什么是big table? —— 分布式数据库 
文件系统与数据库
文件系统:
操作:输入——/home/jiayi/test.txt ;输出——文件内容
但如果想改文件里的一点点内容,就比较麻烦了。需要打开文件、for循环扫描内容、找所需要的东西、改动、重新将全部东西都写入文件。所以文件系统只能提供一些简单的读写文件操作。但实际查询中有比较复杂的查询需求,所以我们需要一个更复杂的系统,建立在文件系统之上。也就是数据库系统。
数据库系统:
- 建立在文件系统之上
- 负责组织把一些数据存到文件系统
- 对外的接口比较方便操作数据
设计数据库系统
scenario 场景
需求
- 查询:key(年龄 + 年级)
- 返回:value(姓名)
存储
数据库怎么存储?以表的形式?——并不是!
数据最终都会存到文件里面,是类似一种json格式的。
查询
在文件里面,如何更好地支持查询操作呢?
- 方法1:将全部文件存到内存里面,内存查询——内存根本放不下啊。
- 方法2:在硬盘的文件的基础上进行二分查找:每次拿出mid读到内存里。这涉及到GFS中的外排序。
修改
如果要修改一个东西,怎么操作呢?可能有三种方法:
- 直接在文件里修改 很难做到。如果原来是4个字节,现在修改成8个字节。那么修改之后还需要改动其它的位置。
- 读取整个文件,等改好了,重新写入覆盖原文件 非常耗费时间。每次都要读出写入。
- 不修改,直接将这条数据append在文件后面 这样写起来很快。如下图所示:
1 | 姓名:"a", 颜值:"5",身高:"160",时间:"1" |
但是读的时候没有顺序哇,就无法进行二分查找了!
解决方案:读的时候先扫旧的,然后再从append里面依次查找是否有修改后的内容。同时进行定期整理,以保证append的内容较少。
有没有一种方法,能即在读的时候二分查找,又能在写的时候append呢?—— 分块有序!
- 每一块都是内部有序
- 只有最后一块是无序的
如下所示:
1 | 姓名:"c", 颜值:"2",身高:"170",时间:"3" |
这样读和写相对来说就不会很慢了。但是问题来了,当块特别多的时候怎么办?—— 定期对有序块进行K路归并
完整的读写操作
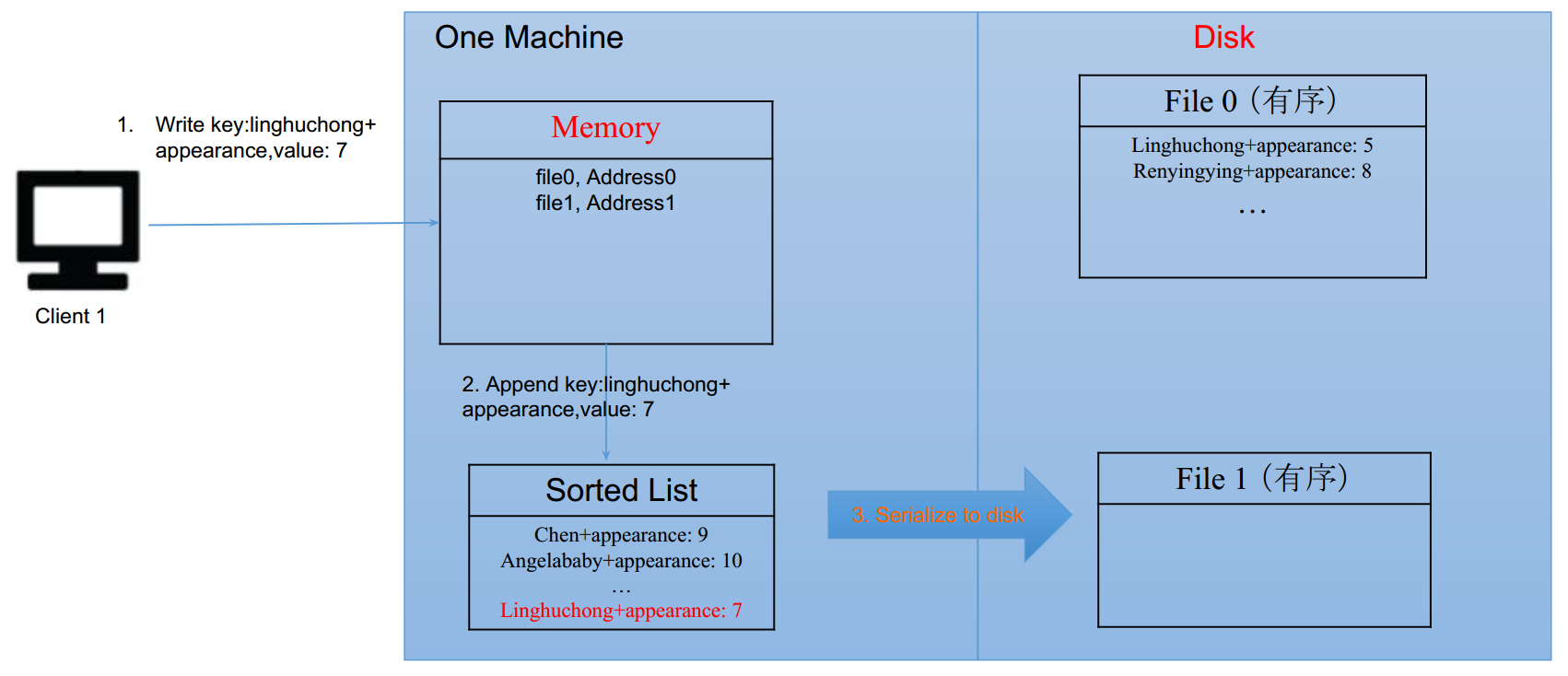
写入:
- 要将linghuchong的value写成7
- 给最后一个文件file1写入linghuchong+value=7
- 当file1满了的时候(例如256M),将file1搞成有序。排序方法有两种:
- 一开始就写到内存里——内存排序+1次硬盘写入
- 先写入文件,然后等满了的时候读入内存进行快排——1次硬盘读+内存排序+1次硬盘写
- 硬盘外部排序——有必要吗?并没有
如果一开始直接写入内存,然后满了之后写入硬盘。万一掉电了,岂不是gg?
可以将内存里的东西在硬盘里备份一份——write ahead log
读取:
- 要查找linghuchong的颜值是多少
- 在file0和file1中寻找linghuchong
- 在内存里找找有没有
- 找到一个时间戳最大的,认为是返回结果

一个File里面怎么查询令狐冲?
- 读出来for循环
- 硬盘二分
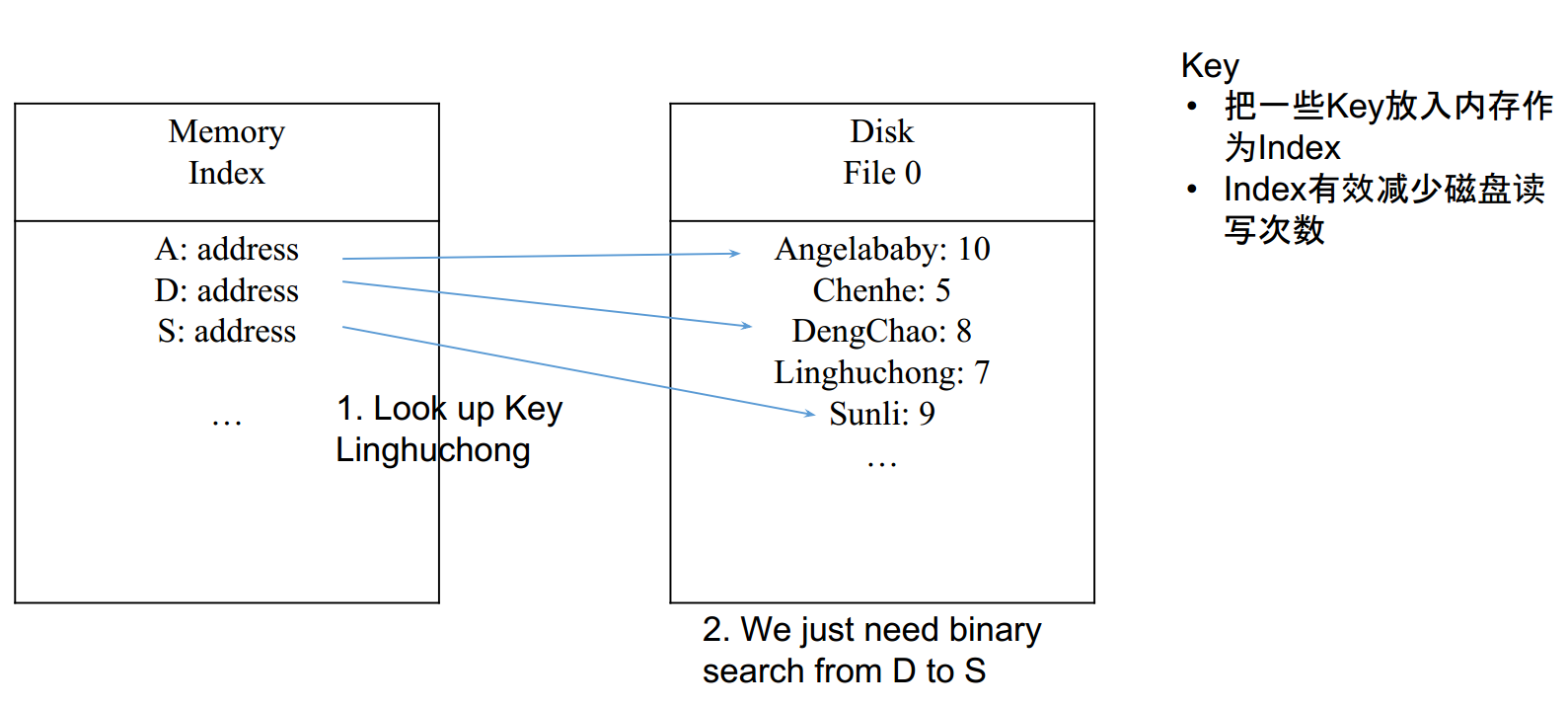
- 有木有更好的方法? —— 加index
最简单的index,在map中保存部分key:
有个题:intersection of two arrays II
有木有更好的方法检查一个key在不在一个File里面? 为什么要做如此多的读优化?——因为在写的时候做了Append优化,打乱了有序的性质,导致读的时候变慢,所以才会想办法加快读的速度。
BloomFilter
类似一个hash表。能快速看一个key在不在表里。
- 计算ling在hash表1里的hash值,hash1(ling) = 1
- 计算Ling在hash表2里的hash值,hash2(ling) = 2
- 将这两个值插入到下面数组里——1的位置改成1,2的位置改成1
- 同理,计算hu的两个hash值,分别是5和7。同时将这两个值插入到下面数组里——5和7的位置改成1
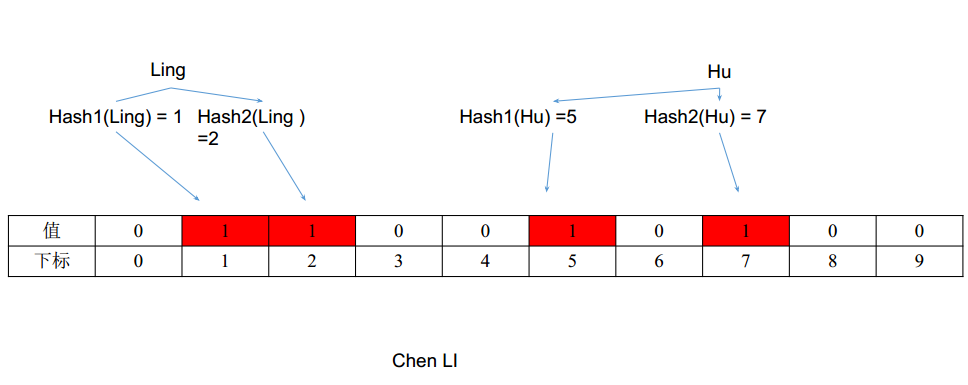
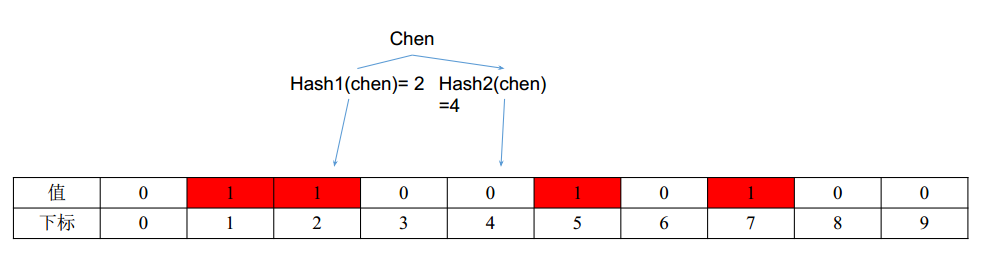
当要查询chen是不是在表里:
- 计算chen的两个hash值,算出来分别是2和4
- 发现位置2和4不全是1,因此chen这个单词肯定不在这个表里
- 如果2和4位置全是1,那么chen有可能在这个表里
Bloom Filter精确度跟什么有关?
- 哈希函数个数
- 位数组长度
- 加入的字符串数目
那么,读出过程就变成了:
- 每个file里面都有bloomfilter
- 想要查询linghuchong颜值是多少
- 先去内存里看看有没有linghuchong
- 看看每个file的bloomfilter,筛选这个里面有没有Linghuchong
- 如果没有,就直接跳过
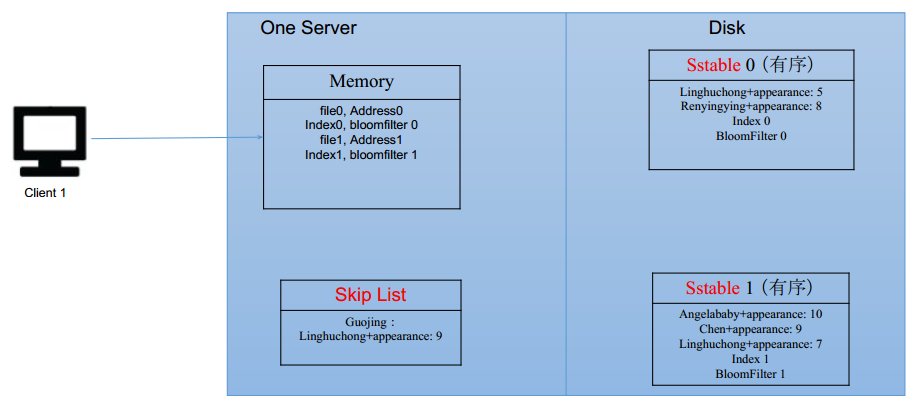
注意:sstable就是sorted string table
扩展
Sharding
如何从1pb的文件中读和写呢?
如果这张表张这样,那么怎么进行sharding?
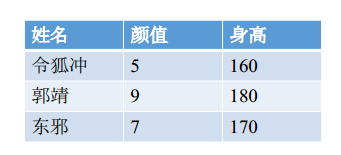
- 横向sharding——同一个人在同一个机器上
- 纵向sharding——同一个属性在同一个机器上
根据业务需求,一般取的时候会取到同一个人的所有属性,因此用横向sharding比较好:

如何管理?
Master Slave结构
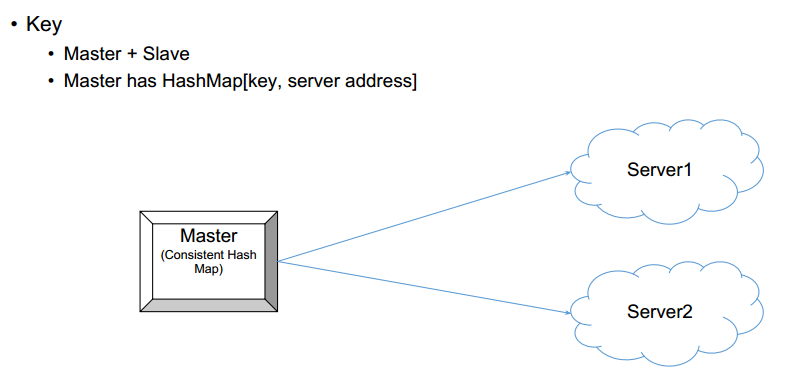
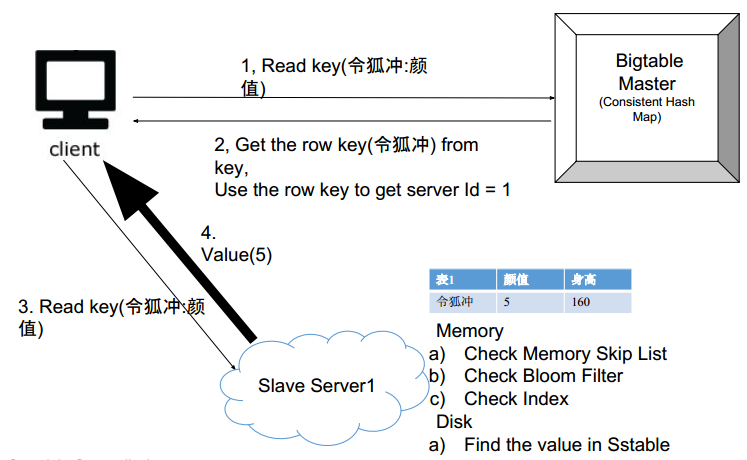
如何读?
- 问问master令狐冲在哪个机器
- master返回机器id
- client去id上查询:
- 看看内存里有没有
- 每个块进行bloomfilter检查
- 查询index
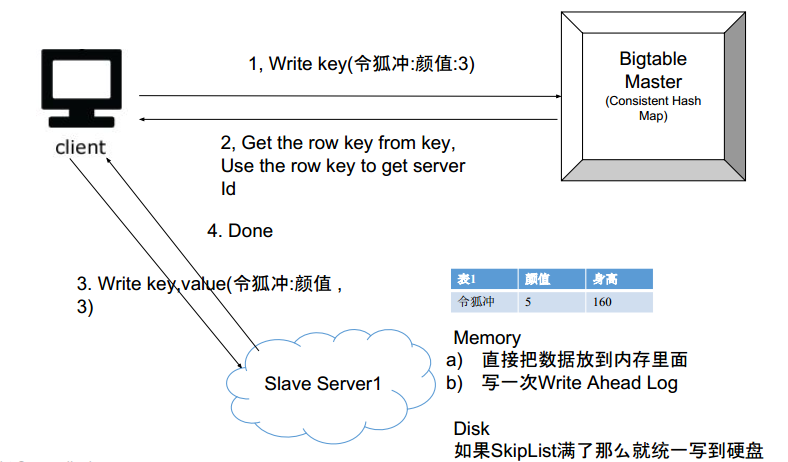
如何写?
- client问问master应该写去哪儿
- master返回机器id
- client去id上写入
- 将数据写到内存
- 同时写入write ahead log
- 如果内存满了,就统一写入硬盘
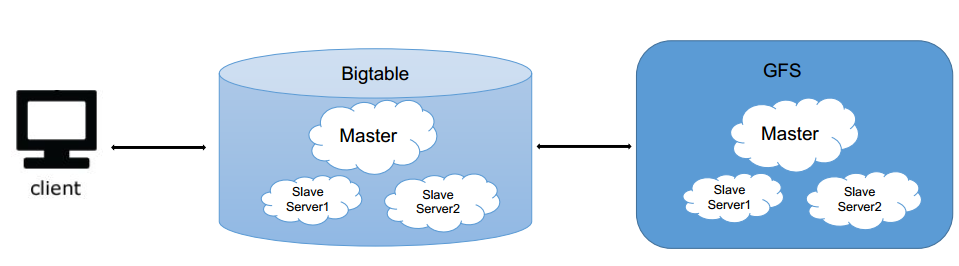
写不下了咋办?
可以把数据最终存到gfs里面(当slave满了的时候,再写到gfs里面),gfs有以下好处:
- 有disk size
- replica
- failure and recovery
sstable如何写到gfs里呢?
bigtable里面的存储单位是sstable,而gfs读写单位是chunk
那么就要把sstable拆成一个个的chunk,然后写入gfs
总结
