大纲
- 设计一个web爬虫
- 线程安全的生产者-消费者模式
- 搜索建议系统
爬虫
搜索引擎如何爬取网页呢?也就是我们想获取如下所示的表:
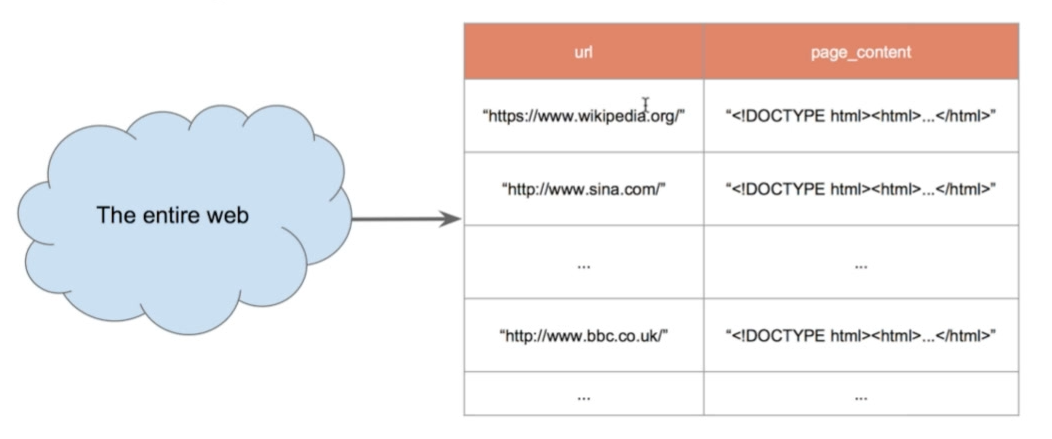
那么想要用程序完成这个目标,我们首先要知道一个事实,也就是互联网上的内容其实是互相索引的,也就是就像如下的大网一样:
假设一共有1trillion个网页,而且至少一周更新一次。那么每秒要爬取1.6m网页。每页大概10k,那么些网页存储下来大概需要10p的存储空间。
单线程爬虫
一般来说,爬虫是用BFS进行爬取的。对于单线程的爬虫来说,就是搞一个队列:
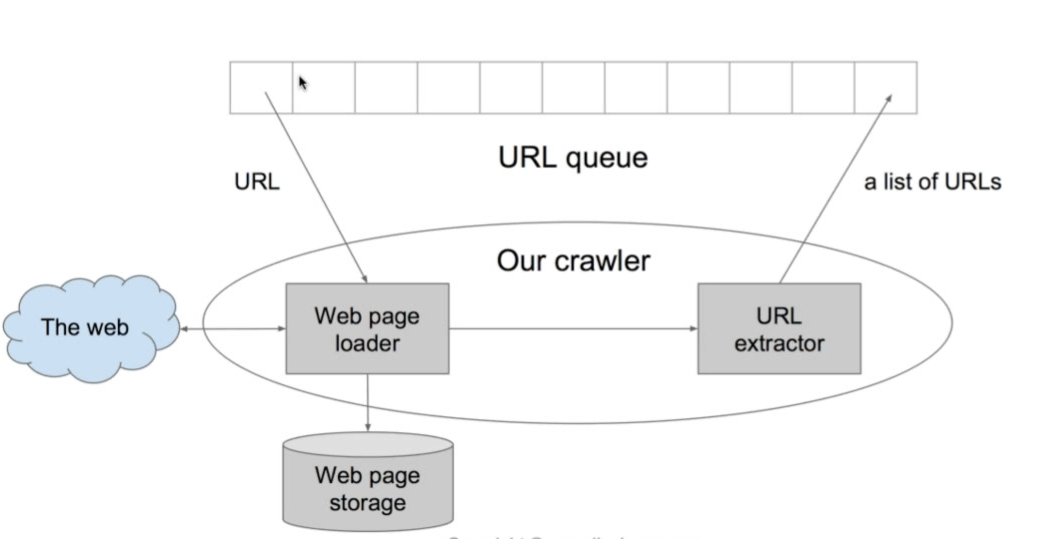
生产者-消费者模型
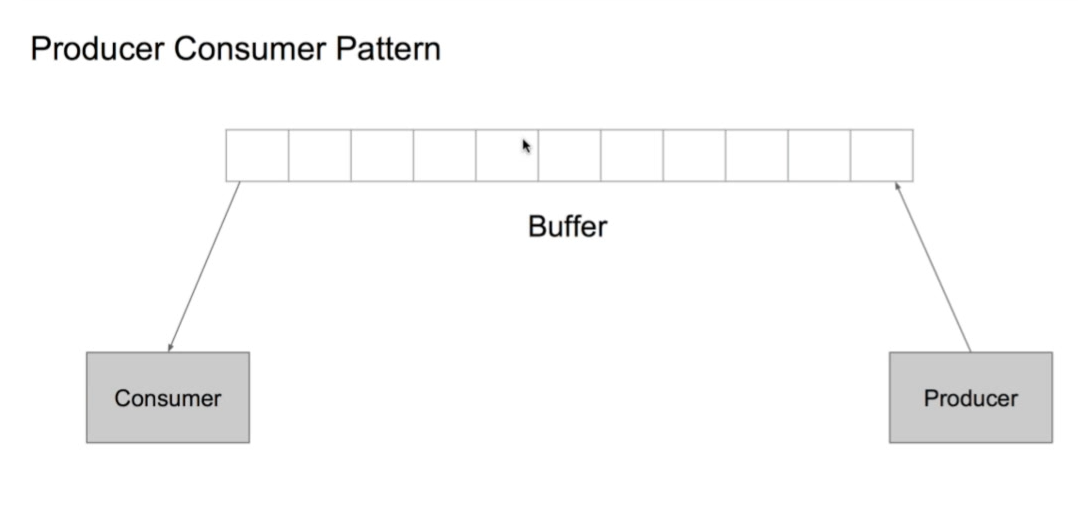
也就是生产者一直往里怼任务,消费者拿任务。中间有一个Buffer(原因是存取速度不一样)。
那么回头看看我们的爬虫,其实URL extractor就是生产者,而Web page loader就是消费者。
但是单线程有一个问题,就是慢的很。解决——多线程爬虫
多线程爬虫
这些线程共享同一个URL队列,那么这个队列就要加锁。(DFS没有办法实现这个多线程,因此用BFS)
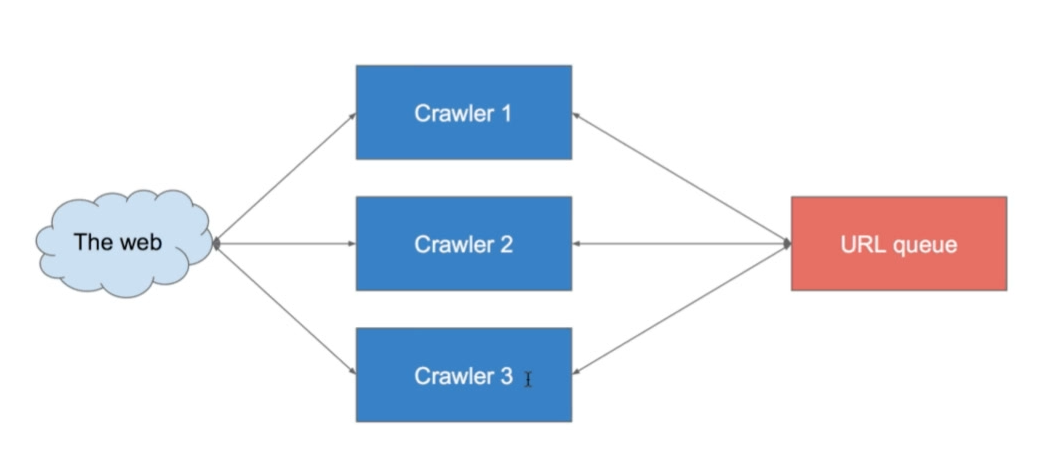
需要注意的是,争取共享资源,就要考虑以下三个机制:
- sleep —— 就是随机睡一会,但问题在于无法立马知道资源可以使用了
- 信号量(实现互斥)—— 相当于所有的线程都在等着,然后信号量通知他们能用的时候,就抢着占用资源
- semaphore —— 就像门上挂上五把钥匙一样,能够解决抢占资源的问题
单线程 --> 多线程:
- 线程来回切换(context switch)还是有花费(需要保存线程执行状态,还需要切换二级缓存等)的,因此线程不能太多
- 线程端口数目是有限的(TCP/IP协议中,端口只有2个字节,也就是65536个端口)
因此我们可以改进一下:
分布式爬虫
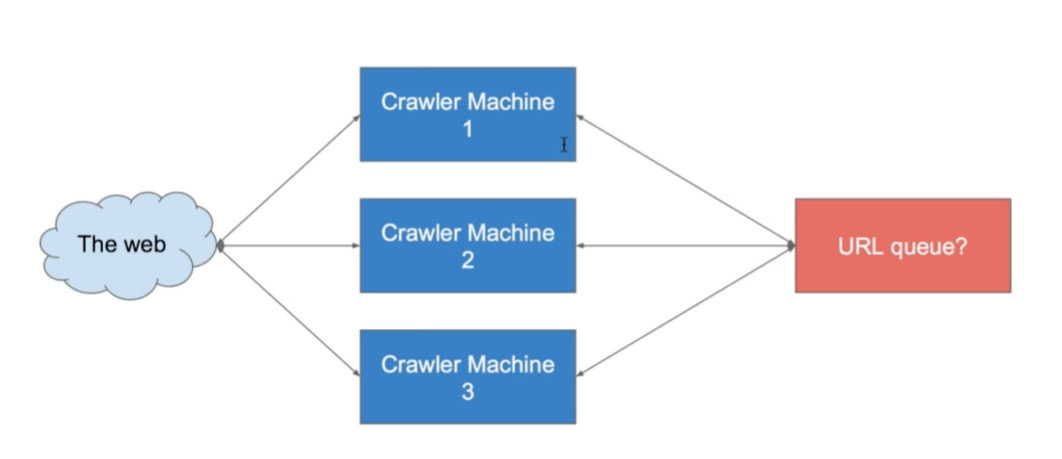
分布式爬虫虽然解决了线程不能太多的问题,但是又带来了一个问题:URL队列在内存中放不下了(假设1trillion,差不多要40T的内存)!这是不行的。那么我们考虑一下存在硬盘里,也就是数据库里。
最要命的限制是:没有办法控制网页的顺序和优先级啊!
解决:给数据库加入一个优先级的列,再加一个频率的列
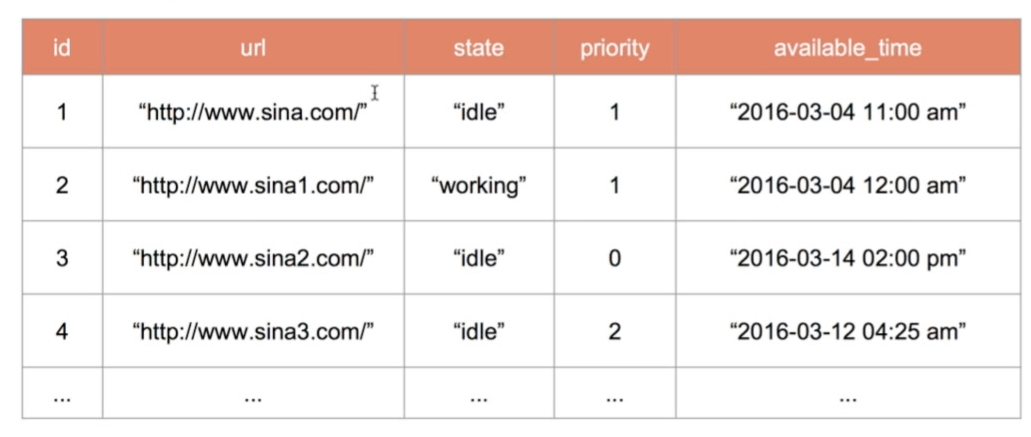
每一行是一个任务:
- ID,URL
- state:是否正在运行的状态(即能去重,也能防止重复运算)
- priority:优先级
- available_time:控制抓取频率,也就是这个时刻之后再进行抓取。如果本次有更新,那么就把时间设置地更近一些;如果本次没有更新,那么就把时间设置地更远一些
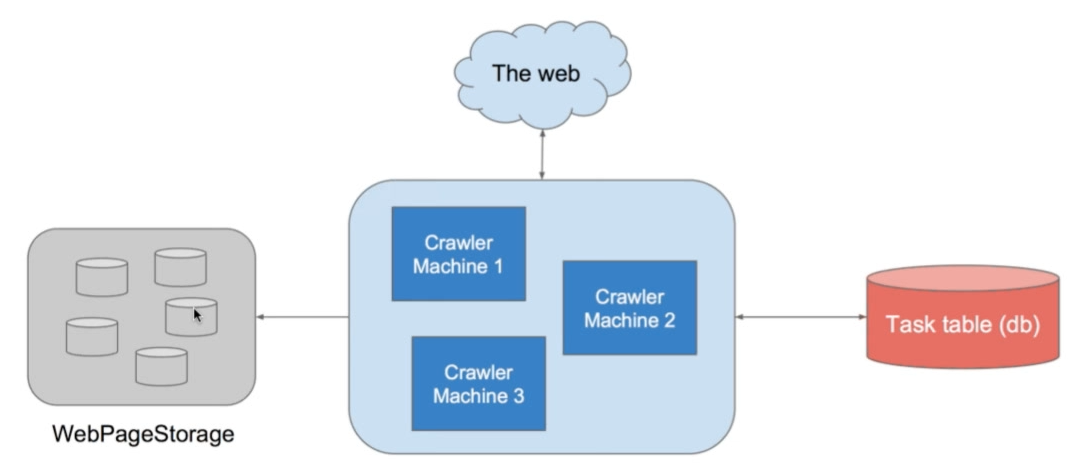
- webPageStorage : 分布式存储,存储爬取的东西
- 爬虫
- Task table : 就是上面的任务表
总结
场景:多少网页?频率?有多大?
服务:爬虫、Task Service、存储系统
存储:用db存储task,一个超大的BigTable存储web pages
遇到的问题
task table 最终会非常大!1 trillion 个task,而且会越来越大
解决——拆表,加速select
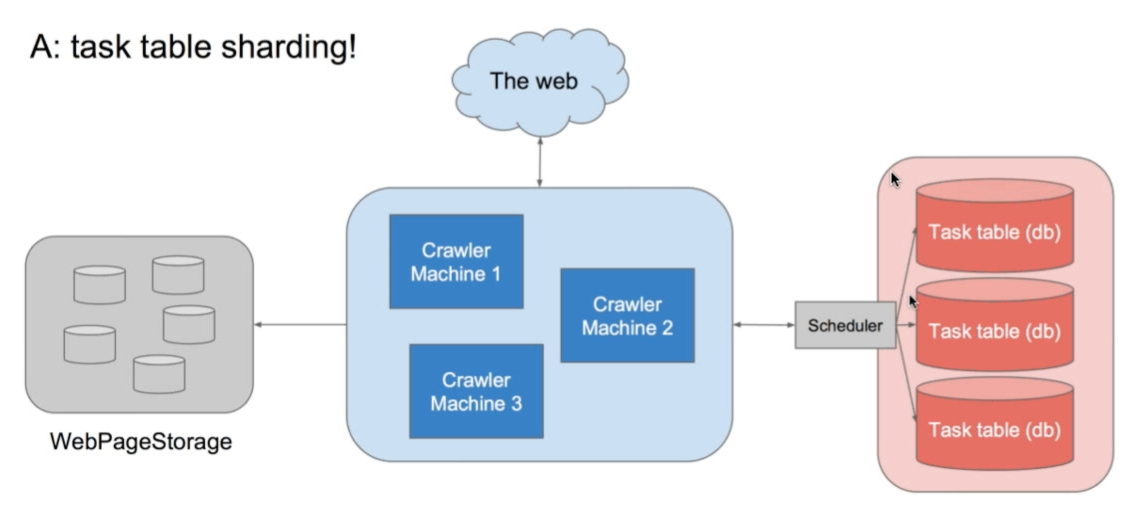
那么拆表就有一个细节需要注意,需要一个scheduler,用来安排去哪里要数据。
网页抓取频率问题
如何控制抓取频率呢?有一个暴力的方法:
- 如果本次抓了有更新,那就把下次抓取的时间提前一半
- 如果本次抓了没更新,就把下次抓取的时间往后移2倍
如何处理死循环问题?
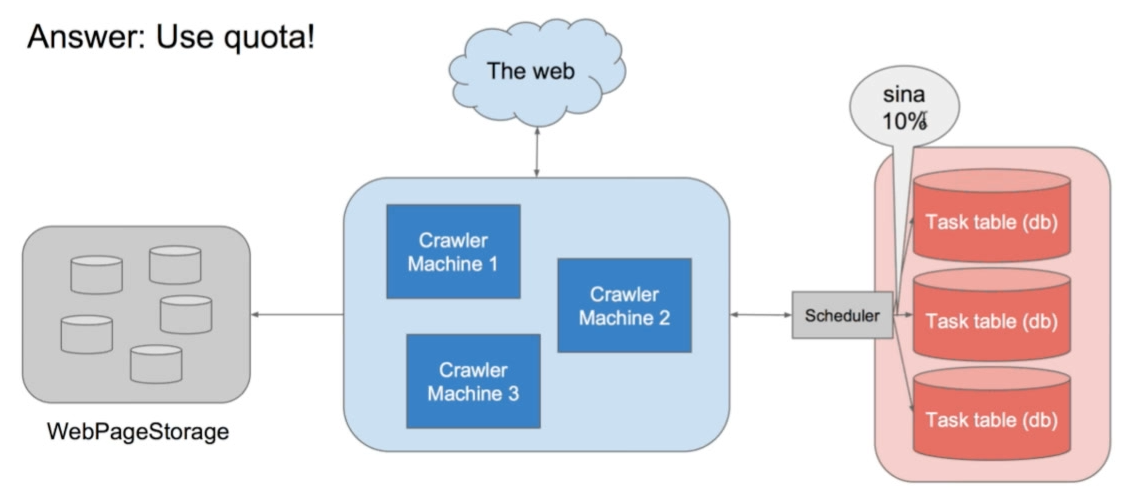
有些网站是互相指向的,比如sina.com。而且所有的URL都是与sina.com差不多的。这样就会使用大量的资源去抓取这种巨型网站,太耗费资源了。对于那些小博客就不公平。
解决办法:单位时间对同一个网站,不要分配过多的计算资源就好啦。
Typeahead
Google Type ahead ——
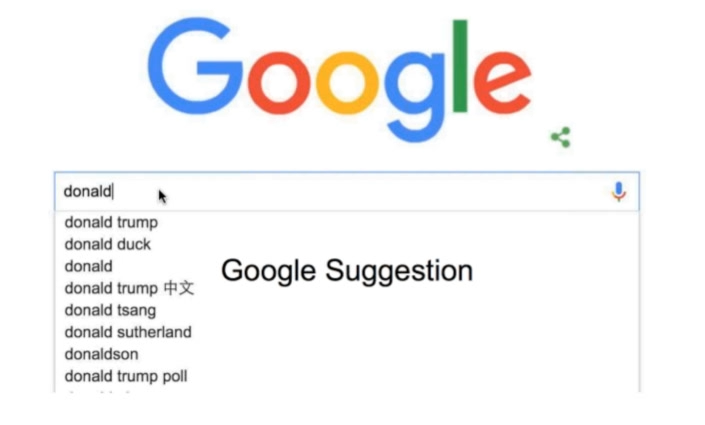
我们以google Suggesion为例
场景
- 日活跃:500m
- 搜索量:4 x 6 x 500m = 12b (每人搜索6次,输入4个单词 = 使用了typeahead四次)
- QPS : 12b / 86400 = 138k
- Peak QPS = QPS X 2 = 276k
服务
要求:敲下一个字母,就赶紧返回热门词才行
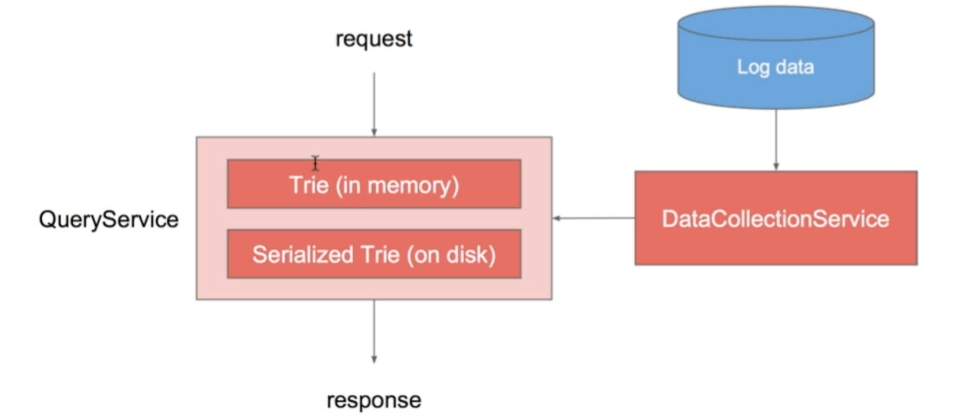
- QuerySerivce : 完成typeahead行为
- DataCollectionService : 收集数据、将热门词数据提供给QueryService
影响QueryService的执行时间的最关键因素就是数据结构,其实用Trie树就够了。这里不做过多的介绍。
DataCollectionService对Trie的更新就是个问题。当然不可以直接更新线上Memory中的索引。解决方式,就是在另一台机器上进行更新,另一台机器上的Trie跟这台机器磁盘上的Trie一样的。那就在另一台机器上先加载Trie树到内存,然后更新,再写入硬盘。再同步过去。
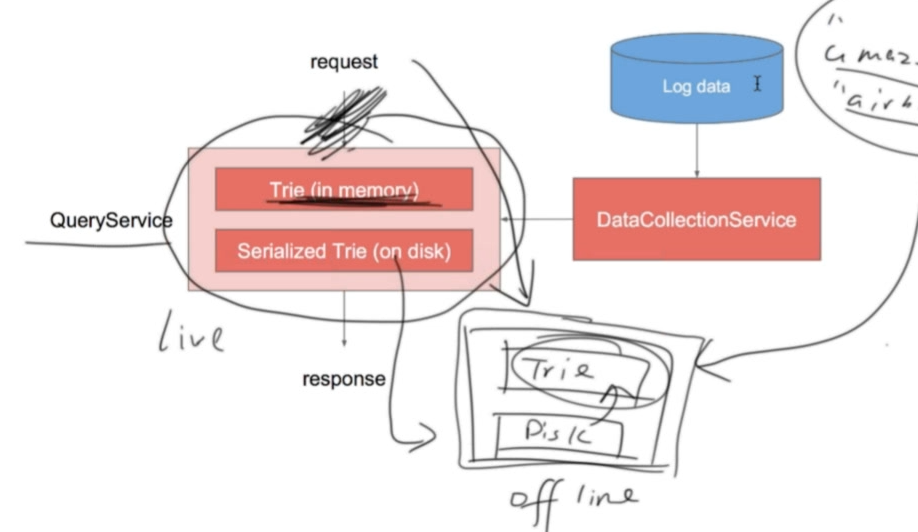
Trie树一台机器的内存存不下咋办?
分机器存哇。
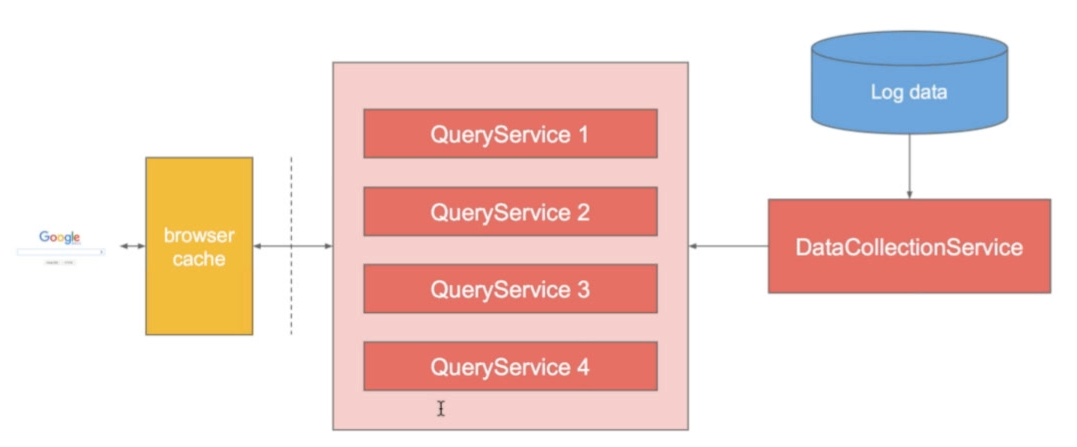
那么怎么分呢?
- 按照字母分? 会存在严重的不平衡问题,因为有的字母的词超多。
- 分布式存:
存储