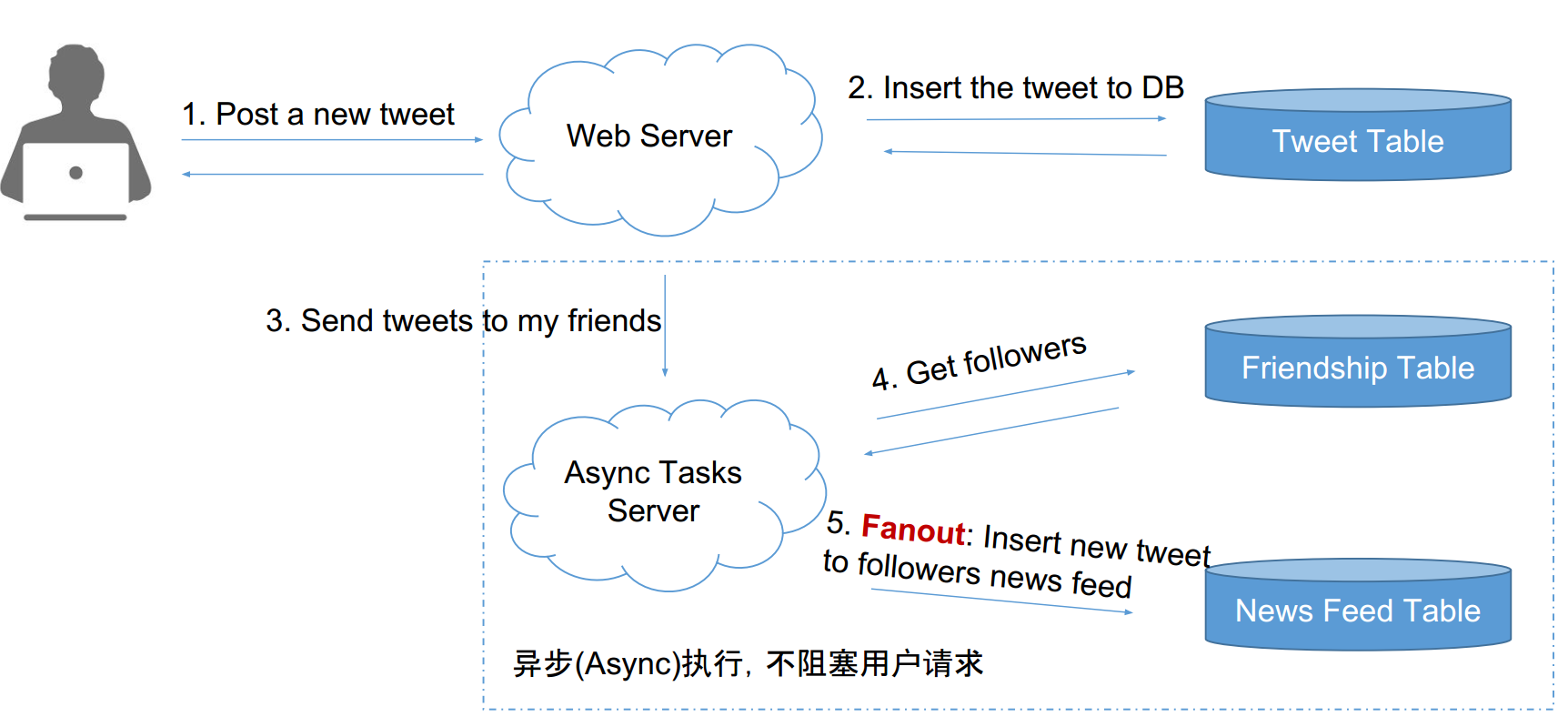
push模型的缺陷:不及时。明星的followers的数目可能很大,用户延迟慢的很。
Poll与Push的选择
考虑到僵尸粉与活跃用户,很多都是pull模型,为了及时。
热门Social App的模型 • Facebook – Pull • Instagram – Push + Pull • Twitter – Pull
误区 • 不坚定想法,摇摆不定 • 不能表现出Tradeoff的能力 • 无法解决特定的问题
扩展
第一步 Step 1: Optimize
- 解决设计缺陷
- Pull vs Push——Normalize vs De-normalize
- 更多功能设计 :Edit, Delete, Media, Ads
- 一些特殊用例 :Lady Gaga, Inactive Users
第二步 Step 2: Maintenance
- 鲁棒性 Robust:如果有一台服务器/数据库挂了怎么办
- 扩展性 Scalability:如果有流量暴增,如何扩展
解决pull的缺陷
最慢的部分发生在用户读请求时,那么可以:
- 在DB访问之前加入cache
- cache每个用户的timeline:
- N次DB请求 --> N次cache请求
- trade off : 可以考虑只考虑最近的1000条之类的
- cache每个用户的news feed
- 没有cache news feed的用户:归并N个用户最近的100条tweets,然后取出结果的前100条
- 有cache news feed的用户:归并N个用户在某个时间戳之后的所有tweets
解决push缺陷
- 浪费空间
- 但其实没啥
- 不活跃用户
- 粉丝排序。但也没啥作用
- 大量粉丝问题,无解。因此可以尝试在现有的模型下
进行优化。还可以对长期增长进行估计,并评估是否值得转化整个模型。
结合
Push 结合 Pull 的优化方案
- 普通的用户仍然 Push
- 将 Lady Gaga 这类的用户,标记为明星用户
- 对于明星用户,不 Push 到用户的 News Feed 中
- 当用户需要的时候,来明星用户的 Timeline 里取,并合并到 News Feed 里
摇摆问题
- 明星定义: followers > 1m
- 邓超掉粉: 邓超某天不停的发帖刷屏,于是大家果取关,一天掉了几十万粉,变成了非明星。
解决方法
- 明星用户发 Tweet 之后,依然继续 Push 他们的 Tweet 到所有用户的 News Feed 里
- 原来的代码完全不用改了
- 将关注对象中的明星用户的 Timeline 与自己的 News Feed 进行合并后展示
- 但并不存储进自己的 News Feed 列表,因为 Push 会来负责这个事情。
为什么既然大家都用Pull,我们仍然要学习Push?
- 系统设计不是选择一个最好的方案
- 而是选择一个最合适的方案
- 如果你没有很大的流量,Push是最经济最省力的做法
- 系统设计面试也并不是期望你答出最优的解决方法,而是从你的分析当中判断你对系统的理解和知识储备。
什么时候用 Push?
- 资源少
- 想偷懒,少写代码
- 实时性要求不高
- 用户发帖比较少
- 双向好友关系,没有明星问题(比如朋友圈)
什么时候用 Pull ?
- 资源充足
- 实时性要求高
- 用户发帖很多
- 单向好友关系,有明星问题