Elasticsearch 是一个分布式可扩展的实时搜索和分析引擎,一个建立在全文搜索引擎 Apache Lucene(TM) 基础上的搜索引擎.当然 Elasticsearch 并不仅仅是 Lucene 那么简单,它不仅包括了全文搜索功能,还可以进行以下工作:
- 分布式实时文件存储,并将每一个字段都编入索引,使其可以被搜索。
- 实时分析的分布式搜索引擎。
- 可以扩展到上百台服务器,处理PB级别的结构化或非结构化数据。
排序算法
检索过程
检索过程是搜索引擎接收用户的query进行一系列处理并返回相关结果的过程. 商业搜索引擎在检索过程中需要考虑2个因素: 1) 相关性 2) 重要性.
相关性是指返回结果和输入query是否相关, 这是搜索引擎基本问题之一, 目前常用的算法有BM25和空间向量模型. 这个两个算法ElasticSearch都支持, 一般商业搜索引擎都用BM25算法. BM25算法会计算每个doc和query的相关性分, 我们使用Dscore表示.
重要性是指商品被信赖的程度, 我们应该吧最被消费之信赖的商品返回给消费者, 而不是让消费之自己鉴别. 尤其是在商品充分竞争的电商搜索, 我们必须赋予商品合理的重要性分数, 才能保证搜索结果的优质. 重要性分, 又叫做静态分, 使用Tscore表示.
搜索引擎最终的排序依据是:
Score = Dscore * Tscore
即综合考虑静态分和动态分, 给用户相关且重要的商品.
检索的过程大致抽象为如下几个步骤.
step 1. 对原始query进行query分析 step 2. 在as中根据query分析结果进行query重写 step 3. 在as中使用重写后的query检索es step 4. 在es查询过程中根据静态分和动态分综合排序 step 5. 在as中吧es返回的结果进行重排 step 6. 返回结果
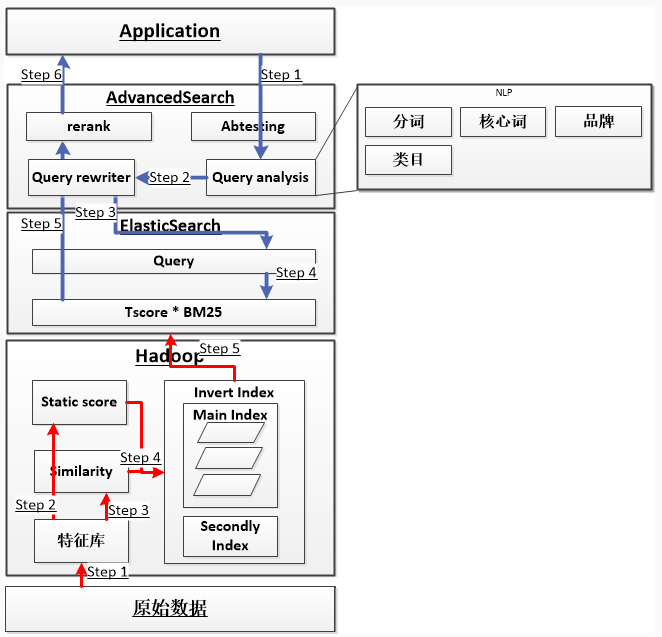
BM25
BM25(Best Match25)是在信息检索系统中根据提出的query对document进行评分的算法。它主要由Stephen E. Robertson, Karen Spärck Jones等人在上世纪70到80年代提出。BM25算法首先由Okapi系统实现(Okapi是伦敦城市大学实现的信息检索系统),所以又称为Okapi BM25。
BM25是一种BOW(bag-of-words)模型,BOW模型只考虑document中词频,不考虑句子结构或者语法关系之类,把document当做装words的袋子,具体袋子里面可以是杂乱无章的。准确的说,BM25并不是一个单一的函数,而是一个评分函数家族,一个最著名的版本如下,给定一个Query T(由关键词t1, t2, ..., tn组成),则一个文档 d 的BM25得分为:
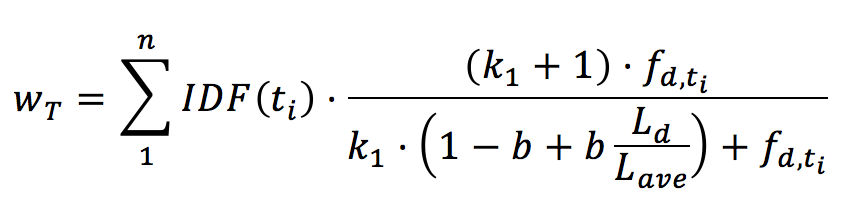
商品静态score计算技术
在电商搜索引擎里面商品的静态分是有网页搜索里面的pagerank同等的价值和重要性, 他们都是doc固有的和查询query无关的价值度量. pagerank通过doc之间的投票关系进行运算, 相对而言商品的静态分的因素会更多一些. 商品静态计算过程和pagerank一样需要解决如下2个问题: 1. 稳定性. pagerank可以保证一个网站不会因为简单链接堆砌可以线性提升网站的排名. 同样, 商品静态分的计算不可以让商品可以通过增加单一指标线性增加分值(比如刷单对搜索引擎的质量的影响). \2. 区分度. 在保证稳定性的基础上商品静态分要有足够的区分度可以保证同样搜索的条件下, 排在前面的商品的质量比排在后面的商品的质量高.
我们假设商品的静态分有3个决定性因素, 1.下单数, 2. 好评率 3. 发货速度
静态分我们使用Tsocre表示, Tscore可以写成如下形式:
Tscore = a * f(下单数) + b * g(好评率) + c * h(发货速度)
a,b,c是权重参数, 用于平衡各个指标的影响程度. f,g,h是代表函数用于把原始的指标转化成合理的度量.
首先, 我们需要寻找合理的代表函数.
- 首先对各个指标取log. log的导数是一个减函数, 表示为了获得更好的分数需要花费越来越多的代价.
- 标准化. 标准化的目的让各个度量可以在同一区间内进行比较. 比如下单数的取值是0~10000, 而好评率的取值为0~1. 这种情况会影响到数据分析的结果和方便性, 为了消除指标之间的量纲的影响, 需要进行数据标准化处理, 以解决数据指标之间的可比性.最常用的标准化方法是z-score标准化方法.
最后, 选择合适的权重 经过log-zscore归一化以后, 我们基本上吧f,g,h的表示的代表函数说明清楚. Tscore = af(下单数) + bg(好评率) + c*h(发货速度), 下一步就是确定a,b,c的参数. 一般有两个方法:
- 专家法. 根据我们的日常经验动态调整权重参数;
- 实验法. 首先在专家的帮助下赋一个初始值, 然后改变单一变量的方法根据abtest的结果来动态调整参数.
Others
。。。这里内容很多,详见参考文献1。。。今天心态崩了。。。看不进去了。。。
评价指标
准确率、召回率、F1
信息检索、分类、识别、翻译等领域两个最基本指标是召回率(Recall Rate)和准确率(Precision Rate),召回率也叫查全率,准确率也叫查准率,概念公式:
召回率(Recall) = 系统检索到的相关文件 / 系统所有相关的文件总数
准确率(Precision) = 系统检索到的相关文件 / 系统所有检索到的文件总数
Tips:准确率和召回率是互相影响的,理想情况下肯定是做到两者都高,但是一般情况下准确率高、召回率就低,召回率低、准确率高,当然如果两者都低,那是什么地方出问题了。 一般情况,用不同的阀值,统计出一组不同阀值下的精确率和召回率,如下图:
如果是做搜索,那就是保证召回的情况下提升准确率;如果做疾病监测、反垃圾,则是保准确率的条件下,提升召回。
所以,在两者都要求高的情况下,可以用F1来衡量:
F1 = 2 * P * R / (P + R)
mAP(mean Averate Precision)
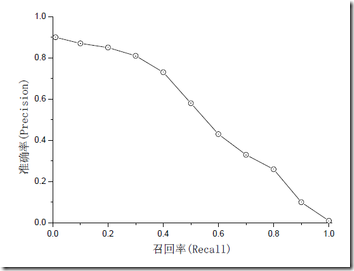
mAP是为解决P,R,F-measure的单点值局限性的。为了得到 一个能够反映全局性能的指标,可以看考察下图,其中两条曲线(方块点与圆点)分布对应了两个检索系统的准确率-召回率曲线。
可以看出,虽然两个系统的性能曲线有所交叠但是以圆点标示的系统的性能在绝大多数情况下要远好于用方块标示的系统。从中我们可以 发现一点,如果一个系统的性能较好,其曲线应当尽可能的向上突出。
更加具体的,曲线与坐标轴之间的面积应当越大。
最理想的系统, 其包含的面积应当是1,而所有系统的包含的面积都应当大于0。这就是用以评价信息检索系统的最常用性能指标,平均准确率mAP其规范的定义如下:(其中P,R分别为准确率与召回率,Q为检索次数)
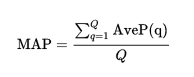
文件存储
Elasticsearch是面向文档型数据库,一条数据在这里就是一个文档,用JSON作为文档序列化的格式,比如下面这条用户数据:
1 |
|
倒排索引
Elasticsearch分别为每个field都建立了一个倒排索引,Kate, John, 24, Female这些叫term,而[1,2]就是Posting List。Posting list就是一个int的数组,存储了所有符合某个term的文档id。
1 | | Term | Posting List | |
Term Dictionary
Elasticsearch为了能快速找到某个term,将所有的term排个序,二分法查找term,logN的查找效率,就像通过字典查找一样,这就是Term Dictionary。现在再看起来,似乎和传统数据库通过B-Tree的方式类似啊,为什么说比B-Tree的查询快呢?
Term Index
B-Tree通过减少磁盘寻道次数来提高查询性能,Elasticsearch也是采用同样的思路,直接通过内存查找term,不读磁盘,但是如果term太多,term dictionary也会很大,放内存不现实,于是有了Term Index,就像字典里的索引页一样,A开头的有哪些term,分别在哪页,可以理解term index是一颗树:
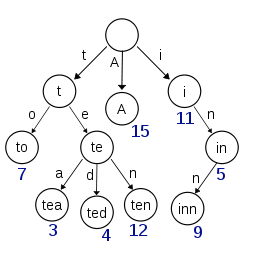
这棵树不会包含所有的term,它包含的是term的一些前缀。通过term index可以快速地定位到term dictionary的某个offset,然后从这个位置再往后顺序查找。

所以term index不需要存下所有的term,而仅仅是他们的一些前缀与Term Dictionary的block之间的映射关系,再结合FST(Finite State Transducers)的压缩技术,可以使term index缓存到内存中。从term index查到对应的term dictionary的block位置之后,再去磁盘上找term,大大减少了磁盘随机读的次数。