什么是分布式系统
用多台机器解决一台机器不能解决的问题。比如存储不够?QPS太大?
谷歌三剑客
- 分布式文件系统
- 怎么有效存储数据?
- NoSQL底层需要一个文件系统
- Map Reduce
- 怎么快速处理系统?
- Big table = No-SQL Database
- 怎么连接底层存储和上层数据
本节课内容:
- Master Slave Pattern
- How to check and handle system failure and error
- How to design Distributed File System
| 分布式文件系统 | 公司 | 开源 |
|---|---|---|
| GFS | No | |
| HDFS | Yahoo Open Source of GFS | Yes |
- HDFS : Hadoop Distributed File System
- GFS: Google File System
4S分析法
- Scenario 场景分析
- Service 服务
- Storage 存储
- Scale 升级优化
场景分析
GFS大概的位置在哪里?
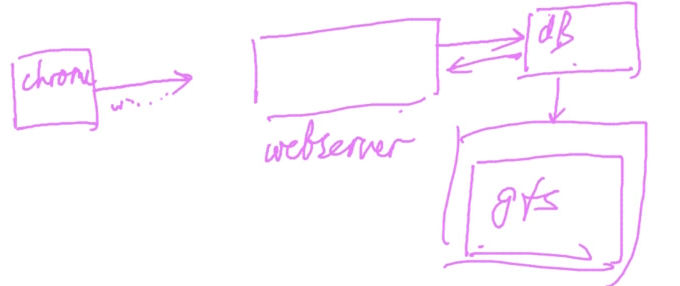
chrome后面有一个webserver, webserver后面有一个db,db下面有一个gfs
需要设计哪些功能呢?
- 需求1:读写
- 用户读写文件
- 支持多大的文件?比如 > 1000T
- 需求2:存储
- 多台机器存储这些文件 —— 2007年google大概10w台
服务
Client + Server
Client是什么?—— 一般是db或者webserver

这样够吗?并不够。Server其实是多台机器!
多台机器怎么沟通?
有两种方式:
Peer to peer
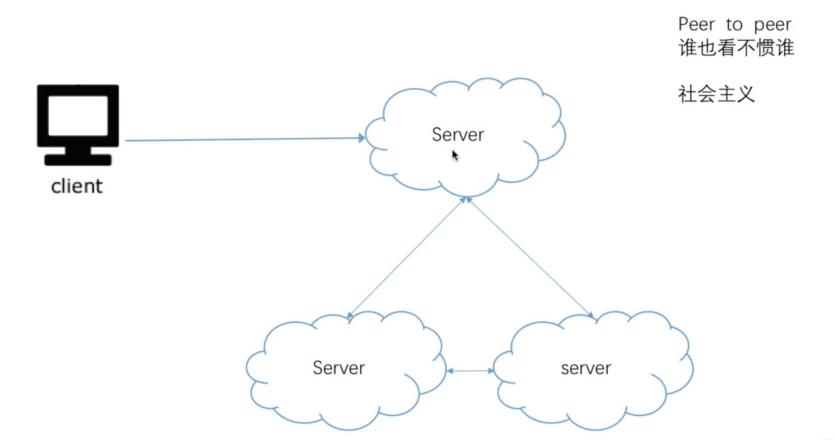
- 优点:如果一个挂了,其它的没事
- 缺点:数据同步问题很麻烦!他是通过一致哈希算法实现的。要不停地相互同步,很麻烦的。
不是课程重点,考察较少(例BitComet, Cassandra)
master - slave
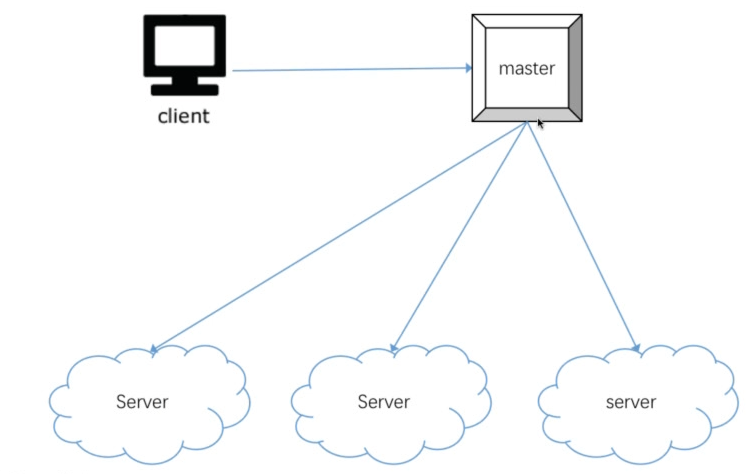
- 优点:同步问题全部交给master,数据容易保持一致;比较好设计
- 缺点:万一一个挂了,就gg
两种master-slave比较:
| 比较 | DB中的master-slave | GFS中的master-slave |
|---|---|---|
| Master | 存储数据 | 管理者(不存储数据) |
| Slave | BackUp | 被管理者(存储实际文件) |
存储
大文件存在哪里? —— 文件系统
操作系统是怎么存文件的?
一个文件里有什么东西?
文件名、写入修改时间、一些Tag、格式、大小、文件内容等
也就是Metadata + 文件内容
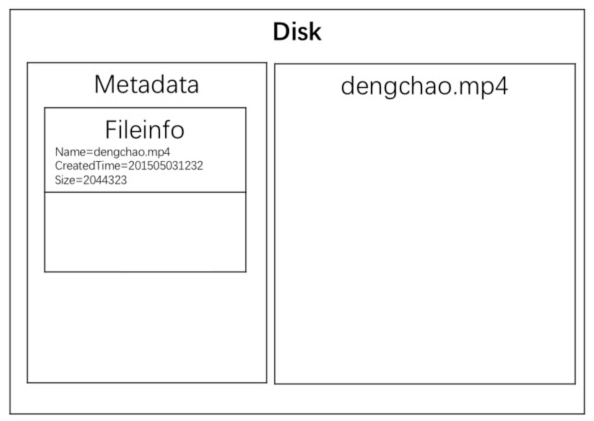
问题来了,那么metadata和文件内容应该存在一起还是分开存?
其实应该分开存。这样在看目录的时候,就不用每次都把硬盘里的东西读出来了。只需要把metadata的内容放到内存里面以供显示。
问题来了,文件是分成小块存储还是存成一大片?
Windows连续,Linux分开存
连续存储带来的问题在于,存储空间会非常分散。这样的话就需要定期进行磁盘碎片整理。
分开存储就不会带来这么多碎片。但是还需要维护每一小块存在哪里。
分开存储
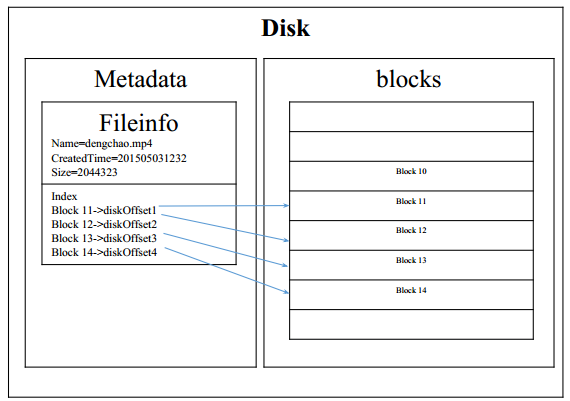
将存储区域分为各个block(1024Byte) ,然后一个Block对应一个硬盘地址
那么大文件有多少个block呢?
100T(多文件) =100x1000G =100x1000x1000M =100x1000x1000x1000K =100x1000x1000x1000 block !! block太多了哇
Google采用的方式——1个chunk = 64M = 64*1024K,这样的优点对大文件友好,对小文件来说优点浪费空间。
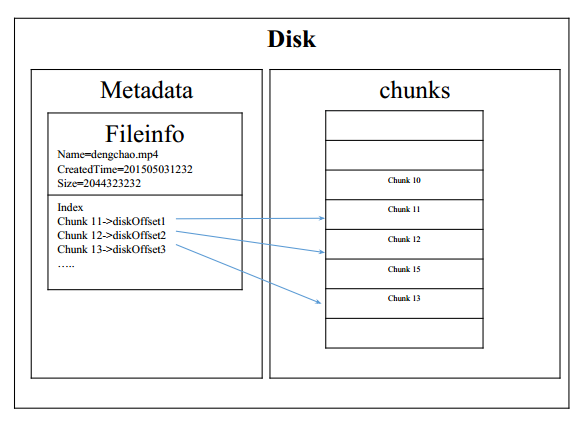
以HDFS为例:
存储
问题又来了,一台机器存不下?
Master-slave模式
Master管理metaDta,Slave管理数据
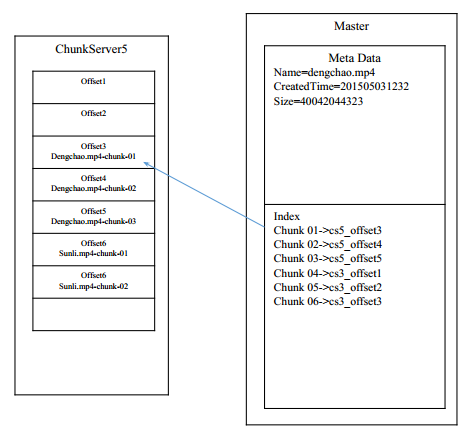
注意:cs代表chunkserver
每个chunk的Offset偏移量可不可以不存在master上面?
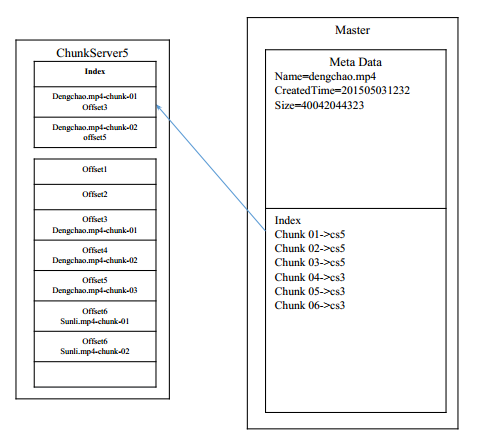
只需要知道哪个chunk在哪个机器上面即可,然后每个机器根据索引再去查询
这样做的好处:master存储量减少;master想修改的时候方便得很
问题:master的内存存的下10P文件的metadata吗?
1chunk = 64b
10P = 10X10^6 = 10G , 完全可以
写入
写文件时,是一次写入还是分成多份写入?
分析:
- 写入过程出错了?
- 如果是一次写入,就要重新写一次
- 如果是多份多次写入,就只用重传一份
- 如果多份多次写入,那么每一份的大小?
- 既然文件按照chunk,那就按照chunk
- 如果多份多次写入,是由master切分呢,还是client切分?
- 其实是client按照自己的文件大小切分
- 比如 /gfs/home/dengchao.mp4 size = 576M. 那么可以切分问 576M/64M = 9个chunk
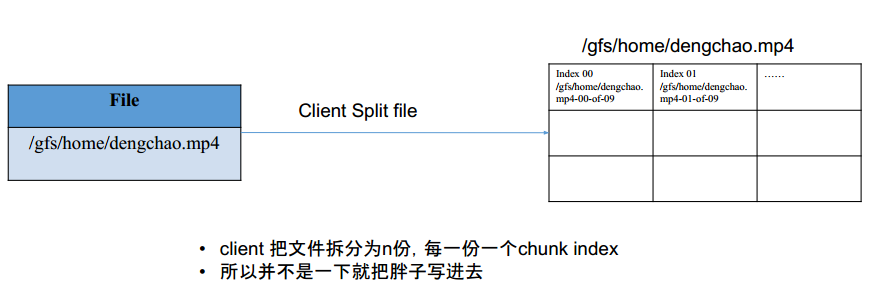
每个chunk怎么写入server?
是直接写入chunk server ? 还是需要master沟通,再写入chunk server?——是直接写入的
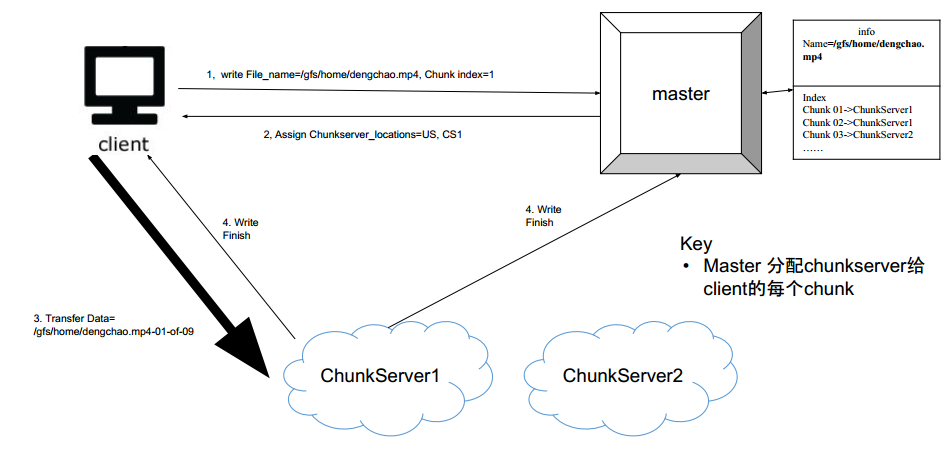
- client先告诉master要写入的chunk 和idx
- master告诉client应该写入几号机器
- master去写入chunkserver
- chunkserver告诉master写好了
要修改Dengchao.mp4怎么办? 对于/gfs/home/dengchao.mp4,需要解决以下问题:
- 要修改的部分在哪个chunk?
- 修改了过后chunk变大了要怎么处理?
- 修改了过后chunk变小了要怎么处理?
修改假设有以下几种方式:
- 方式1 : 直接修改
- 方式2:先把这一快读入内存,再写回去
- 方式3:先把这一块读入内存,再写到其它地方
分析:
- 方式1:不行的
- 方式2:修改了过后chunk变大了就放不下了
- 方式3:可以的
读取
如何读取文件?
一次读整个文件?还是拆分成多份多次读入?

那么另一个client想读的时候,他怎么知道,dengchao.mp4被切成了多少块? —— master告诉他呀!!!
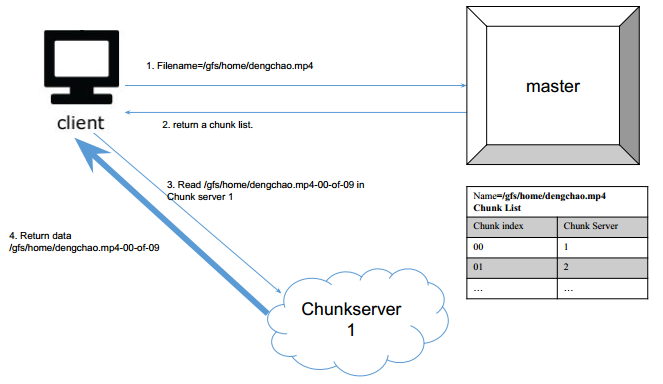
- client告诉master他要读谁
- master告诉client一个chunk list
- master去chunk server读
Master主要都干了什么?
- 存储各个文件数据的metadata
- 存储Map(file name + chunk index -> chunk server)
- 读取时找到对应的chunkserver
- 写入时分配空闲的chunkserver
为什么不把数据直接给master 让master 去写?
Master bottleneck ,这样对于master来说太累了
总结
- 存储
- 普通文件系统 Meta Data,Block
- 大文件存储: Block-> Chunk
- 多台机器超大文件: Chunk Server + Master
- 写入
- Master+Client+ChunkServer 沟通流程
- Master 维护metadata 和 chunkserver 表
- 读出
- Master+Client+ChunkServer 沟通流程
扩展
单Master够不够?
工业界90%的系统都采用单master Simple is perfect
单Master挂了怎么办
- Double Master 双龙戏珠 Paper: Apache Hadoop Goes Realtime at Facebook
- Multi Master Paper: Paxos Algorithm
挂了和恢复方法
如何验证一个chunk是坏了的呢?
先介绍CheckSum方法
CheckSum是由每个二进制异或得到的。这种方式只能检测一位错误
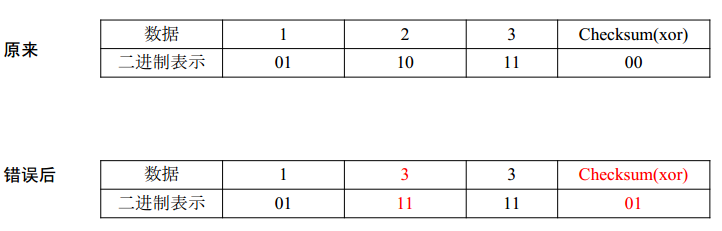
- CheckSum Method (MD5, SHA1, SHA256 and SHA512)
- Read More: https://en.wikipedia.org/wiki/Checksum
一个CheckSum大小为4byte = 32bit
而一个chunk = 64MB, 每一个chunk有一个CheckSum。1P的文件的CheckSum大小大约为1P/64MB*32bit = 62.5M
什么时候写入CheckSum?
写入一块chunk的时候就顺便写入哇
什么时候检查checksum?
读入这一块数据的时候检查
- 重新读数据并且计算现在的checksum
- 比较现在的checksum和之前存的checksum是否一样
那么如何避免万一坏了之后,数据丢失呢?
Replica ! 就是备份。一般都备份3份。如果某个坏了,就去询问master
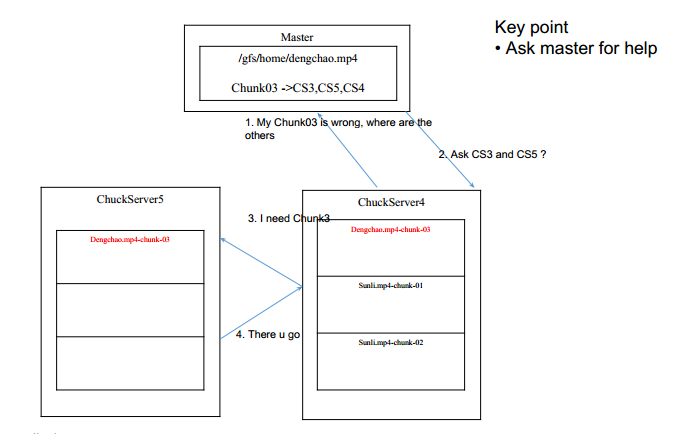
备份有几种方式:
- 三个备份都放在一个地方(加州)。 —— 不好。太危险
- 三个备份放在三个相隔较远的地方(加州,滨州,纽约州)—— 太分散,不好通信
- 两个备份相对比较近,另一个放在较远的地方(2个加州,1个滨州) —— 挺好
如何发现一个chunkServer坏了呢?
HeartBeat
如何写多份?
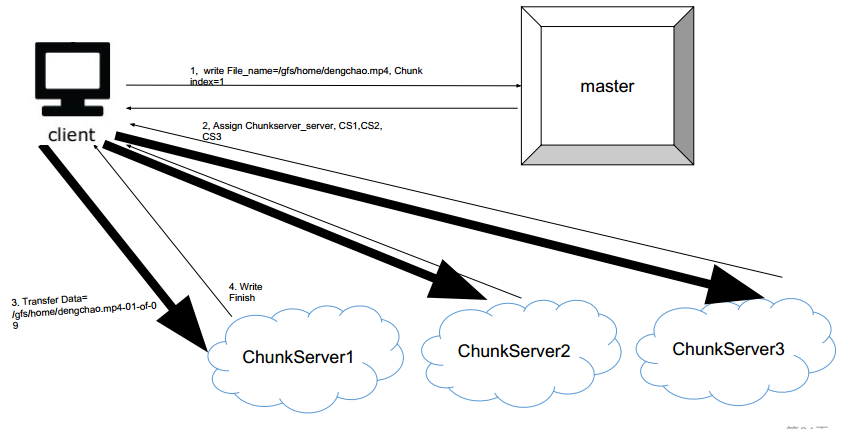
但这种方式对于client来说太慢了,因此优化一下:
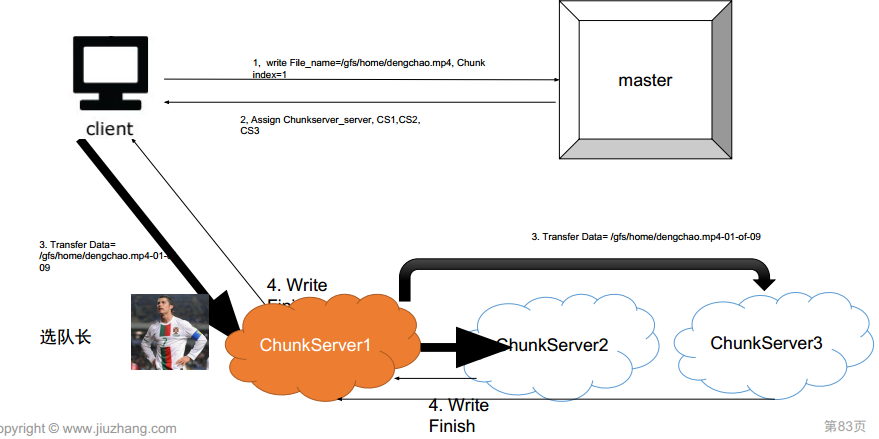
怎么样选队长?
- 找距离最近的(快)
- 找现在不干活的(平衡traffic)
如果一个chunk server挂了怎么办
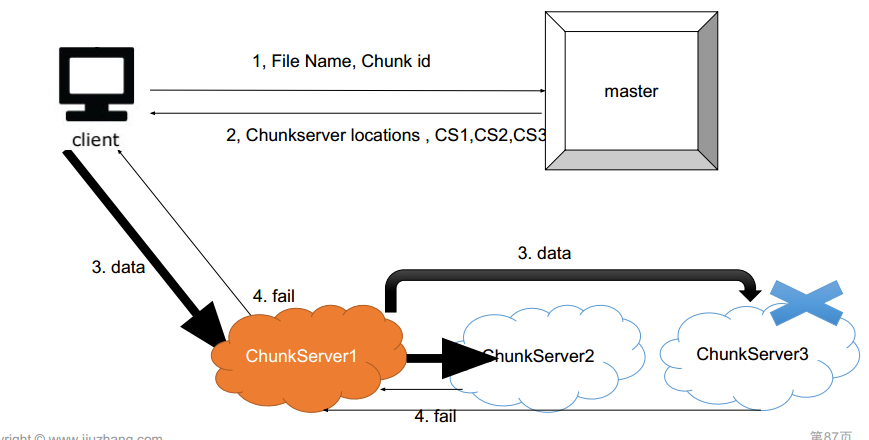
选chunk server的时候有什么策略?
- 最近写入比较少的。(LRU)
- 硬盘存储比较低的。