Map Reduce : 对大数据的快速计算!
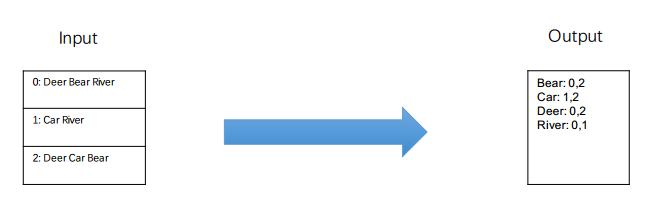
经典场景:统计一个网页中的单词频率。(lintcode题——word count)
朴素方法:for循环
1
2
3
4
5HashMap<String, Integer> wordcount;
for(word : webpage){
wordcount[word]++
}
朴素方法2:多台机器for循环
每个机器(machine1和machine2)各统计一行,然后用machine3汇总到一起,如下图所示
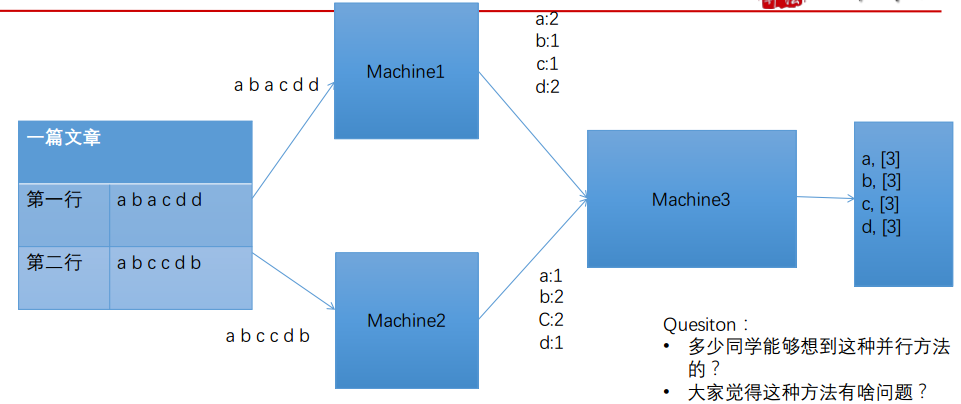
上面存在一个问题:machine3汇总很慢!
Map Reduce
- 左边machine1和machine2进行统计,将文章拆成一个个单词 —— 分,Map
- 右边machine3只负责a和b的汇总;machine4只负责c和d的汇总 ,将机器34合并在一起—— 合,Reduce
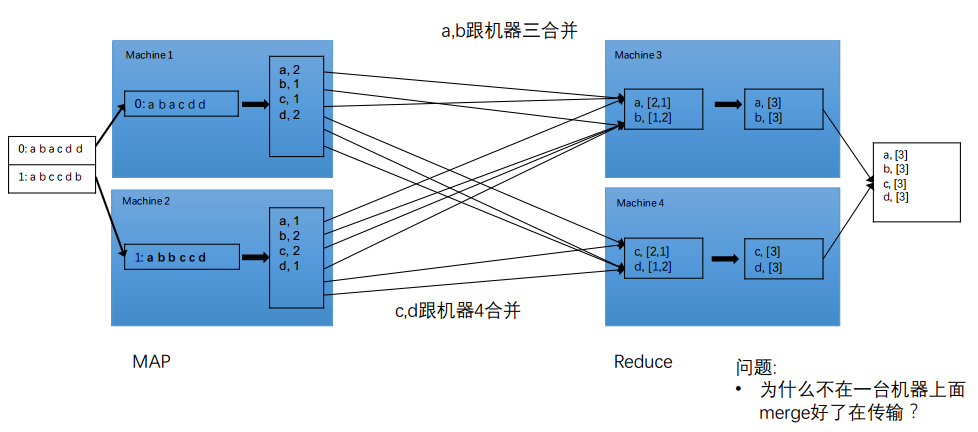
存在的问题:
- 谁负责把文件拆成一段段?
- 谁负责传输?
Map Reduce
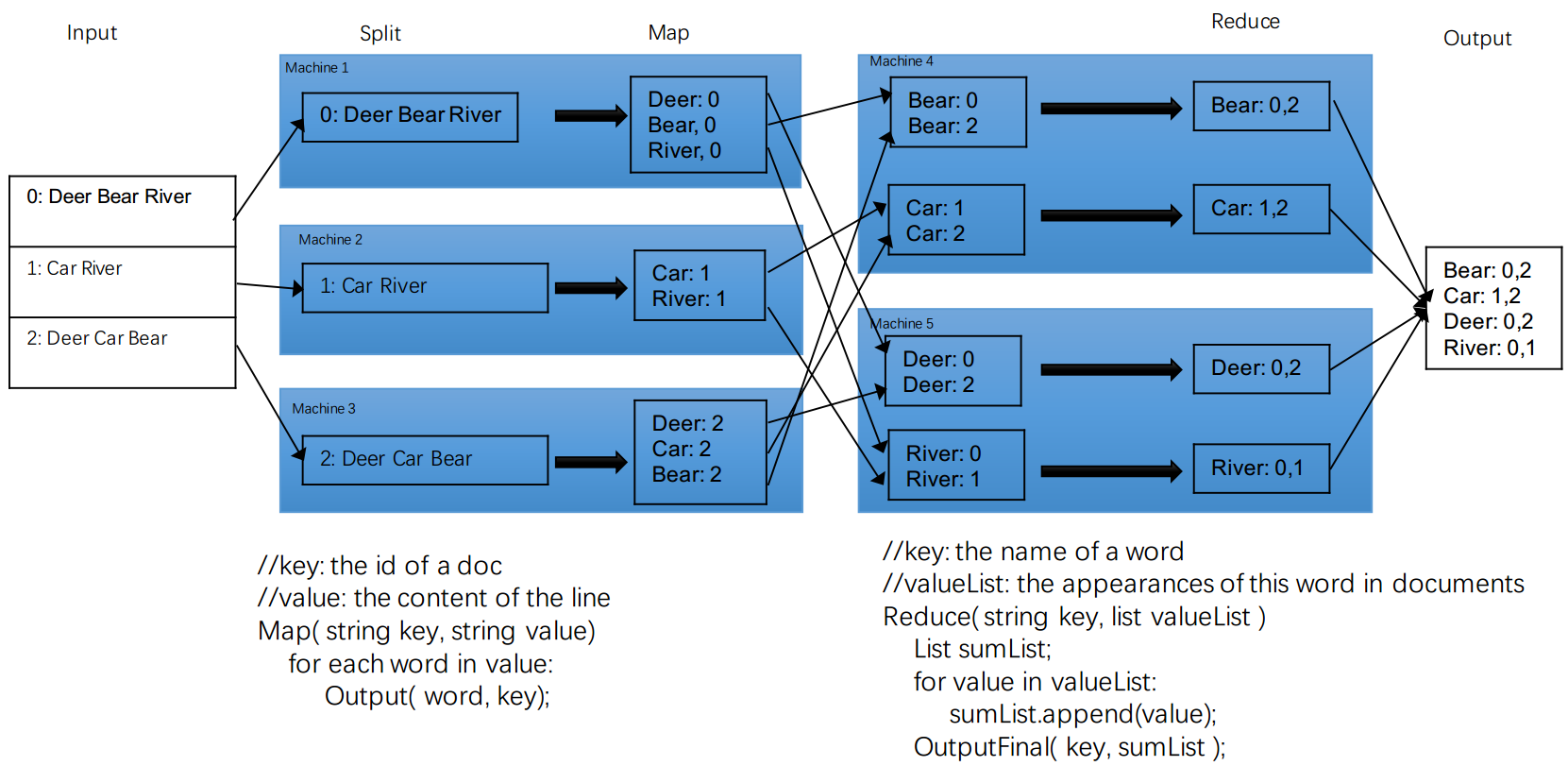
Map Reduce 是一套实现分布式运算的框架,主要由以下几个步骤组成:
- Input,输入文件
- Split, 拆分,系统帮我们把文件尽量平分到每个机器
- Map(需要实现的部分)
- 传输整理,系统帮我们传输和整理
- Reduce(需要实现的部分)
- Output,输出文件
以上的6步具体对应的上面的例子,就是:
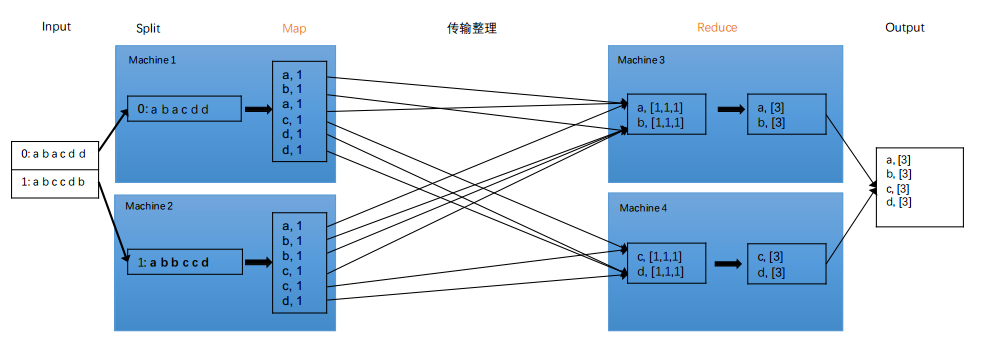
小注意:这里的统计时,并没有进行合并,而是各统计各的。这样不需要开hash表,这种表太大了。而且统计的时候非常慢,必须统计完了才传输,很墨迹。
我们具体要实现什么呢? : 要实现Map函数和Reduce函数:
public void map(String key, String value, OutputCollector<String, Integer>,这是Map函数。输入都是key-value形式。key是文章id/文章存储地址,value是内容public void reduce(String key, Iterator<Integer> values, OutputCollector<String, Integer> output):输入也是key-value形式;key是单词,value是次数
Map实现
- 目的:把文章拆分为一个个单词
- 输入:key-value结构,key=文章id/存储地址,value=文章内容
- 输出:key-value结构,key = 单词,value = 次数
传输整理
传输过程是?peer to peer?还是master slave?—— 其实是master slave,master去安排到底传到哪里。
传输实现了什么?
- 单词排好序了(a一定在b前面):有利于之后的统计处理
- 分好工了:每台机器处理量都差不多
- 传输
简单设计:
- 方法1:Map端用hashmap先合并,再把相同的key合并到一起
- 方法2:reducer端: 把相同key排序在一起—— 存在的问题,排序很耗内存。
正确打开方式
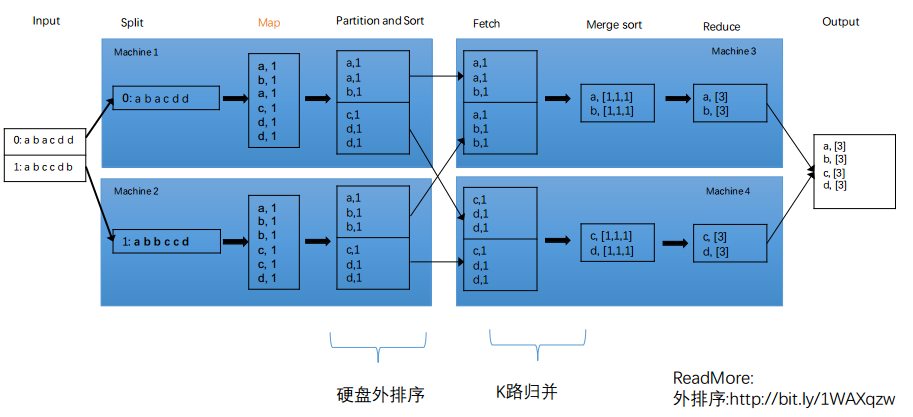
- Map输出前,先进行partition和排序操作
- reduce主动去map端主动拿(fetch)需要的数据
- 将fetch到的有序表进行K路归并
上面所述的排序叫做外排序,也就是不是所有数据都在内存里的排序。具体详细看wiki百科
Reduce实现
- 把对应的key合并到一起,合并成
a : [1,1,1]的形式 - 最后把结果相加
常见问题
- Google处理全网的信息,Map多少台机器?Reduce多少台机器?—— 处理量大概10p,因此1000台就够了
- 机器越多越好吗?—— 并不是。机器越多,各种代价越高(配置、启动机器时间、管理什么的)
- 如果不考虑启动时间,Reduce机器越多越快吗?—— Reduce是有上限的,有些东西key数目是有限的。
lintcode - Word Count
1 | /** |
Apple面试题——用Map Reduce构建倒排索引
lintcode题 inverted index map reduce
做法:
- Input
- split : 每个文章一个机器
- map : 输入key-value应该是什么?——key = 文章地址,value = 文章内容 输出key-value应该是什么?—— key=word, value = doc index
- 传输:将不同的word排好序,分到各机器
- reduce:依次for循环,直接统计就好
- output
lintcode题——倒排索引的Map reduce
1 | public class InvertedIndex { |
Apple面试题——anagram Map Reduce
lintcode题 anagram map reduce
如果几个单词是由一样的字母组成,那么就是同一个anagram。如何用map reduce方法来操作?
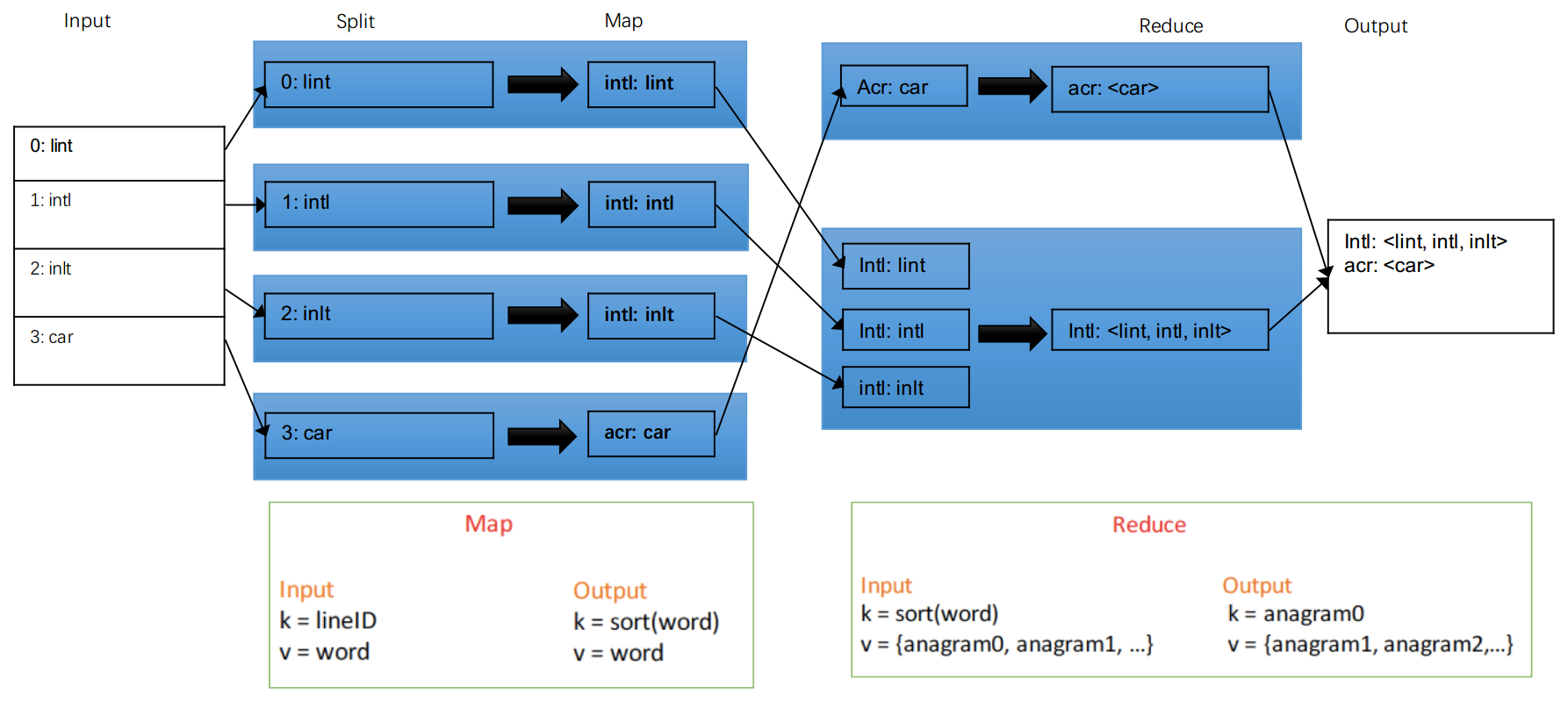
- input
- split:每个机器处理一个单词
- map : 输入key-value是什么?—— key = lineID, value = word 输出key-value是什么?—— key = sorted(word)也就是排好序的单词, value = 原word
- 传输整理:排序+整理
- Reduce : 相同key的合并在一起就好了
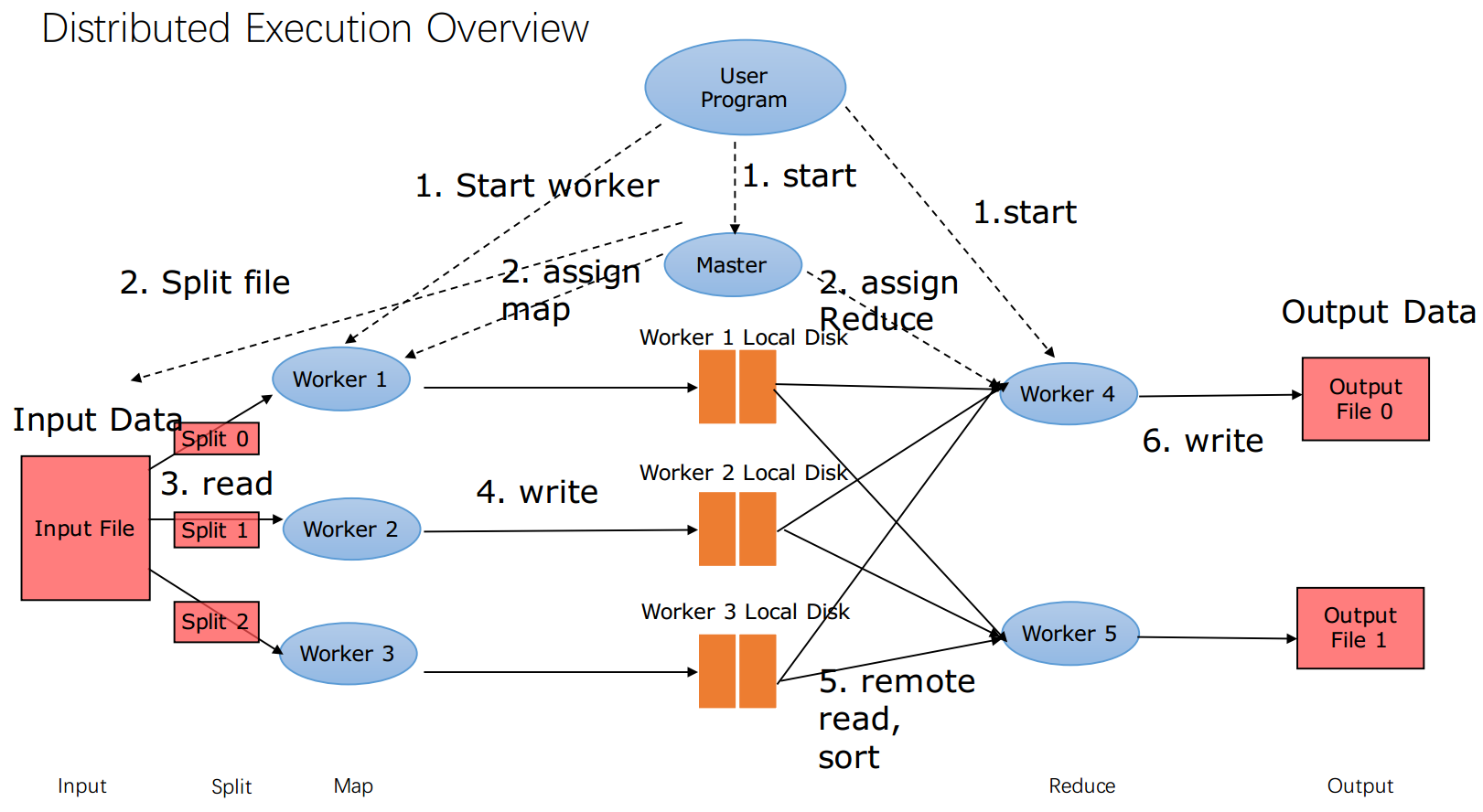
Map Reduce系统设计
根据六个步骤,看看这些都是啥
- input 文件 —— 存在哪里呢?disk? memory? gfs? —— 其实在gfs里
- user写好了代码,配置多少个master, 多少个worker, 谁做map,谁做reduce。然后把user的代码放到各个机器上。然后就启动了。
- master找到输入文件,然后拆分,给各个worders,跑Map的部分
- Map输出后,放入worker的硬盘里(为什么要放到disk? 能不能放到gfs呢?没有必要啊,没那么大)
- 传输整理
- reduce拿到输入,开始reduce运算
- 输出文件—— 一定要放在gfs里,很重要,需要replica,因此要在GFS里
常见问题
- Mapper和Reducer是同时工作还是先Mapper后Reducer ? 先Mapper后Reducer
- 万一Mapper或者Reducer挂了咋办?重启?重选机器? 重新分配一台机器做
- Reducer一个机器key特别大咋办?(例如统计网站流量,网站url作为key,有的key的内容特别多,一个机器做不了) 加一个random后缀,类似shard key,将同一个url分到不同机器上
- input和outpu放哪里? GFS
- local disk上的mapper output data有没有必要放在GFS上,要丢了咋办? 重做就行,不用GFS
- mapper和reducer可以放在同一台机器吗 这样不是很好。因为mapper和reducer之前需要很多预处理工作,而如果放在两台机器,就可以做并行预处理