大纲
- Memcached
- 用户认证 - Authentication - 保持登录状态
- SQL vs NoSQL
- Friendship
- 如何扩展?
- Sharding
- Consistent Hashing
- Replica
Scenario 场景
- 注册、登录、查询、用户信息修改
- 哪个需求量最大?——查询
支持 100M DAU
注册,登录,信息修改 QPS 约
- 100M用户 * 0.1次每天 / 86400秒 ~ 100
- 0.1 = 平均每个用户每天登录+注册+信息修改
- 峰值Peak = 100 * 3 = 300
查询的QPS 约
- 100 M用户 * 100次每天 / 86400秒 ~ 100k次
- 100 = 平均每个用户每天与查询用户信息相关的操作次数(查看好友,发信息,更新消息主页)
- 峰值Peak = 100k * 3 = 300 k
Service 服务 —— 拆分子系统
- 一个 AuthService 负责登录注册
- 一个 UserService 负责用户信息存储与查询
- 一个 FriendshipService 负责好友关系存储
存储 QPS与数据库的关系
MySQL / PosgreSQL 等 SQL 数据库的性能 约 1k QPS 这个级别
MongoDB / Cassandra 等 硬盘型NoSQL 数据库的性能 约 10k QPS 这个级别
Redis / Memcached 等 内存型NoSQL 数据库的性能 100k ~ 1m QPS 这个级别
以上数据根据机器性能和硬盘数量及硬盘读写㏿度会有区别
思考:
注册,登录,信息修改,300 QPS,适合什么数据存储系统?
如果是MySQL / PosgreSQL —— 300台 如果是MongoDB / Cassandra —— 30台 如果是Redis / Memcached —— 3台 !但还是要根据数据库的基本信息选择
用户信息查询适合什么数据存储系统 ?
UserService 服务
用户信息存储与查询
用户系统特点:读非常多,写非常少。对于读多写少的系统,一定要使用Cache优化。
问题:爬虫系统是读多写少还是写多读少?——写多读少。给人用的,一般是读多写少。给机器用的,一般是读少写多。
Cache
- Cache 是什么?
- 缓存,把之后可能要查询的东西先存一下 下次要的时候,直接从这里拿,无需重新计算和存取数据库等
- 可以理解为一个 Java 中的 HashMap
- key-value 的结构
- 有哪些常用的 Cache 系统/软件?
- Memcached(不支持数据持久化)
- Redis(支持数据持久化)
- Cache 一定是存在内存中么?
- 不是
- Cache 这个概念,并没有指定存在什么样的存储介质中
- File System 也可以做Cache —— 相对于网络而言,比如访问本地硬盘比访问网络快。可以在本地做Cache
- CPU 也有 Cache
- Cache 一定指 Server Cache 么? 不是,Frontend / Client / Browser 也可能有客户端的 Cache
Memcached
Memcached是一款软件,但是内存型的,不在硬盘持久化。
使用例子:

ttl —— 这个key在这个cache中存储多少秒
如果不设置ttl,可能随时被删掉
常见缓存淘汰算法:LFU Cache, LRU Cache ,这两个算法很常见,要看看
见本站链接系统设计-缓存算法
Cache Aside模型
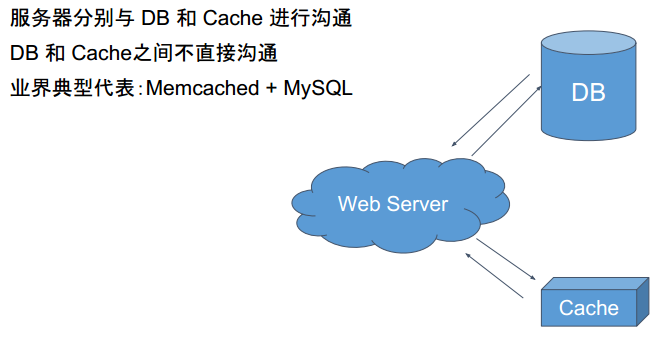
Memcached如何优化DB查询?
看下面两个代码!
- getUser 如果存在,就返回
- setUser 先要把cache里删掉!然后再写入db!

为什么要先删掉cache,然后写入DB呢?
1 | 1. 先setDB --> 后setCache |
AuthService 服务
- 用户是如何实现登陆与保持登陆的?
- 会话表 Session
- 用户 Login 以后
- 创建一个 session 对象
- 并把 session_key(全局唯一的) 作为 cookie 值返回给浏览器
- 浏览器将该值记录在浏览器的 cookie 中
- 用户每次向服务器发送的访问,都会自动带上该网站所有的 cookie
- 此时服务器检测到cookie中的session_key是有效的,就认为用户登陆了
- 用户 Logout 之后
- 从 session table 里删除对应数据
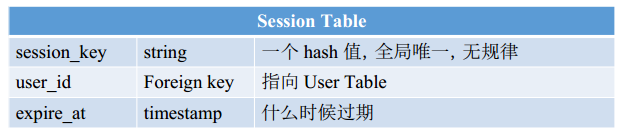
- 问题:Session Table 存在哪儿?
- A: 数据库
- B: 缓存 —— 方便些,但如果是大网站,一旦有个机器挂了,会有好多人同时登录。会gg,简直噩梦
- 正确打开方式:存在数据库里,如果访问过多,可以用Cache优化
小结
- 对于 User System 而言
- 写很少
- 读很多
- 写操作很少,意味着:从QPS的角度来说,一台 MySQL 就可以搞定了
- 读操作很多,意味着:可以使用 Memcached 进行读操作优化
- 进一步的问题,如果读写操作都很多,怎么办?
- 方法一:使用更多的数据库服务器分摊流量
- 方法二:使用像 Redis 这样的读写操作都很快的 Cache-through 型 Database Memcached 是一个 Cache-aside 型的 Database,Client 需要自己负责管理 Cache-miss 时数据的 loading
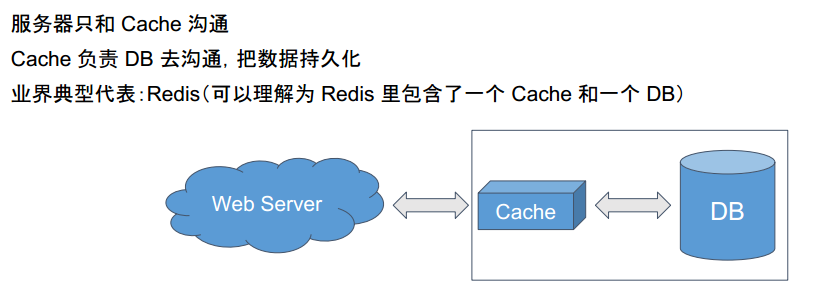
Redis介绍
是一种Cache-through型,就是把cache和db进行了打包。不像Memcached那样,cache与db是分开的(Cache Aside),需要自己实现查询的逻辑。
而Redis是一种打包了的,DB与Cache是一起的。也就是Cache-through,如下图;
FriendshipService服务
- 单向好友关系:微博

- 双向好友关系:微信
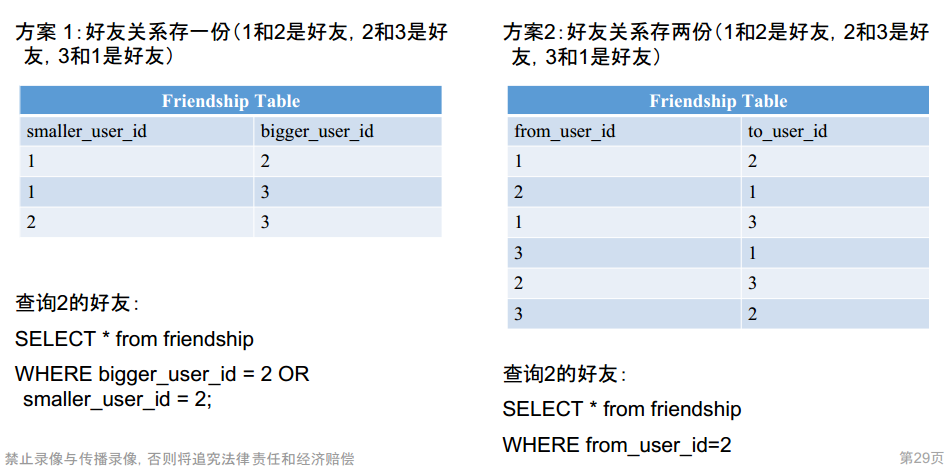
- 方案1:存为两条信息,A关注了B,B关注了A
- 方案2:存为一条信息(单向边认为是双向边,但查询前需要排序),但查询的时候需要查两次
- 好友关系所涉及的操作非常简单,基本都是 key-value:
- 求某个 user 的所有关注对象
- 求某个 user 的所有粉丝
- A 关注 B → 插入一条数据
- A 取关 B → 删除一条数据
数据库的比较和选择
问题:好友关系如何选择数据库?
- 大部分情况,用SQL或者NoSQL都行。
- 需要支持Transaction(交易)的话不能选NoSQL 交易双方必须同时成功、同时失败!
- 一般SQL更成熟,而NoSQL很多事情都要亲自写(value需要自己序列化、多级索引也要自己写)
- 如果想省服务器获得更高性能,NoSQL更好。硬盘型的NoSQL要比SQL快很多很多。
SQL与NoSQL存储方式
SQL
SQL的列一般是指定好的,不可以随意添加。
一条数据一般以row为单位(取出整个row作为一条数据)

NoSQL
NoSQL的列是动态的,无限大,可以随意添加。
一条数据一般以“格子”为单位,row_key + column_key1-value1 + column_key2-value2 + ...
比如row_key是user_id,其它的都是一些属性。

只需要提前定义好column_key本身的形式(是一个int还是一个int+str)
如果存在SQL里

查询好友关系时,对于指定user_id,只需要
1 | select bigger_user_id from friendship where smaller_user_id = $user_id |
具体地说,例如(1和2是好友,2和3是好友,3和1是好友)
- 好友关系存一份
查询2的好友:
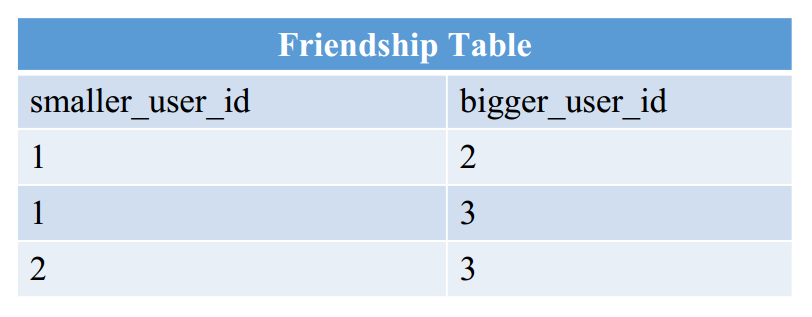
1 | SELECT * from friendship |
- 好友关系存两份
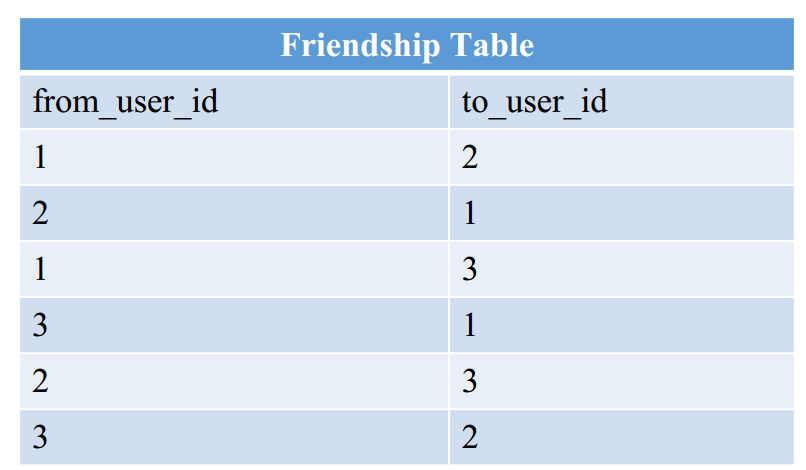
1 | SELECT * from friendship |
如果存在NoSQL
而如果存在nosql,所以需要拆分为两条数据:
1 | A的好友有B: key=A, value=B |
以Cassandra为例(这是一道题,回去做做)
- Cassandra 是一个三层结构的 NoSQL 数据库 http://www.lintcode.com/problem/mini-cassandra/
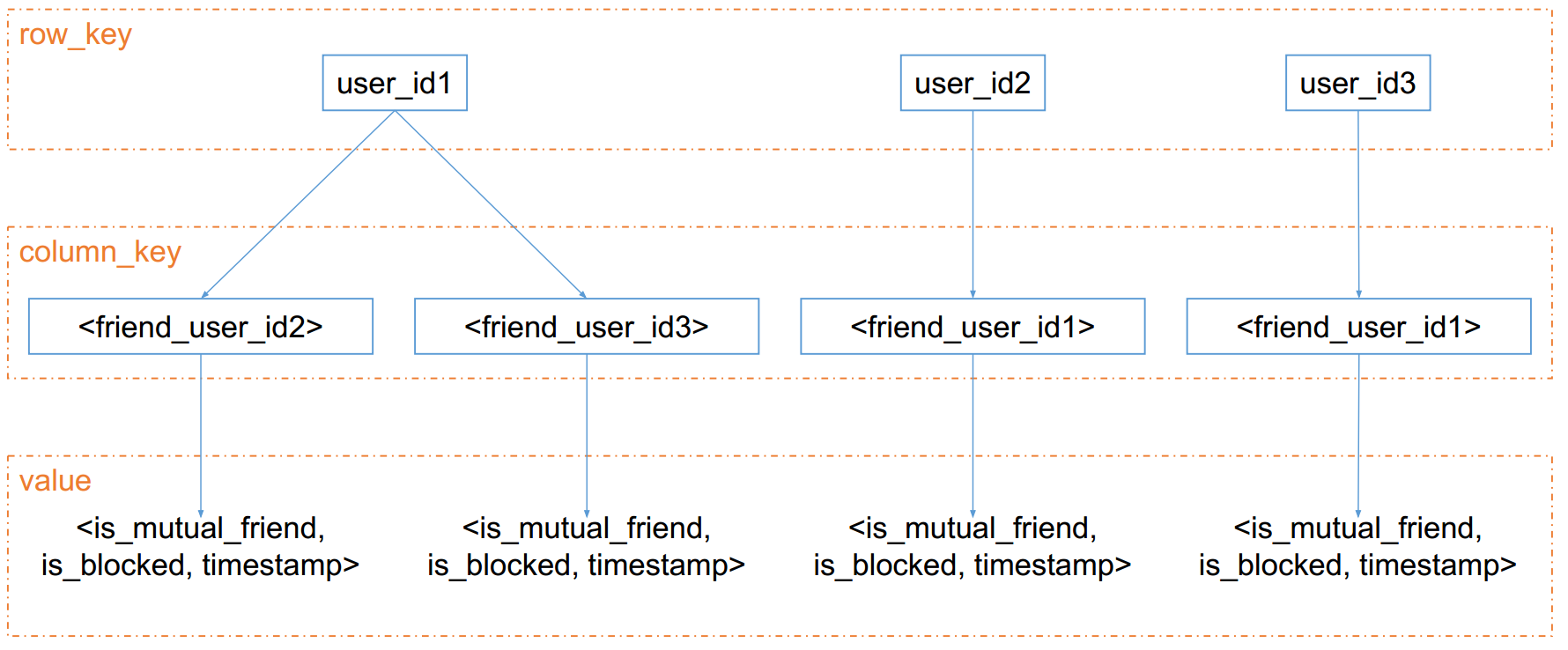
- 第一层:row_key
- 又称为 hash_key
- 也就是我们传统所说的 key-value 中的 那个key
- 任何的查询都需要带上这个key,无法进行range query
- 最常用的row_key: user_id
- 第二层:column_key
- 是排序的,可以进行range query
- 可以是复合值,比如是一个 timestamp + user_id 的组合
- 第三层:value
- 一般来说是 String
- 如果你需要存很多的信息的话,你可以自己做 Serialization 什么是 Serialization: 把一个 object / hash 序列化为一个 string,比如把一棵二叉树序列化
- http://www.lintcode.com/problem/binary-tree-serialization/
- 第一层:row_key
如果把friendShip放在Cassandra里,怎么放?
1 | row_key ------ user id |
如下图所示:
# 系统如何扩展?
100M 的用户存在一台 MySQL 数据库里也存得下,Storage没问题。通过 Cache 优化读操作后,只有 300QPS 的写,QPS也没问题。
除了QPS,还需要考虑什么?
单点失效问题
- 数据拆分 Sharding / Hashkey
- 按照一定的规则,将数据拆分成不同的部分,保存在不同的机器上
- 这样就算挂也不会导致网站 100% 不可用
- 数据备份 Replica
- 通常的做法是一式三份(重要的事情“写”三遍)
- Replica 同时还能分摊读请
Cassandra为例的NoSQL自带Sharding!
SQL不带Sharding,要程序员自己写
数据拆分
纵向切分:
不同的表放在不同的数据库,或者按照使用频率将不同列放在不同的数据库。比如UserName这些不怎么访问,可以放在一个数据库。而推送什么的可以放在另一个数据库。
缺点:万一某张表特别大,比如有70亿用户?还是有单点失效问题。
横向切分
一个表放在多个机器里。各放一份。比如有10台机器,数据按照n%10存储。
问题:加入现在新加了一台,那么每条数据都要按照n%11进行重新存放。过多数据迁移会造成很多问题:
- 慢,牵一发动全身
- 迁移期间,服务器压力增大,容易挂
- 响应慢
- 容易造成数据的不一致性
以下图为例,左图对每个数据%3,那么0369就在一个db里,14610在一个db,25811在一个db
右图对每个数据%4,那么048在一个db,159在一个db,2610在一个db,3711在一个db
橘黄色表示已经挪动的数据,我们发现75%的数据有了移动。简直灾难。
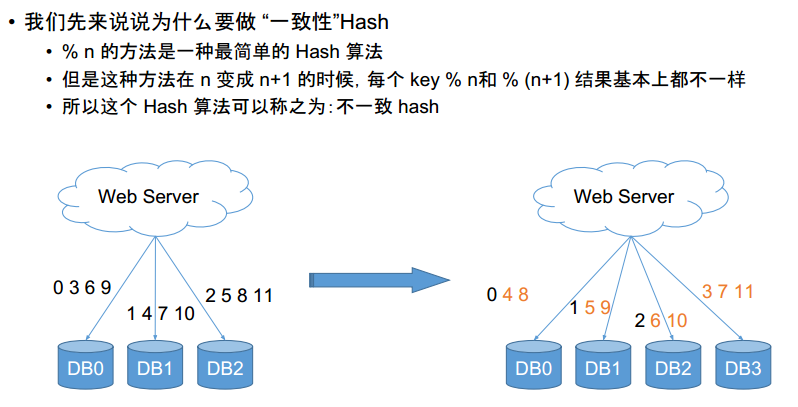
解决——一致性哈希算法:
- 取模的时候不要模机器数目,可以模一个很大的数字,比如360。每个机器负责一段区间
- 区间分配信息记录为一张表存在 Web Server 上。如下左图,如果模出来的在180359,就放在DB1,如果模出来在0179,就放在DB0。
- 新加一台机器的时候,在表中选择一个位置插入,匀走相邻两台机器的一部分数据。
- 比如 n 从 2 变化到 3,只有 1/3 的数据移动

继续思考,假如我们现在已经是这样了:
其中ABC各用了120
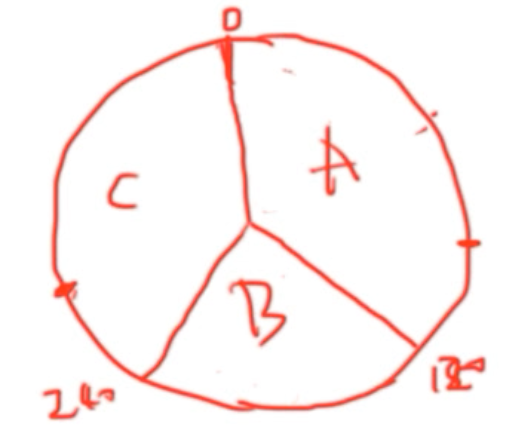
如果我们又来了个新机器D,那么可以有以下几种方案:
那么我们可以找两台相邻的机器,然后把中间的一块分给D:
那么迁移量 = 80/360 = 2/9
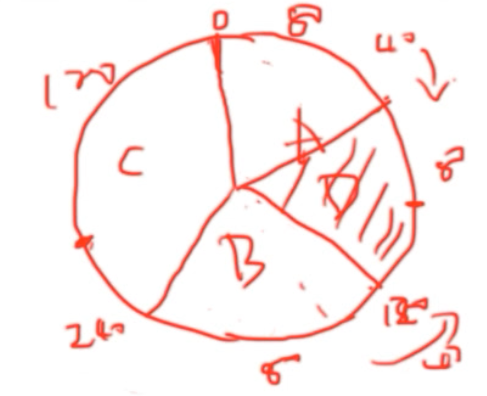
整理一下就是:
以上说的是D一定是连续区间。但是有问题:
- 数据分布不均匀
- 迁移压力大。例如有100台机器,这次添加一台机器,只能分摊两台
一致性Hash
改进
那么如果D搞成离散区间呢?就是ABC各拿出一些给D:
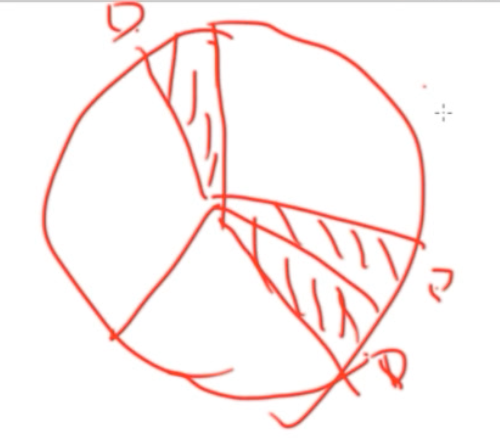
巧妙的方法:
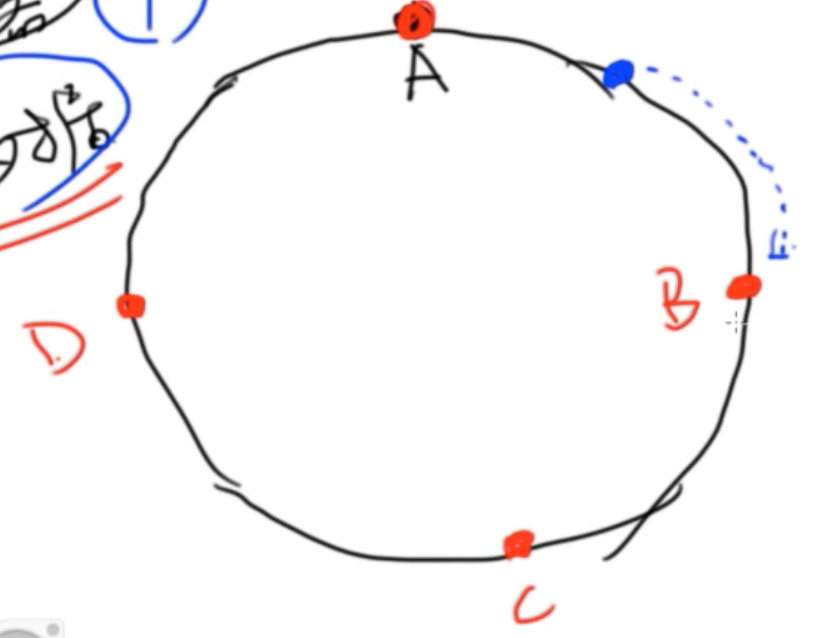
将机器(IP或者名字)与数据,都看做环上的一个点!!
- 将机器映射到环上,如下图所示的ABCD是四个机器

- 比如有个数据,蓝色的点,散在了蓝色点出。那么就顺时针去找一个机器,把这个数据放在这个机器上,即B
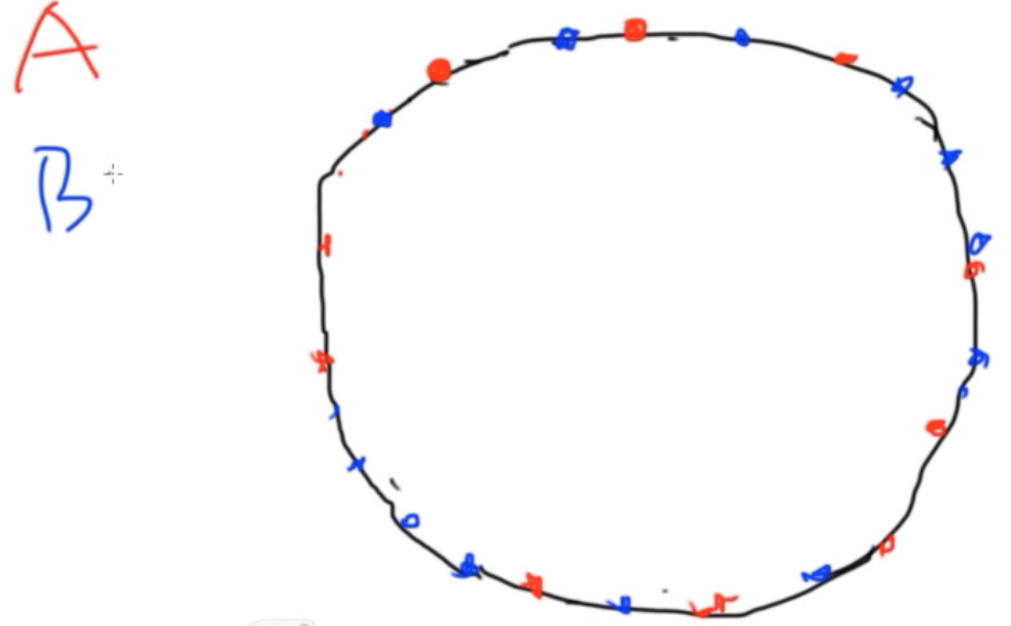
- 那么如何让点更均匀呢? 四个点可能不会均匀,但是4000个点相对来说一定会更均匀。那就引入Micro shards / Virtual nodes 的概念——一台机器对应了1000个代表。例如将A机器撒在环上(下图红色),将B机器撒在环上(下图蓝色)
 来了一个数据时, 例如图中的黑色点Data,那么就找到了机器B
来了一个数据时, 例如图中的黑色点Data,那么就找到了机器B 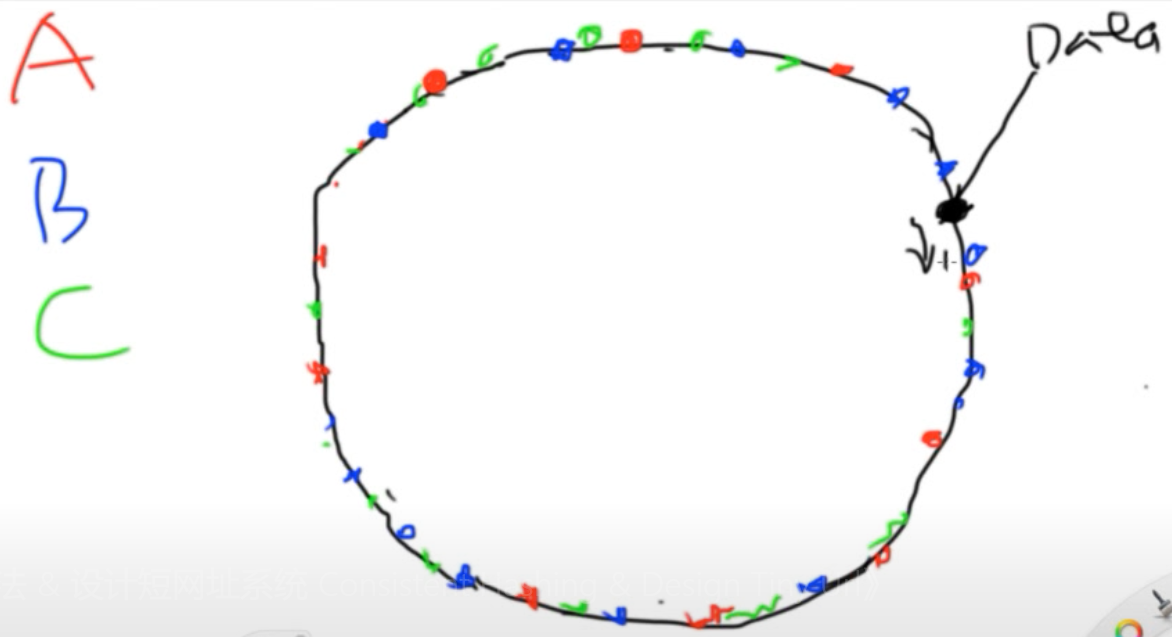
- 也就是意味着,每个机器负责了很多个离散的区间。
- 当需要加入一台新机器时?加入我们现在机器分布是这样:
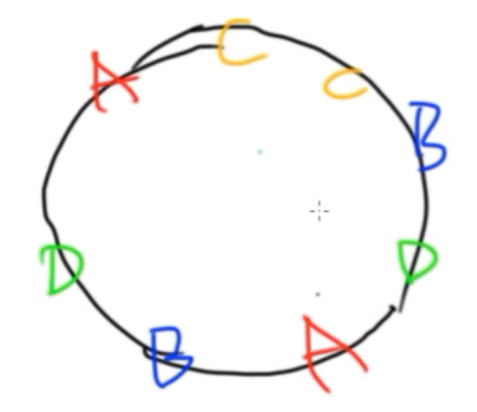 新来了一个E的机器,丢到环里之后
新来了一个E的机器,丢到环里之后 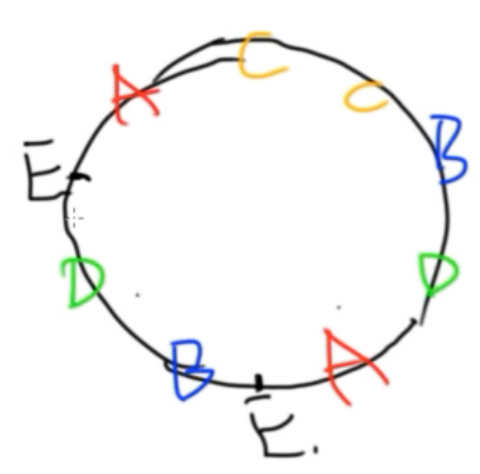 [D,E]之间的数据必须从A迁移到E上!!!![A,E]之间的数据必须从B迁移到E上
[D,E]之间的数据必须从A迁移到E上!!!![A,E]之间的数据必须从B迁移到E上
总结:
- 将整个 Hash 区间看做环。 这个环的大小从 0~359 变为 \(0 到 2^{64}-1\) (这个数字可以承载所有的数据)
- 将机器和数据都看做环上的点(例如对机器名字进行hash等等)
- 引入 Micro shards / Virtual nodes 的概念
- 一台实体机器对应 1000 个 Micro shards / Virtual nodes,每个 virtual node 对应 Hash 环上的一个点。每新加入一台机器,就在环上随机撒 1000 个点作为 virtual nodes
- 需要计算某个 key 所在服务器时,计算该key的hash值——得到0~264-1的一个数,对应环上一个点
- 顺时针找到第一个virtual node,该virtual node 所在机器就是该key所在的数据库服务器
- 新加入一台机器做数据迁移时
- 1000 个 virtual nodes 各自向顺时针的一个 virtual node 要数据
- 例子:http://www.jiuzhang.com/qa/2067/
问题1:需要存储数据在环的哪里吗? 不需要。因为这个数据在哪里与其它数据在哪里没有关系。只需要在环上计算数据所在的点的下一个位置的机器是哪个即可。
问题:那这个1000能变成100万吗? 太多也不行。查询效率会变低。就是在比较均匀的情况下选一个比较快的就行。
思考:哪种数据结构能够支持这种“顺时针”寻找下一个机器的功能呢?——链表是不行的,因为链表长度太大。用TreeMap!! 就是一个红黑树,能在LogN的时间内寻找比n大的最小值。
回头看一下Consistent Hashing这道题
Consistent Hashing
参考文献LintCode Consistent Hashing(一致性哈希算法)
一般的数据库进行horizontal shard的方法是指,把 id 对 数据库服务器总数 n 取模,然后来得到他在哪台机器上。这种方法的缺点是,当数据继续增加,我们需要增加数据库服务器,将 n 变为 n+1 时,几乎所有的数据都要移动,这就造成了不 consistent。为了减少这种 naive 的 hash方法(%n) 带来的缺陷,出现了一种新的hash算法:一致性哈希的算法——Consistent Hashing。这种算法有很多种实现方式,这里我们来实现一种简单的 Consistent Hashing。
- 将 id 对 360 取模,假如一开始有3台机器,那么让3台机器分别负责0~119, 120~239, 240~359 的三个部分。那么模出来是多少,查一下在哪个区间,就去哪台机器。
- 当机器从 n 台变为 n+1 台了以后,我们从n个区间中,找到最大的一个区间,然后一分为二,把一半给第n+1台机器。
- 比如从3台变4台的时候,我们找到了第3个区间0119是当前最大的一个区间,那么我们把0119分为059和60119两个部分。059仍然给第1台机器,60119给第4台机器。
- 然后接着从4台变5台,我们找到最大的区间是第3个区间120~239,一分为二之后,变为 120~179, 180~239。
假设一开始所有的数据都在一台机器上,请问加到第 n 台机器的时候,区间的分布情况和对应的机器编号分别是多少?
Notice
你可以假设 n <= 360. 同时我们约定,当最大区间出现多个时,我们拆分编号较小的那台机器。 比如0~119, 120~239区间的大小都是120,但是前一台机器的编号是1,后一台机器的编号是2, 所以我们拆分0~119这个区间。
Clarification
If the maximal interval is [x, y], and it belongs to machine id z, when you add a new machine with id n, you should divide [x, y, z] into two intervals:
[x, (x + y) / 2, z] and [(x + y) / 2 + 1, y, n]
Example
for n = 1, return
1 | [ |
represent 0~359 belongs to machine 1.
for n = 2, return
1 | [ |
for n = 3, return
1 | [ |
for n = 4, return
1 | [ |
for n = 5, return
1 | [ |
方法:使用堆来维护当前最大的区间,然后分割它。
1 | public class Solution { |
Consistent Hashing II
在 Consistent Hashing I 中我们介绍了一个比较简单的一致性哈希算法,这个简单的版本有两个缺陷:
- 增加一台机器之后,数据全部从其中一台机器过来,这一台机器的读负载过大,对正常的服务会造成影响。
- 当增加到3台机器的时候,每台服务器的负载量不均衡,为1:1:2。
为了解决这个问题,引入了 micro-shards 的概念,一个更好的算法是这样:
- 将 360° 的区间分得更细。从 0~359 变为一个 0 ~ n-1 的区间,将这个区间首尾相接,连成一个圆。
- 当加入一台新的机器的时候,随机选择在圆周中撒 k 个点,代表这台机器的 k 个 micro-shards。
- 每个数据在圆周上也对应一个点,这个点通过一个 hash function 来计算。
- 一个数据该属于那台机器负责管理,是按照该数据对应的圆周上的点在圆上顺时针碰到的第一个 micro-shard 点所属的机器来决定。
n 和 k在真实的 NoSQL 数据库中一般是 2^64 和 1000。
请实现这种引入了 micro-shard 的 consistent hashing 的方法。主要实现如下的三个函数:
- create(int n, int k)
- addMachine(int machine_id) // add a new machine, return a list of shard ids.
- getMachineIdByHashCode(int hashcode) // return machine id
Notice
当 n 为 2^64 时,在这个区间内随机基本不会出现重复。 但是为了方便测试您程序的正确性,n 在数据中可能会比较小,所以你必须保证你生成的 k 个随机数不会出现重复。 LintCode并不会判断你addMachine的返回结果的正确性(因为是随机数),只会根据您返回的addMachine的结果判断你getMachineIdByHashCode结果的正确性。
Example
1 | create(100, 3) |
思路:使用TreeMap
1 | public class Solution { |
Replica 数据备份
问题:Backup和Replica有什么区别?
Backup
- 一般是周期性的,比如每天晚上进行一次备份
- 当数据丢失的时候,通常只能恢复到之前的某个时间点
- Backup 的数据是死数据,是离线的。不用作在线的数据服务,不分摊读
Replica
- 是实时的, 在数据写入的时候,就会以复制品的形式存为多份
- 当数据丢失的时候,可以马上通过其他的复制品恢复
- Replica是实时的。 用作在线的数据服务,分摊读
思考:既然 Replica 更牛,那么还需要 Backup么?
MySQL Replica
以MySQL为代表的的SQL型数据库,通常自带Master Slave的Replica方法。Master负责写,Slave负责读。Slave从Master中同步数据。
Master - slave原理
SQL数据库的任何操作,都会以Log的形式做一份记录。
比如Master上的数据A在B时刻从C改成了D,那么Master会通知Slave来读Log(不是同步值,而是同步操作!)。Slave被激活后,告诉master我可以更新了。
因此Slave上的数据是有延迟的。
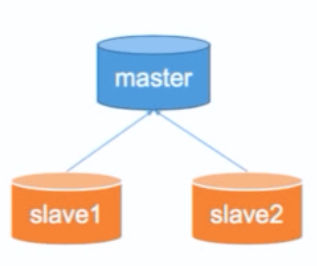
问题:万一Master挂了怎么办?
- 将一台slave升级为master, 接受读 + 写
- 可能会造成一定程度的数据丢失和不一致
NoSQL Replica
以Cassandra为代表的的NoSQL数据库,通常将数据“顺时针”存储在Consistent hashing环上的三个vitual nodes中。
比较
SQL
- “自带” 的 Replica 方式是 Master Slave
- “手动” 的 Replica 方式也可以在 Consistent Hashing 环上顺时针存三份
NoSQL
- “自带” 的 Replica 方式就是 Consistent Hashing 环上顺时针存三份
- “手动” 的 Replica 方式:就不需要手动了,NoSQL就是在 Sharding 和 Replica 上帮你偷懒用的!