publicinterfaceProducerextendsMessageFactory, ServiceLifecycle{ /*返回本实例的properties*/ /*返回值的变化不会反应在Producer本身上,并且这个变化可以用ResourceManager#setProducerProperties(String, KeyValue)来修改。(Changes to the return {@code KeyValue} are not reflected in physical {@code Producer},and use {@link ResourceManager#setProducerProperties(String, KeyValue)} to modify.)*/ KeyValue properties();
publicinterfacePullConsumer{ /*返回本PullConsumer实例的properties*/ /* Changes to the return {@code KeyValue} are not reflected in physical {@code PullConsumer},and use {@link ResourceManager#setConsumerProperties(String, KeyValue)} to modify.*/ KeyValue properties();
publicclassSecondThreadimplementsRunnable{ publicvoidrun(){ System.out.println("run\t"+Thread.currentThread().getName()+"\t");//getName()返回thread name } publicstaticvoidmain(String[] args){ SecondThread st = new SecondThread(); new Thread(st,"new_thread_1").start(); } }
publicclassSecondThreadimplementsRunnable{ privateint i; publicvoidrun(){ while(i<5){ System.out.println("run\t"+Thread.currentThread().getName()+"\t"+i);//getName()返回thread name i++; } } publicstaticvoidmain(String[] args){ SecondThread st = new SecondThread(); new Thread(st,"thread_name_1").start(); new Thread(st,"thread_name_2").start(); } }
两次运行结果:
run thread_name_1 0
run thread_name_1 1
run thread_name_1 2
run thread_name_1 3
run thread_name_2 3
run thread_name_1 4
run thread_name_1 0
run thread_name_2 0
run thread_name_1 1
run thread_name_2 2
run thread_name_1 3
run thread_name_2 4
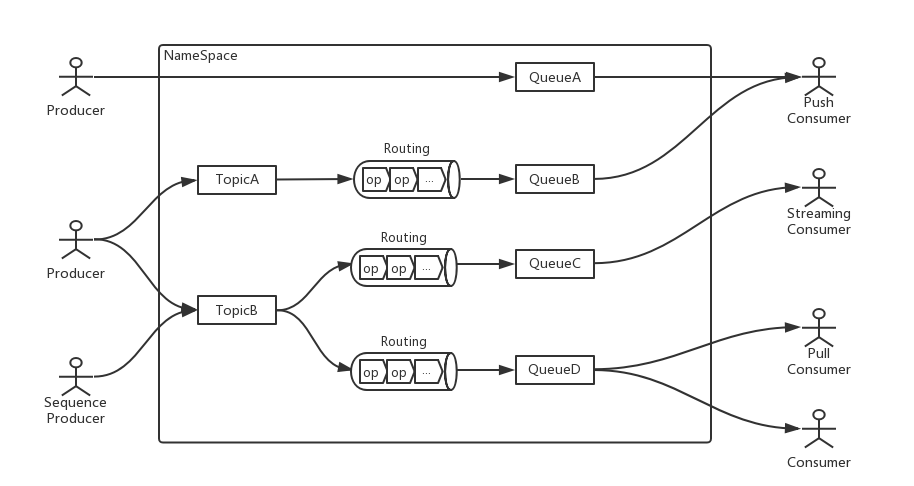
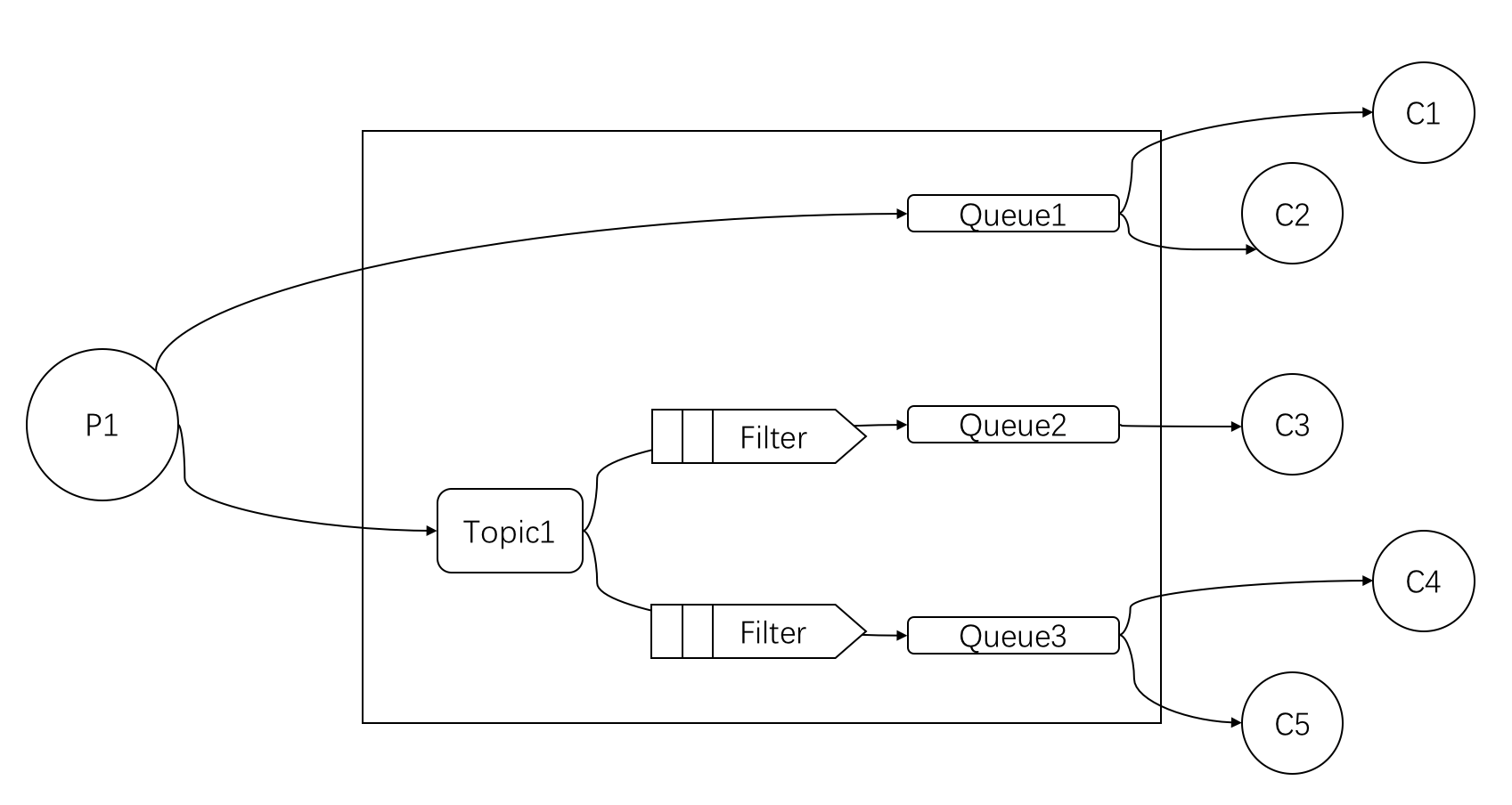
 生产者和消费者通常有两种对应关系,一个生产者对应一个消费者,以及一个生产者对应多个消费者。
生产者和消费者通常有两种对应关系,一个生产者对应一个消费者,以及一个生产者对应多个消费者。