例如goo.gl
系统设计常见误区
以下几个是误区
- 系统一定巨大无比 —— ×
- 必须用NoSQL —— ×
- 必须是分布式 —— ×
不可以扔关键词,必须一步步分析。
4S分析法
- 提问:分析功能/需求/QPS/存储容量——Scenario
- 画图:根据分析结果设计“可行解”—— Service+Storage
- 进化:研究可能遇到的问题,优化系统 —— Scale
分析需求
需求有两个:
- 根据长URL生成短URL

- 根据短URL还原长URL

QPS?
假设这个是用来给微博做短网址的跳转。那么QPS能有多少?
- 询问微博日活用户 —— 约100M
- 推算产生一条Tiny URL的QPS
- 假设每个用户平均每天发0.1条微博,
- 平均写QPS = 100M * 0.1 / 86400 ~ 100
- 峰值QPS = 100 * 2 = 200
- 推算点击一条Tiny URL的QPS
- 假设每个用户平均点1个Tiny URL
- 平均读QPS = 100M * 1 / 86400 ~ 1k
- 峰值QPS = 2k
- 推算每天产生的新的 URL 所占存储
- 100M * 0.1 ~ 10M 条
- 每一条 URL 长度平均 100 算,一共1G
- 1T 的硬盘可以用 3 年
前3点:2k QPS ,一台SSD支持的MySQL完全可以搞定!
服务——逻辑块聚类与接口设计
TinyUrl只有一个UrlService
- 本身就是一个小Application
- 无需关心其他的
函数设计
UrlService.encode(long_url)UrlService.decode(short_url)
访问端口设计
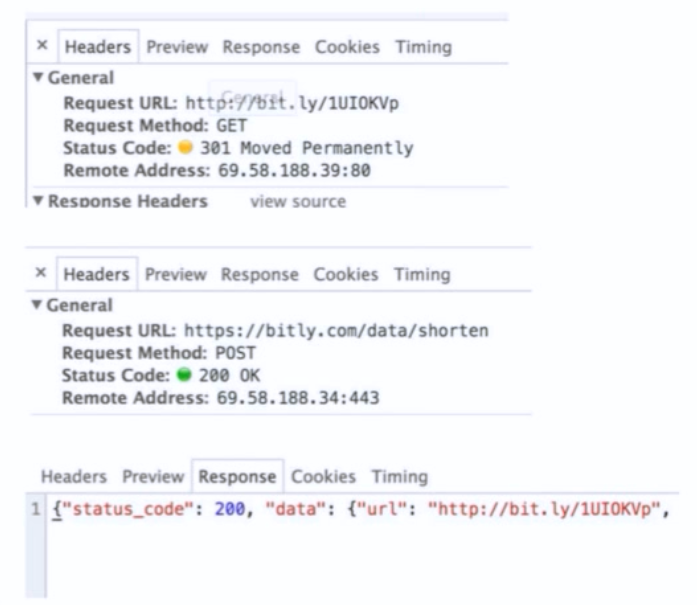
GET /<short_url>return a Http redirect response
POST /data/shorten/Data = {url: http://xxxx }Return short url
数据存取
两个步骤:
- 选择存储结构
- 细化数据表
选择存储结构
SQL vs NoSQL
- 是否需要支持 Transaction(事务)?
- NoSQL不支持Transaction
- 是否需要丰富的 SQL Query?
- NoSQL的SQL Query不是太丰富
- 也有一些NoSQL的数据库提供简单的SQL Query支持
- 是否想偷懒?
- 大多数 Web Framework 与 SQL 数据库兼容得很好
- 用SQL比用NoSQL少写很多代码
- 是否需要Sequential ID?
- SQL 为你提供了 auto-increment 的 Sequential ID。也就是1,2,3,4,5 …
- NoSQL的ID并不是 Sequential 的
- 对QPS的要求有多高?
- NoSQL 的性能更高
- 对Scalability的要求有多高?
- SQL 需要码农自己写代码来 Scale
- 还记得Db那节课中怎么做 Sharding,Replica 的么?
- NoSQL 这些都帮你做了
选择
- 是否需要支持 Transaction?——不需要。NoSQL +1
- 是否需要丰富的 SQL Query?——不需要。NoSQL +1
- 是否想偷懒?——Tiny URL 需要写的代码并不复杂。NoSQL+1
- 对QPS的要求有多高?—— 经计算,2k QPS并不高,而且2k读可以用Cache,写很少。SQL +1
- 对Scalability的要求有多高?—— 存储和QPS要求都不高,单机都可以搞定。SQL+1
- 是否需要Sequential ID?—— 取决于你的算法是什么 : 如何将Long URL 转化为 Short URL
如何将Long URL 转化为 Short URL
算法1 使用哈希函数 Hash Function(不可行)
比如取 Long Url 的 MD5 的最后 6 位——这个方法肯定是有问题的 • 优点:快 • 缺点:难以设计一个没有冲突的哈希算法
算法2:随机生成 + 数据库去重
随机一个 6 位的 ShortURL,如果没有被用过,就绑定到该 LongURL • 伪代码如下:  • 优点:实现简单 • 缺点:生成短网址的长度随着短网址越来越多变得越来越慢 • 可行性:其实能凑合用。在生活中有很多随机编码的,例如机票码、酒店码,是不可重复的,就是用这种方法弄的。
• 优点:实现简单 • 缺点:生成短网址的长度随着短网址越来越多变得越来越慢 • 可行性:其实能凑合用。在生活中有很多随机编码的,例如机票码、酒店码,是不可重复的,就是用这种方法弄的。
算法3:进制转换 Base62
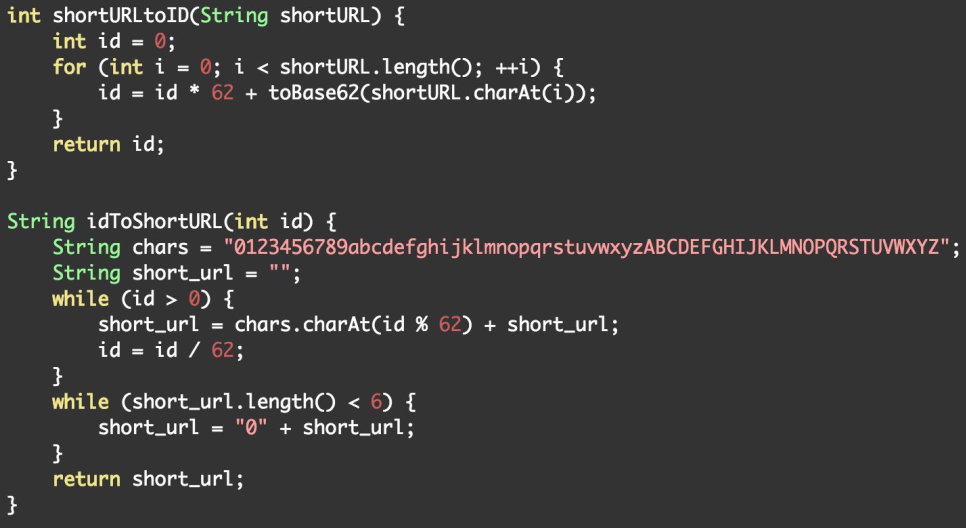
- Base62
- 将6位的short url看成一个62进制的数(0-9,a-z,A-Z)
- 每个short url对应到一个整数
- 该整数对应数据库表的主键——Sequential ID
- 6位可以表示不同的URL有多少?
- 5位 = \(62^5\) = 9亿
- 6位 = \(62^6\) = 570亿
- 7位 = \(62^7\) = 35000亿
- 优缺点
- 优点:效率高
- 缺点:依赖于全局的自增ID
算法2与3的比较
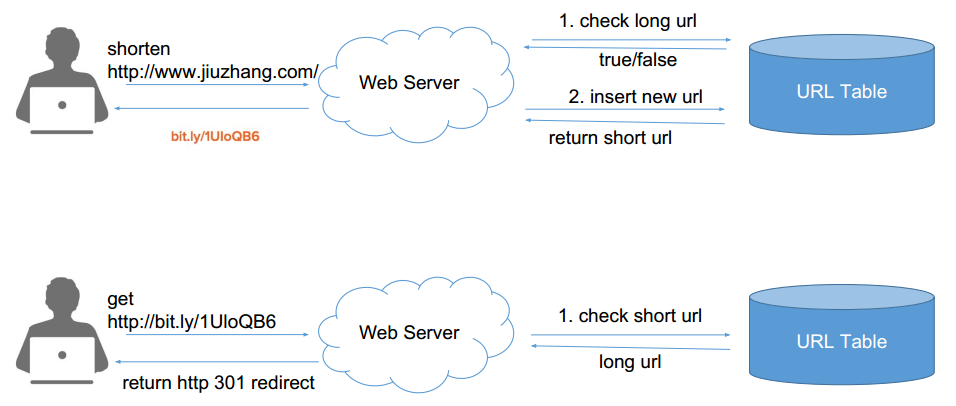
- 基于随机生成的方法 需要根据 Long 查询 Short,也需要根据 Short 查询 Long。基本上work solution如下图所示:
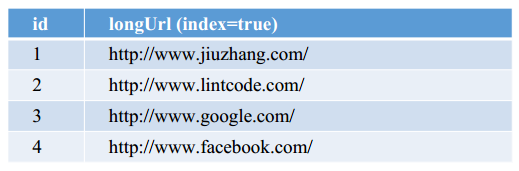
 如果选择用 SQL 型数据库,表结构如下:
如果选择用 SQL 型数据库,表结构如下: 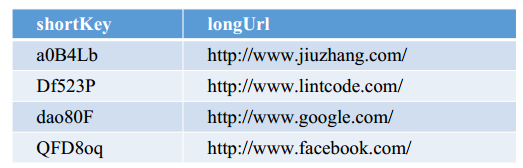 并且需要对shortKey和longURL分别建索引 • 什么是索引? • 索引的原理? 也可以选用 NoSQL 数据库,但是需要建立两张表(大多数NoSQL数据库不支持二级索引)。以 Cassandra 为例子 第一张表:根据 Long 查询 Short row_key=longURL, column_key=ShortURL, value=null or timestamp 第二张表:根据 Short 查询 Long row_key=shortURL, column_key=LongURL, value=null or timestamp
并且需要对shortKey和longURL分别建索引 • 什么是索引? • 索引的原理? 也可以选用 NoSQL 数据库,但是需要建立两张表(大多数NoSQL数据库不支持二级索引)。以 Cassandra 为例子 第一张表:根据 Long 查询 Short row_key=longURL, column_key=ShortURL, value=null or timestamp 第二张表:根据 Short 查询 Long row_key=shortURL, column_key=LongURL, value=null or timestamp - 基于进制转换的方法 因为需要用到自增ID(Sequential ID),因此只能选择使用 SQL 型数据库。表单结构如下,shortURL 可以不存储在表单里,因为可以根据 id 来进行换算
优化
读操作的优化
既然读操作比较多,那么可以用cache的方式去提速。
- cache里存什么?
- long to short(生成新short url时需要)
- short to long(查询short url时需要)
- 查询的流程图:

如何提速
- 利用地理位置信息加速
- 优化服务器速度
- 不同地区,使用不同Web服务器
- 通过DNS解析不同地区的用户到不同的服务器
- 优化数据访问速度
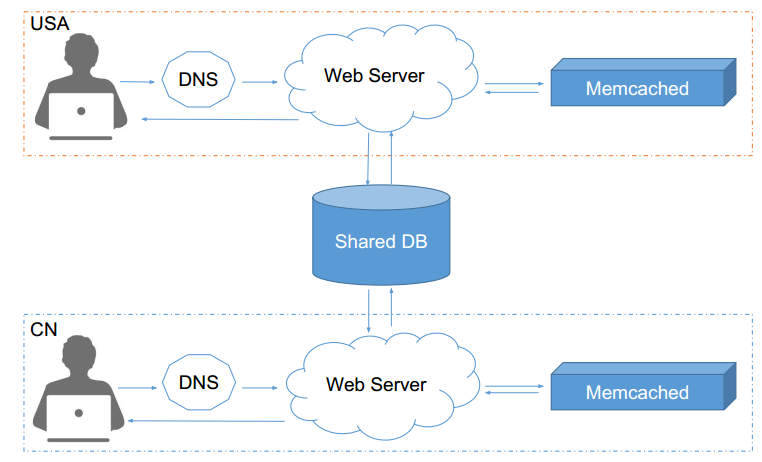
- 使用Centralized MySQL + Distributed Memcached
- 一个MySQL配多个Memcached, Memcached跨地区分布
如何扩展机器
什么时候需要多台服务器?
- Cache资源不够
- 写操作越来越多
- 请求太多,无法通过Cache满足
增加多台数据库可以优化什么?
- 解决存不下的问题——Storage角度(TinyURL一般遇不到这种问题)
- 解决忙不过来的问题——QPS角度
- TinyURL主要是什么问题??——忙不过来的问题
如何解决忙不过来的问题?
拆分 :
- 纵向切分?不同列放不同数据库?不可行!
- 横向拆分?一个表放多个机器? 就将不同的short key放到不同的机器上,能解决short 2 long问题。但此时如果要解决long 2 short问题,就不好搞了。可能需要遍历每一个机器。但是回过来问,long 2 short这个问题的意义是什么。没有必要根据long查询short哇。一个long可以对应多个short,因此没必要一个long对应一个short。
如果最开始shortkey为6位,那就增加一位前置位:
- AB1234 --> 0AB1234(该前置位由hash(long_url)%62得到(可以用consistent hash算法),因此是唯一的。这个前置位可以作为机器的ID等)
- 另一种做法,把第一位单独留出来做sharding key,总共还是6位
那么当前的架构就变成了:

还有优化的地方吗
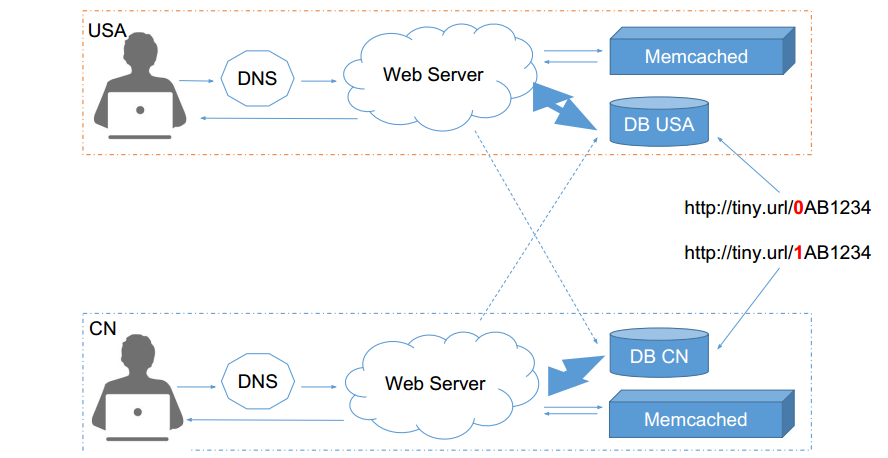
网站服务器 (Web Server) 与 数据库服务器 (Database) 之间的通信问题。
中心化的服务器集群(Centralized DB set)与 跨地域的 Web Server 之间通信较慢。比如中国的服务器需要访问美国的数据库那么何不让中国的服务器访问中国的数据库?
如果数据是重复写到中国的数据库,那么如何解决一致性问题?——很难解决
中国的用户访问时,会被DNS分配中国的服务器,这非常的慢。
而中国的用户访问的网站一般都是中国的网站,所以我们可以按照网站的地域信息进行 Sharding。(如何获得网站的地域信息?只需要将用户比较常访问的网站弄一张表就好了)
中国的用户访问美国的网站怎么办?那就让中国的服务器访问美国的数据好了,反正也不会慢多少。中国访问中国是主流需求,优化系统就是要优化主要的需求
能不能提供个性化的URL?
就是把后面的短url个性化。可以的,只要与其它short不重复就行了。如下所示:
1 | shortURL longURL |
但最好不要新开一列custom。因为这样很浪费空间。