本文回顾并总结了编程之美搜索引擎端的相关原理
爬虫
北邮人论坛格式相对工整,并不需要进行DFS爬取。论坛某个页面如下:
论坛格式基本如下:
1 | 1 [标题,最新回复时刻] |
因此只需要按页遍历即可。
数据库设计
爬取的内容建立一张表放入MySQL。由于每个帖子都有自己的唯一性ID,因此可以将这个ID作为主键。
| 文章ID(主键) | 标题(已分词) | 更新时刻 | 内容(已分词) | 链接 | 已索引 |
|---|---|---|---|---|---|
| 758943 | 社招/神马/搜索/北京/资深/广告/算法/研发/工程师 | 20180302 165751 | 基于/大规模/用户/行为/效果/目标/建立/优化/推荐/系统/基础/算法/策略 .... | https://bbs.byr.cn/#!article/JobInfo/758943 | 是/否 |
| ... | ... | ... |
实时爬虫
由于北邮人论坛的【缘分天空】、【毕业生找工作】、【兼职实习信息】等板块很热火,几乎每小时都有新帖。因此可以不考虑资源浪费问题,直接采用定时爬虫进行信息更新和维护。
实时爬虫的流程如下:
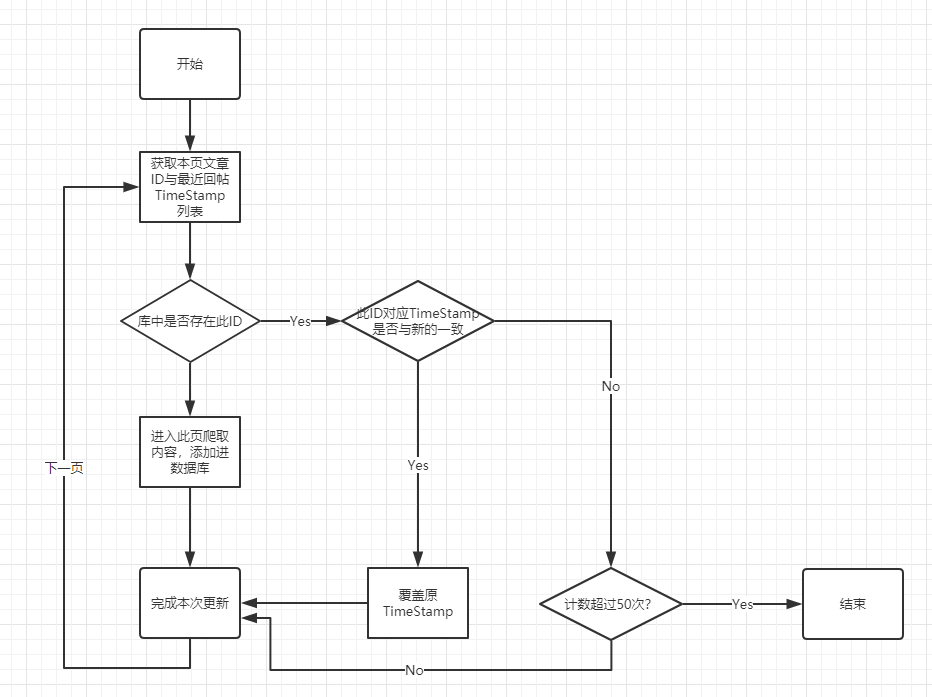
对于每个页面,我们可以从页面目录快速获取【文章ID、标题、发帖时刻、回复量、最新回复时刻、文章链接】信息。因此当获取到本页面的10篇文章的ID和最新回复时刻TimeStamp后:
看库中是否存在此ID
如果存在:
此帖在近期有回复,更新最新回复时刻TimeStamp
此帖在近期无回复,有两种可能:
- 后面的帖子不再有新的回复,因此可以直接停止本版面的爬虫;
- 爬取第1页时,本帖在第1页;爬取第2页时,本帖被顶到第2页;
为了不让情况2误认为是近期无更新的贴,因此我们设置50次阈值。当连续50篇文章都没有新的更新时,停止爬虫。
如果不存在,则爬取本页面并添加进数据库
对于每个版块的每个页面,执行以上循环操作。每个页面包含10篇左右文章。由于每篇文章打开需要约1秒,因此一页需要10多秒。北邮人论坛设置反爬虫机制,每连续访问10次后就要休息10秒才可以继续爬。而【毕业生找工作】等热门版面每日的更新量达300+条。那么完成一次此版面的爬取需要10分钟。三个版面的爬取大约需要20分钟。这个时间太长了,不利于后续的实施构建索引。
为了加速爬取速度,我们采用了多线程爬取技术。为了避免重复写入,因此每个线程只负责一个页面。当爬取完毕时,将数据扔到“待写入队列”里排队写入MySQL。
检索
原理
分词、建倒排索引
后记:看看分词原理
对于标记为“未索引”的文章,利用jieba分词模块,首先按是否为汉字、数字、英文字符及标点符号对新闻内容进行梳理,去除掉信息缺失的数据,然后用jieba分词对标题及内容进行分词,并去掉停用词、生僻字等,得到文章的分词内容【这一步骤在爬虫模块已完成】。对每个词来说更新“词-文章序号”的倒排列表。倒排列表的结构如下:
| 词 | 文档频率 | 倒排记录表 | 字典序号 |
|---|---|---|---|
| 中国 | 3 | 1,3,4 | 0 |
| 招聘 | 1 | 4 | 1 |
| 蜜蜂 | 2 | 1,2 | 2 |
计算各文档的向量
假如文档1包含的词有【中国,蜜蜂】,按照上字典序号对应的关系,词向量应该为\([1,0,1]\) 。而用01表示词其实并不科学,这里每个词可以用TF-IDF来优化。那么词向量可能会变成\([0.2,0,0.1]\)
计算每个文档的词向量(下表不必存储):
| 文档 | 词 | 词向量 |
|---|---|---|
| 1 | 中国,蜜蜂 | \([0.2,0,1]\) |
| 2 | 蜜蜂 | \([0,0,0.8]\) |
| 3 | 中国 | \([0.7,0,0]\) |
| 4 | 中国,招聘 | \([0.4, 0.6, 0]\) |
将词向量模型更新添加进倒排索引:
| 词 | 文档频率 | 倒排记录表【文档编号,本词的TF-IDF】 |
|---|---|---|
| 中国 | 3 | [1,0.2] , [3,0.7] , [4,0.4] |
| 招聘 | 1 | [4,0.6] |
| 蜜蜂 | 2 | [1,0.1], [2,0.8] |
考虑到词频等会随着文档的更新变化,因此次表可以进行一下优化:
倒排记录表优化为:
| 词 | 包含该词的文章数 | 倒排记录表 |
|---|---|---|
| 包含该词的文章数 | 文档编号、该词在本文档出现的次数、文章总词数 | |
TF-IDF
\[词频 TF = \frac{某词在文章中的出现次数}{文章总词数}\]
\[逆文档频率 IDF = log(\frac{文章总数}{包含该词的文章数 + 1})\]
\[TF-IDF = TF \times IDF\]
TF-IDF与一个词在文档中的出现次数成正比,与该词在整个语言中的出现次数成反比。
查询
当用户输入查询词时,例如查询【中国,招聘】这两个关键字时,由于关键字无权重,因此可以直接设查询向量\(q\)为\([1,1,0]\) 。按理来说应该直接对着【文档\(d\)-词向量】表格直接依次计算余弦相似度\(q\times d\),然后取相似度最高的前K个作为返回结果。但是这样太暴力了,也太慢了。
机智的人类发现,q是一个01向量, \(q \times d\) 也就是对于q中那些为1的词项,计算在文档d中这些词的权重值和。
因此我们利用倒排索引优化查询。步骤为:
- 在词典中定位【中国,招聘】这两个词,返回其倒排记录表。【中国 --> [1,0.2] , [3,0.7] , [4,0.4]】,【招聘 --> [4,0.6]】
- 文档4中,中国和招聘两个词的权重值和为1;而文档1的权重为0.2;文档3的权重为0.7
这里还有一个优化:由于只需要前K篇文档,因此可以通过堆结构,留下来前K个文档即可。
索引建立流程图
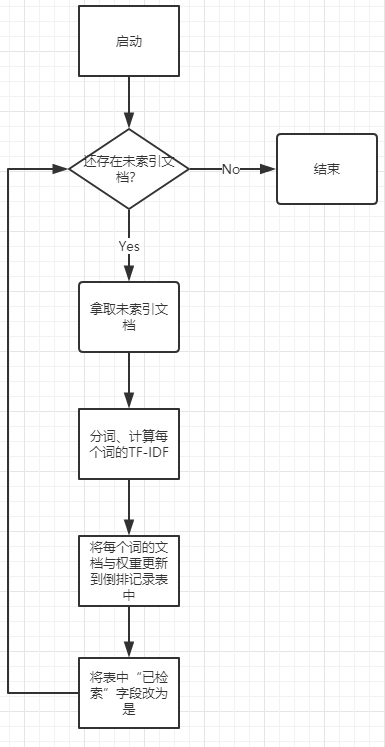
数据库设计
将爬好的数据进行实时计算,填入下表
| 词 | 文档频率 | 倒排记录表 |
|---|---|---|
| 中国 | 3 | [1,0.2] , [3,0.7] , [4,0.4] |
| 招聘 | 1 | [4,0.6] |
| 蜜蜂 | 2 | [1,0.1], [2,0.8] |
当时这个结构直接存储在了内存当中。但讲道理应该存储在MongoDB这一类KV数据库中。
旧数据删除
每个帖子是有有效期的。当某个帖子过了某个时间后信息量就会变得很少,不再有检索需求。因此需要将旧帖子删掉。本系统设定当帖子的最后更新时刻与当前时刻超过10天时,此贴应该被从数据库与索引中删除。
本系统定义每天的凌晨4点进行旧数据清除工作。
倒排索引优化
回头重新看这个问题时,我们发现如果有高并发等类似的请求时,系统还有很多地方需要优化:
字典优化
在实现字典时,通常会使用哈希表、树(二查查找树、字典树)等数据结构。
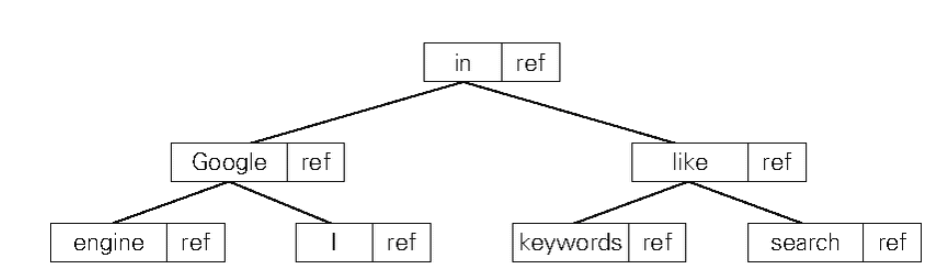
用二查查找树实现字典
使用二叉查找树实现词典时, 要先将数据对(的列表) 按照单词词典顺序排列。
数据对 = [单词 + 该单词的倒排列表的引用信息]
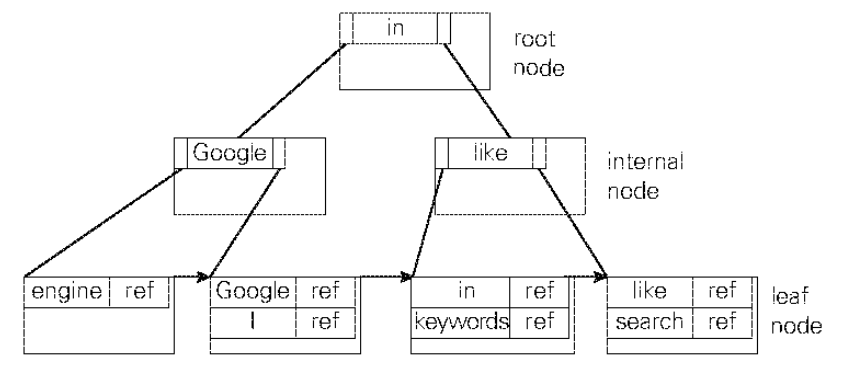
若用内存上的二叉查找树实现之前例子中的词典, 就会得到如下图所示的树形结构。 树中的各个结点是通过地址引用(指针) 连接起来的
一般倒排列表都会很长。因此会考虑将倒排列表存储到二级存储的连续区域中。
在二级存储上实现词典时,也要先将数据对按照单词的词典顺序排列, 然后一个接一个地存储到存储器上。 但是, 如果只是单纯地一个接一个地存储, 就无法知道各数据对应该在哪里结束了, 因此在此之上还要维护一个列表, 用于存储从开头算起每个数据对的偏移量。 对应的数据结构如图所示。 在进行检索时, 可以对该偏移量的列表进行二分查找。

如果词典能够完整地加载到内存, 那么所形成的二叉树的搜索效率将会非常高。 特别是当二叉树处于平衡状态时, 平均进行\(log_2N\) 次查找就能找到单词。 但是, 如果词典无法完整地加载到内存(假设一共3000个词,每个词后面有500篇文档,每个文档header为20byte,则一共3000x500x20 = 30Mb, 也没多少哈), 而必须存储到二级存储器上时, 二叉树就未必是高效的数据结构了。 HDD 或 SSD 等二级存储器一般被称作“块设备”, 由于它们是以块为单位进行输入输出的 , 所以即使只是读取块中 1 个字节的数据, 也不得不对整个块进行输入输出操作。 例如, 假设我们用二叉查找树实现了含有 100 万个单词的词典, 那么进行二分查找的话, 平均需要 20 次查找, 因此在最坏的情况下就需要加载 20 个块。 也就是说, 假设二级存储的加载性能为 5ms/ 块, 那么在 1 次检索中, 仅花费在二级存储输入输出上的时间就高达100ms。 因此, 当要存储大型词典时, 往往要使用适合块设备的 B+ 树等树形数据结构。
用B+树实现字典
B+ 树是一种平衡的多叉树, 属于从 B 树派生出来的树形结构。 在 B+ 树中, 所有的记录都存储在树中的叶结点(Leaf Node) 上, 内部结点(Internal Node) 上只以关键字的顺序存储关键字
B+树通常以文件系统中页尺寸的常数倍为单位管理各节点。这样有助于减少检索时对二级存储的输入输出次数。
构建倒排的方法
简单的文档列表直接存储在内存中。但是大多数情况倒排索引都是非常稀疏的表,因此用链表实现倒排索引非常好。
而文档链表一般都很大。因此很多都存储在二级存储中。这样就有两种构建方法:基于排序的构建方法和基于合并的构建方法。
基于排序的索引构建法
- 对各文档中构成该文档的每个单词都建立一条【单词、文档编号、TF】的记录。然后将该记录写入二级存储上的文件末尾
- 将文件各条记录按照字典顺序排列;单词字段相同的再按照文档编号顺序排列
- 逐行读取排序后的文件,去除每个单词的文档编号列表;并用这些列表构建每个单词的倒排索引(这一步可以压缩倒排列表,此处省略)
基于合并的索引构建法
基于合并的索引构建法是一种先在内存上构建出倒排索引的片段,然后将这些片段导出到二级存储,最后将导出的多个倒排索引合并在一起。
- 在内存上构建【单词-倒排】的kv映射表Map。
- 如果某单词不在Map里,就要将该单词加入到Map中
- 当Map过大,就将Map导入文件里
- 重复1-3步骤,直到处理完所有文档。最后利用多路归并将将导出的各文件合并在一起。(这一步也可以压缩倒排,此处省略)
静态索引构建和动态索引构建
之前说的索引构建方法都是只有构建完成后才可用于检索。这叫静态构建方法(Offline Index Construction)。
还有一种动态构建方法(Online Index Construction / Dynamic Indexing)。这种方法可以一边更新索引,一边检索。其基本策略如下所示:
- 将索引分成内存上的索引和磁盘上的索引分别管理
- 添加文档后,优先更新内存上的索引
- 当内存索引满时,将其整合到磁盘上的索引中
索引去除技术
对于一个包含多个词项的查询来说,其实我们只考虑那些至少包含一个查询词项的文档。于是我们可以考虑使用如下的启发式方法。
- 只考虑那些词项的idf值超过一定阈值的文档。也就是说,只考虑那些idf值较高的词项所对应的倒排记录表,因为那些idf值比较低的词其实可以看成停用词,对评分结果也没什么大的贡献。
- 只考虑包含较多的查询词项的文档。但这样有一个风险:最后候选结果可能少于K个。
其它相关
搜索引擎体系结构
从下图可以看到,从功能模块上划分,天网系统由四个子系统构成:
- 搜索子系统:主控、搜集器、原始db
- 索引子系统:索引器、索引数据库
- 检索子系统:检索器、用户接口
- 日志挖掘子系统:用户行为日志数据库、日志分析器

分布式搜集系统结构
单机搜集、单机服务的系统结构(我们习惯称之为集中式结构) 不适应Web上信息规模的迅猛发展。因此分布式并行结构应运而生。
系统分布的核心是数据的分布。
- 对搜集部分而言,实际是将 URL 分布。在执行搜集任务的机器之间,保证它们搜集的 URL 不会重复。
- 对查询部分,则是将索引数据分布在执行检索任务的机器之间。
如上所述的系统概貌如下图所示
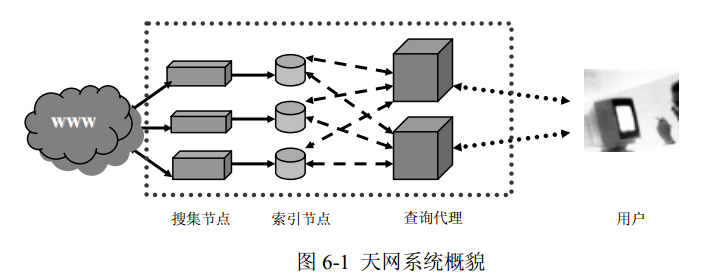
搜集节点之间相互协调,分配 URL,保证一个 Web 主机的全部网页只能存在于一个搜集节点上。每个索引节点对应搜集节点搜集的网页
查询代理节点通过多播向所有索引节点发送查询命令,等待搜集到全部索引节点返回的检索结果后,对所有结果依据相关度排序,并缓存一定数量的结果,最后向用户返回结果的首页。用户的后续查询(翻页),将会在缓存命中,不必再次启动后面的网络查询,这将大大减少查询的响应时间,降低后台查询系统的负载,从而提高查询系统的性能
分布式搜索引擎
搜索引擎主要存储的是两个部分:
- 文档编号-文档内容
- 字典-文档 的倒排
文档编号-文档内容
第一块这里比较占地方。它要存下来所有文档的内容;那么如果要进行数据拆分的话,对于文档我们可以进行横向拆分。将不同的文档放到不同的机器里。这里可以用到一致性哈希原理进行分配。
字典-文档的倒排
(来日天坑)