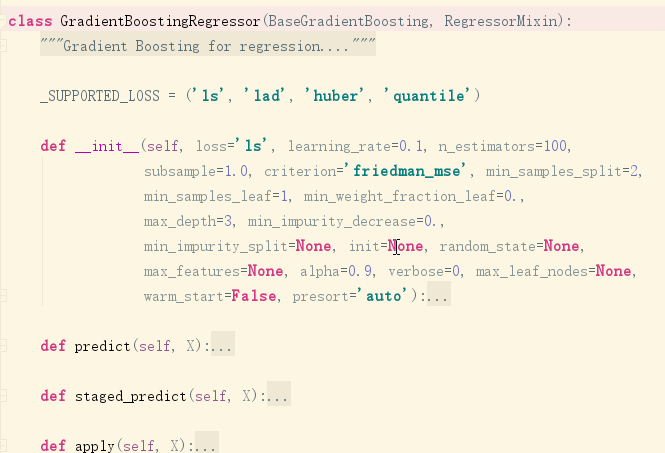
defpredict(self, X): """Predict regression target for X. Parameters ---------- X : array-like or sparse matrix, shape = [n_samples, n_features] The input samples. Internally, it will be converted to ``dtype=np.float32`` and if a sparse matrix is provided to a sparse ``csr_matrix``. Returns ------- y : array of shape = [n_samples] The predicted values. """ X = check_array(X, dtype=DTYPE, order="C", accept_sparse='csr') return self._decision_function(X).ravel()
# fit initial model - FIXME make sample_weight optional self.init_.fit(X, y, sample_weight)
# init predictions y_pred = self.init_.predict(X) begin_at_stage = 0 else: # add more estimators to fitted model # invariant: warm_start = True if self.n_estimators < self.estimators_.shape[0]: raise ValueError('n_estimators=%d must be larger or equal to ' 'estimators_.shape[0]=%d when ' 'warm_start==True' % (self.n_estimators, self.estimators_.shape[0])) begin_at_stage = self.estimators_.shape[0] y_pred = self._decision_function(X) self._resize_state() # ============= 对特征预排序 ============ X_idx_sorted = None presort = self.presort # Allow presort to be 'auto', which means True if the dataset is dense, # otherwise it will be False. if presort == 'auto'and issparse(X): presort = False elif presort == 'auto': presort = True
if presort == True: if issparse(X): raise ValueError("Presorting is not supported for sparse matrices.") else: X_idx_sorted = np.asfortranarray(np.argsort(X, axis=0), dtype=np.int32) # ============= 训练 ======================== # fit the boosting stages n_stages = self._fit_stages(X, y, y_pred, sample_weight, random_state, begin_at_stage, monitor, X_idx_sorted) # change shape of arrays after fit (early-stopping or additional ests) if n_stages != self.estimators_.shape[0]: self.estimators_ = self.estimators_[:n_stages] self.train_score_ = self.train_score_[:n_stages] ifhasattr(self, 'oob_improvement_'): self.oob_improvement_ = self.oob_improvement_[:n_stages]
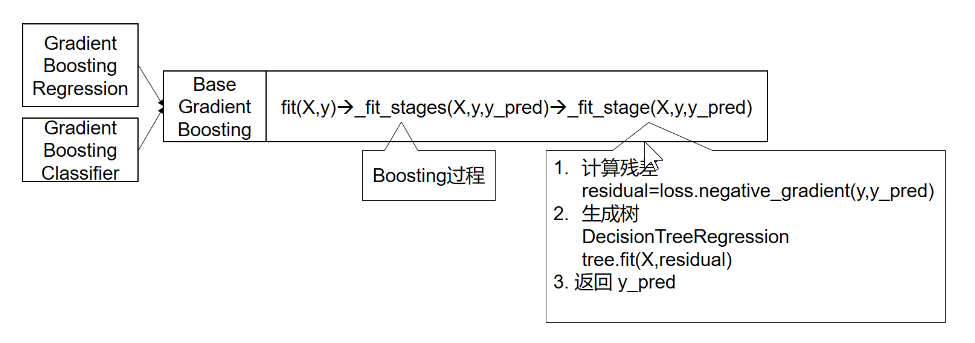
def_fit_stages(self, X, y, y_pred, sample_weight, random_state, begin_at_stage=0, monitor=None, X_idx_sorted=None): """Iteratively fits the stages. For each stage it computes the progress (OOB, train score) and delegates to ``_fit_stage``. Returns the number of stages fit; might differ from ``n_estimators`` due to early stopping. """ # ============== 初始化 ============================= n_samples = X.shape[0] do_oob = self.subsample < 1.0 sample_mask = np.ones((n_samples, ), dtype=np.bool) n_inbag = max(1, int(self.subsample * n_samples)) loss_ = self.loss_
# Set min_weight_leaf from min_weight_fraction_leaf if self.min_weight_fraction_leaf != 0.and sample_weight isnotNone: min_weight_leaf = (self.min_weight_fraction_leaf * np.sum(sample_weight)) else: min_weight_leaf = 0.
if self.verbose: verbose_reporter = VerboseReporter(self.verbose) verbose_reporter.init(self, begin_at_stage)
X_csc = csc_matrix(X) if issparse(X) elseNone X_csr = csr_matrix(X) if issparse(X) elseNone # =========== 树迭代!===================== # perform boosting iterations i = begin_at_stage for i inrange(begin_at_stage, self.n_estimators): # subsampling,采样 if do_oob: sample_mask = _random_sample_mask(n_samples, n_inbag, random_state) # OOB score before adding this stage old_oob_score = loss_(y[~sample_mask], y_pred[~sample_mask], sample_weight[~sample_mask])
# fit next stage of trees y_pred = self._fit_stage(i, X, y, y_pred, sample_weight, sample_mask, random_state, X_idx_sorted, X_csc, X_csr)
# track deviance (= loss) if do_oob: self.train_score_[i] = loss_(y[sample_mask], y_pred[sample_mask], sample_weight[sample_mask]) self.oob_improvement_[i] = ( old_oob_score - loss_(y[~sample_mask], y_pred[~sample_mask], sample_weight[~sample_mask])) else: # no need to fancy index w/ no subsampling self.train_score_[i] = loss_(y, y_pred, sample_weight)
if self.verbose > 0: verbose_reporter.update(i, self)
if monitor isnotNone: early_stopping = monitor(i, self, locals()) if early_stopping: break return i + 1
为了方便看,我们把迭代部分的主要代码抽出来:
1 2 3 4 5 6 7 8 9
for i inrange(begin_at_stage, self.n_estimators):
# fit next stage of trees y_pred = self._fit_stage(i, X, y, y_pred, sample_weight, sample_mask, random_state, X_idx_sorted, X_csc, X_csr)
def_fit_stage(self, i, X, y, y_pred, sample_weight, sample_mask, random_state, X_idx_sorted, X_csc=None, X_csr=None): """Fit another stage of ``n_classes_`` trees to the boosting model. """
assert sample_mask.dtype == np.bool loss = self.loss_ original_y = y # k代表类别个数! for k inrange(loss.K): if loss.is_multi_class: y = np.array(original_y == k, dtype=np.float64)
def_fit_stage(self, i, X, y, y_pred, sample_weight, sample_mask, random_state, X_idx_sorted, X_csc=None, X_csr=None): """Fit another stage of ``n_classes_`` trees to the boosting model. """
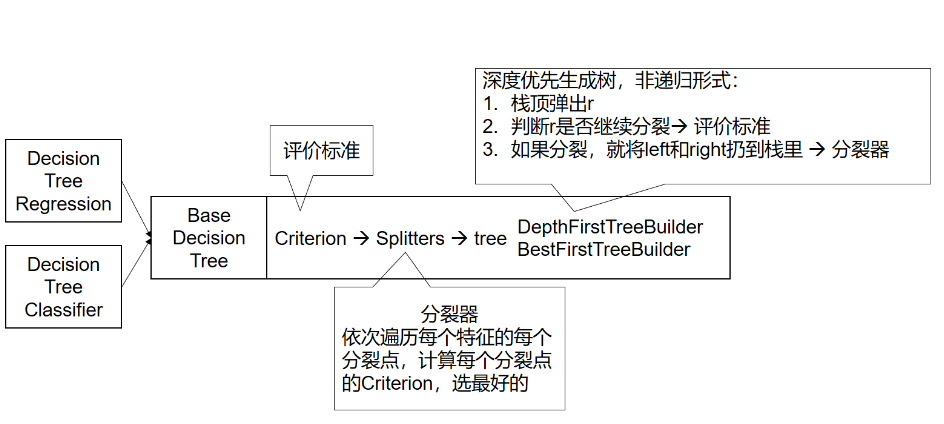
assert sample_mask.dtype == np.bool loss = self.loss_ original_y = y for k inrange(loss.K): # ======== 计算损失函数的负梯度(残差) residual = loss.negative_gradient(y, y_pred, k=k, sample_weight=sample_weight) # ======= 迭代一颗树 # induce regression tree on residuals tree = DecisionTreeRegressor( criterion=self.criterion, splitter='best', max_depth=self.max_depth, min_samples_split=self.min_samples_split, min_samples_leaf=self.min_samples_leaf, min_weight_fraction_leaf=self.min_weight_fraction_leaf, min_impurity_decrease=self.min_impurity_decrease, min_impurity_split=self.min_impurity_split, max_features=self.max_features, max_leaf_nodes=self.max_leaf_nodes, random_state=random_state, presort=self.presort)
loss.update_terminal_regions(tree.tree_, X, y, residual, y_pred, sample_weight, sample_mask, self.learning_rate, k=k) # add tree to ensemble self.estimators_[i, k] = tree return y_pred
while p < end: p += 1 if p < end: current.pos = p # Reject if min_samples_leaf is not guaranteed # 如果当前分割点分割后,左右节点个数过少,就跳过 if (((current.pos - start) < min_samples_leaf) or ((end - current.pos) < min_samples_leaf)): continue # 计算当前节点分割点的评价标准 self.criterion.update(current.pos)
# Reject if min_weight_leaf is not satisfied if ((self.criterion.weighted_n_left < min_weight_leaf) or (self.criterion.weighted_n_right < min_weight_leaf)): continue current_proxy_improvement = self.criterion.proxy_impurity_improvement() # 选择最好收益的作为当前分割点 if current_proxy_improvement > best_proxy_improvement: best_proxy_improvement = current_proxy_improvement # sum of halves is used to avoid infinite value current.threshold = Xf[p - 1] / 2.0 + Xf[p] / 2.0
if ((current.threshold == Xf[p]) or (current.threshold == INFINITY) or (current.threshold == -INFINITY)): current.threshold = Xf[p - 1]