本文是吴恩达老师的课程总结。主要参考了大树先生和PilgrimHui 的笔记。如有不当之处,还请各位指出。
本课程附带编程作业。本文的编程作业有:
实现浅层神经网络 :深度学习实践-1-3-构建浅层神经网络
实现深层神经网络: 深度学习实践-1-4-1-构建深层神经网络
用神经网络做猫脸识别:深度学习实践-1-4-2-用神经网络识别猫
待续
神经网络概念
所谓神经网络就是将许多个单一“神经元”联结在一起,这样,一个“神经元”的输出就可以是另一个“神经元”的输入。神经网络就是按照一定规则将多个神经元连接起来的网络。
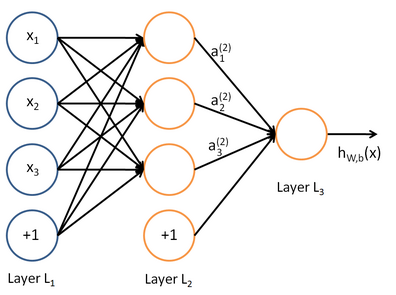 我们使用圆圈来表示神经网络的输入,标上“+1”的圆圈被称为偏置节点,也就是截距项。神经网络最左边的一层叫做输入层,最右的一层叫做输出层(本例中,输出层只有一个节点)。中间所有节点组成的一层叫做隐藏层,因为我们不能在训练样本集中观测到它们的值。同时可以看到,以上神经网络的例子中有3个输入单元(偏置单元不计在内),3个隐藏单元及一个输出单元。
我们使用圆圈来表示神经网络的输入,标上“+1”的圆圈被称为偏置节点,也就是截距项。神经网络最左边的一层叫做输入层,最右的一层叫做输出层(本例中,输出层只有一个节点)。中间所有节点组成的一层叫做隐藏层,因为我们不能在训练样本集中观测到它们的值。同时可以看到,以上神经网络的例子中有3个输入单元(偏置单元不计在内),3个隐藏单元及一个输出单元。
记: \(a^{[0]} = X\),表示输入特征,也表示“acitive value” \(a^{[1]}\),表示隐藏层的“active value” \(a^{[2]} = y^{\text{~}}\),表示输出层
刚才提到的是一种最简单的神经网络,叫深度前馈(feedforword)网络,又称前馈神经网络、多层感知机,是典型的深度学习模型。
前馈网络的目标是近似某个函数\(f^*(x)\),将输入\(x\)映射到输出\(y\)。
而映射$ f(x;)\(,并且学习参数\)\(的值,使它能够得到最佳函数\)f^*(x) $的近似。
前馈是因为没有反馈连接。如果有反馈的话,叫循环(recurrent)神经网络。
全连接:第N层的每个神经单元和第N-1层的所有神经元相连。
浅层神经网络
上面简单地介绍了神经网络的构造。我们首先从浅层神经网络开始看起,看看如何通过样本学习到一个模型,然后用这个模型对新的样本进行预测。
那么我们就需要解决两个问题:
如何通过x+模型 --> 计算y'
1
2
3
4
5---------------------------------------
--> | |
x --> | 神经网络 | ---> 得到预测的y'
--> | |
---------------------------------------如何通过x + y --> 计算模型
1
2
3
4
5-------------------------------------------
--> | |
x + y --> | 前向+反向 | ---> 得到网络参数w,b
--> | |
--------------------------------------------首先我们来解决第一个问题,如何计算输出。
如何计算输出?
首先,我们回顾最简单的LR单元如何计算输出: 1. 首先计算\(z = w^Tx+b\); 2. 代入激活函数计算\(a = a(z)\) 3. 得到预测值\(a = y^{\text ~}\)
在神经网络中,我们以此计算每个神经元即可。
为了方便表示,我们先约定符号: \[a_{i\text{<- node index in layer}}^{[j]\text{<- layer index}}\]
上标方括号表示层数;下标表示在本层的第几个node。
因此,在神经网络中,我们计算以下即可: 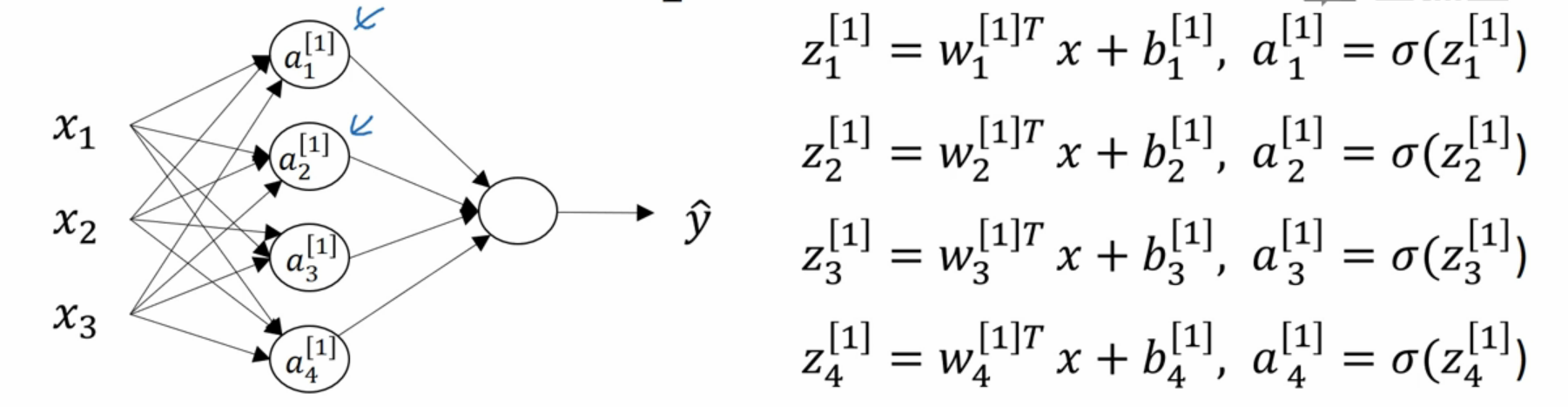
即依次计算z和a即可。
我们将上面的计算过程向量化,得到: \[ z^{[1]} = \begin{bmatrix} w_1^{[1]T}\\ w_2^{[1]T}\\ w_3^{[1]T} \\ \end{bmatrix} \begin{bmatrix} x_1\\ x_2\\ x_3\\ \end{bmatrix} +\begin{bmatrix} b_1^{[1]}\\ b_2^{[1]}\\ b_3^{[1]} \\ \end{bmatrix} \] \[=\begin{bmatrix} w_1^{[1]T}x+b_1^{[1]}\\ w_2^{[1]T}x+b_2^{[1]}\\ w_3^{[1]T}x+b_3^{[1]} \\ \end{bmatrix} =\begin{bmatrix} z_1^{[1]}\\ z_2^{[1]}\\ z_3^{[1]} \\ \end{bmatrix} \]
而这一层得到的输出\(a\)作为下一层的输入\(x\)
因此在神经网络中,我们按照以下步骤计算: 
我们将上面的计算步骤叫作前向传播。即:给定第\(l\)层激活值\(a^{[l]}\),第\(l+1\)层的激活值\(a^{[l+1]}\)可以按照以下步骤得到: \(z^{[l+1]} = w^{[l]}a^{[l]}+b^{[l]}\) \(a^{[l+1]} = a(z^{[l+1]})\)
向量化-加速多样本计算
在上一节中,我们讲到我们的输出是依次计算的。即从\(x^{(1)}\)到\(x^{(m)}\)
假设输入样本\(X\)有m个,那么我们的计算过程为: \(x^{(1)} \text{ ----------> } a^{[l]\text{(1)}} = y^{\text{~(1)}}\) ... \(x^{(i)} \text{ ----------> } a^{[l]\text{(i)}} = y^{\text{~(i)}}\) ... \(x^{(m)} \text{ ----------> } a^{[l]\text{(m)}} = y^{\text{~(m)}}\)
同样的,我们也可以将这个过程向量化,只需要将m个样本放入一个大矩阵\(X\)中即可。此处对于我来说较容易理解,故不再多加阐述。
激活函数
回顾之前的内容,我们的网络为: 1. 计算\(z = wx+b\) 2. 将\(z\)代入激活函数\(\sigma(z)\)得到预测值
其中的\(\sigma = \frac{1}{1+e^{-z}}\)就是sigmod激活函数。当然也有其它的激活函数:
- \(tanh\)(在神经网络隐藏层,\(tanh\)比\(\sigma\)表现更佳) \(tanh(z) = \frac{e^z-e^{-z}}{e^z+e^{-z}}\)
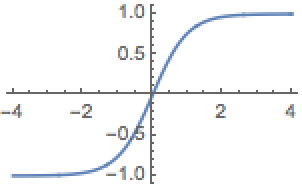
- \(ReLU\)-修正线性单元,更普遍 \(a=max(0,z)\) 学习速度很快
- 带泄露的ReLU \(a=max(0.0001z,z)\) z小于零时,函数稍微倾斜一些
为什么需要激活函数?
会导致输出结果就是输入特征的线性组合,导致网络并没有什么卵用。
如何计算参数?
接下来我们来解决第二个问题:
如何通过x + y --> 计算模型
1 | ------------------------------------------- |
这个过程我们主要由两部分构成:
- 正向传播,通过现有的网络计算输出y‘,然后计算损失函数L
- 反向传播,通过损失函数L,计算参数对L的导数dL/dw和dL/db,然后得到新的w和b。回到第1步。
正向传播
我的理解是:正向传播就是从输入计算输出的过程,也就是我们常说的进行预测。也就是我们现在已经有了一个模型,只需要把输入喂进去,然后得到的输出就是预测值。
- \(z^{[1]}=w^{[1]}x+b^{[1]}\)
- \(A^{[1]}=g^{[1]}(z^{[1]})\)该层的激活函数
- \(z^{[2]}=w^{[2]}A^{[1]}+B^{[2]}\)
- \(A^{[2]}=g^{[2]}(^{[2]})=\sigma(z^{[2]})\)
反向传播
上述正向传播时我们假设我们已经有了一个模型。但事实上我们应该是已经有了一堆样本想和样本的y,我们想去学习这个模型。那如何进行模型学习呢?就要用到反向传播法,从已知的输出y出发,结合梯度下降,得到一个模型,使得这个模型最符合x的分布。
反向传播算法其实指的是用于计算梯度的方法。而梯度下降是使用这个计算好了的梯度来进行学习的方法。
具体过程的思想精华:在样本集下,想要得到各层的z=wx+b的参数w和b,使得损失函数L(a,y)最小。用梯度下降法的话,就要沿着\(L(a,y)\)导数的方向来调节w和b。
关于误差函数\(L(a,y)\)我会在之后的博客误差函数探究里进行叙述。
要计算\(L(a,y)\)的导数\(\frac{dL(a,y)}{da}=-\frac{y}{a} + \frac{1-y}{1-a}\),那么就要计算\(dz=\frac{dL}{dz}\),从而要计算\(dw=\frac{dL}{dw}\)和\(db=\frac{dL}{db}\)
- \(dz^{[2]}=A^{[2]}-Y,Y=[y^{[1]}],y^{[2]},...,y^{[m]}\)
- \(dw^{[2]}=\frac{1}{m}dz^{[2]}A^{[1]T}\)
- \(db^{[2]}=\frac{1}{m}sum(dz^{[2]},axis=1,keepdims=True)\)
- \(dz^{[1]}=w^{[2]T}dz^{[2]} \times g^{[1]'}(z^{[1]})\)
- \(dw^{[1]}=\frac{1}{m}dz^{[1]}X^T\)
- \(db^{[1]}=\frac{1}{m}np.sum(dz^{[1]},axis=1,keepdims=True)\)
深度神经网络
上面介绍完了浅层神经网络。接下来我们看看深度神经网络是怎样计算的。
深度神经网络的好处
人脸识别和语音识别
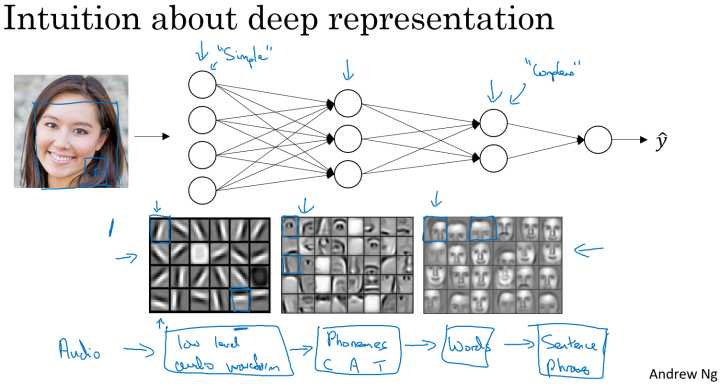
对于人脸识别,神经网络的第一层从原始图片中提取人脸的轮廓和边缘,每个神经元学习到不同边缘的信息;网络的第二层将第一层学得的边缘信息组合起来,形成人脸的一些局部的特征,例如眼睛、嘴巴等;后面的几层逐步将上一层的特征组合起来,形成人脸的模样。随着神经网络层数的增加,特征也从原来的边缘逐步扩展为人脸的整体,由整体到局部,由简单到复杂。层数越多,那么模型学习的效果也就越精确。
对于语音识别,第一层神经网络可以学习到语言发音的一些音调,后面更深层次的网络可以检测到基本的音素,再到单词信息,逐渐加深可以学到短语、句子。
所以从上面的两个例子可以看出随着神经网络的深度加深,模型能学习到更加复杂的问题,功能也更加强大。
电路逻辑计算
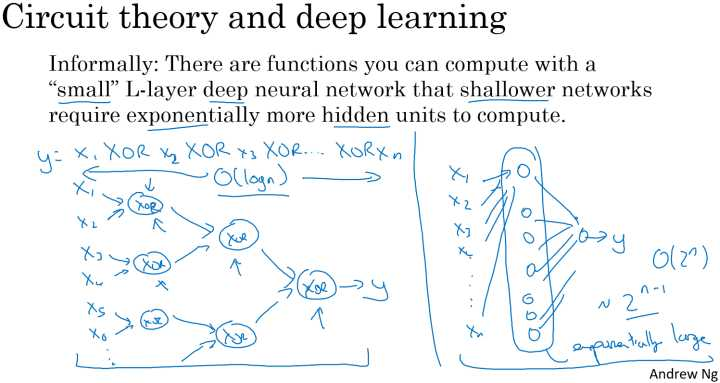
假定计算异或逻辑输出:
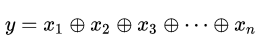
对于该运算,若果使用深度神经网络,每层将前一层的相邻的两单元进行异或,最后到一个输出,此时整个网络的层数为一个树形的形状,网络的深度为 ,共使用的神经元的个数为:
即输入个数为n,输出个数为n-1。
但是如果不适用深层网络,仅仅使用单隐层的网络(如右图所示),需要的神经元个数为 个 。同样的问题,但是深层网络要比浅层网络所需要的神经元个数要少得多。
前向传播和反向传播
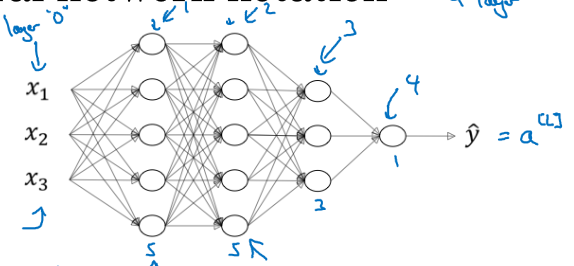
规定以下符号:
- \(L\):DNN的层数
- \(n^{[l]}\):第\(l\)层的包含的单元个数
- \(a^{[l]}\):第\(l\)层激活函数的输出
- \(W^{l}\):第\(l\)层的参数
- 输入\(x\)记为\(a^{[0]}\)。输出\(y'\)记为\(a^{[L]}\)
总体框架
深层网络的前向传播和反向传播的总体框架如下:
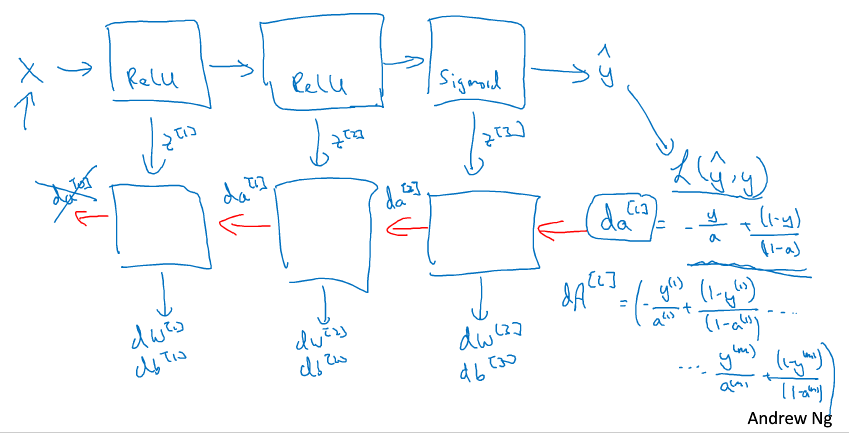
- 输入X
- 通过一层层的计算\(a^{[l]}=g^{[l]}(w^{[l]}\cdot a^{[l-1]}+b^{[l]})\),得到最终的\(y'\)——前向传播
- 通过\(y'\)计算损失\(L(y',y)\),计算出\(da^{[l]}\)——反向传播1
- 通过\(da^{[l]}\)计算\(da^{[l-1]}\),然后通过每层的\(da^{[l]}\)计算本层的\(dw^{[l]}\)和\(db^{[l]}\)——反向传播2
- 然后再返回第2步,进行迭代
前向传播
输入:\(a^{[l-1]}\)
输出:\(a^{[l]}\)和临时变量\(cache(z^{[l]})\)
计算:
\[z^{[l]}=w^{[l]}\cdot a^{[l-1]}+b^{[l]}\]
\[a^{[l]}=g^{[l]}(z^{[l]})\]
反向传播
输入:\(da^{[l]}\)
输出:\(dw^{[l]},db^{[l]},da^{[l-1]}\)
计算\(dz^{[l]}\):
\[dz^{[l]}=\frac{dL}{dz^{[l]}}=\frac{dL}{da^{[l]}}\cdot \frac{dL}{d^{[l]}}=\frac{dL}{da^{[l]}}\cdot g^{[l]'}(z^{[l]}) = da^{[l]}\cdot g^{[l]'}(z^{[l]})\]
计算\(dw^{[l]}\):
\[dw^{[l]}=\frac{dL}{dw^{[l]}}=\frac{dL}{dz^{[l]}}*\frac{dz^{[l]}}{dw^{[l]}}=\frac{dL}{dz^{[l]}}\cdot a^{[l-1]}=dz \cdot a^{[l-1]}\]
计算\(db^{[l]}\):
\[db^{[l]}=\frac{dL}{db^{[l]}}=\frac{dL}{dz^{[l]}}*\frac{dz^{[l]}}{db^{[l]}}=\frac{dL}{dz^{[l]}}=dz^{[l]}\]
计算\(da^{[l-1]}\):
\[da^{[l-1]}=\frac{dL}{da^{[l-1]}}=\frac{dL}{dz^{[l]}}\cdot \frac{dz^{[l]}}{da^{[l-1]}}=dz^{[l]}\cdot w^{[l]}\]
改善深层神经网络
训练、验证、测试集
对于一个需要解决的问题的样本数据,在建立模型的过程中,我们会将问题的data划分为以下几个部分:
- 训练集(train set):用训练集对算法或模型进行训练过程;
- 验证集(development set):利用验证集或者又称为简单交叉验证集(hold-out cross validation set)进行交叉验证,选择出最好的模型;
- 测试集(test set):最后利用测试集对模型进行测试,获取模型运行的无偏估计。
小数据时代
在小数据量的时代,如:100、1000、10000的数据量大小,可以将data做以下划分:
- 无验证集的情况:70% / 30%;
- 有验证集的情况:60% / 20% / 20%;
通常在小数据量时代,以上比例的划分是非常合理的。
大数据时代
但是在如今的大数据时代,对于一个问题,我们拥有的data的数量可能是百万级别的,所以验证集和测试集所占的比重会趋向于变得更小。
验证集的目的是为了验证不同的算法哪种更加有效,所以验证集只要足够大能够验证大约2-10种算法哪种更好就足够了,不需要使用20%的数据作为验证集。如百万数据中抽取1万的数据作为验证集就可以了。
测试集的主要目的是评估模型的效果,如在单个分类器中,往往在百万级别的数据中,我们选择其中1000条数据足以评估单个模型的效果。
- 100万数据量:98% / 1% / 1%;
- 超百万数据量:99.5% / 0.25% / 0.25%(或者99.5% / 0.4% / 0.1%)
Notation
- 建议验证集要和训练集来自于同一个分布,可以使得机器学习算法变得更快;
- 如果不需要用无偏估计来评估模型的性能,则可以不需要测试集。
偏差、方差
对于下图中两个类别分类边界的分割:
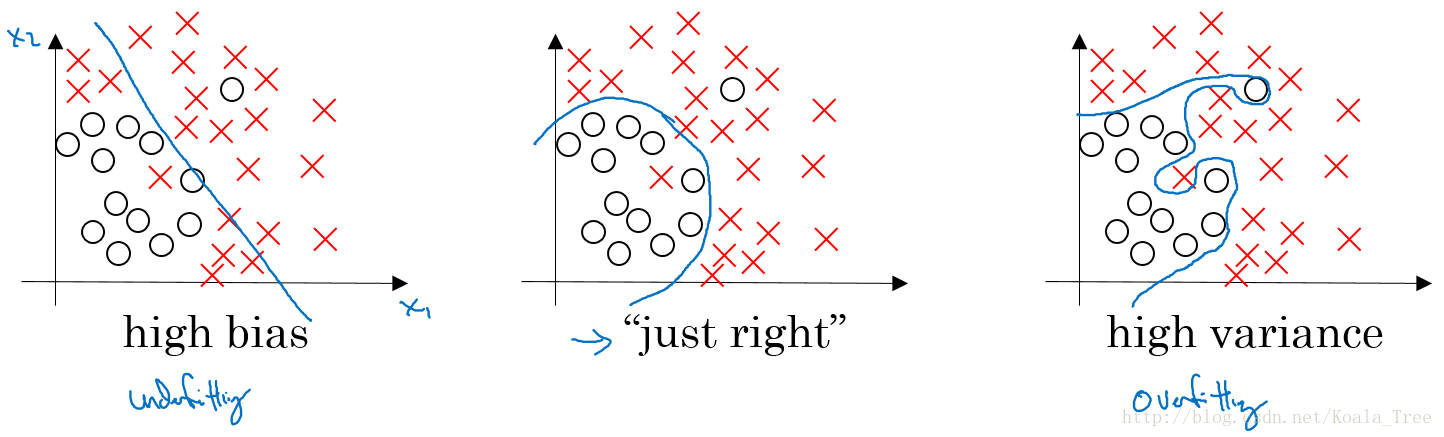
从图中我们可以看出:
- 欠拟合(underfitting)的情况下,出现高偏差(high bias)的情况;
- 过拟合(overfitting)的情况下,出现高方差(high variance)的情况。
在bias-variance tradeoff 的角度来讲,我们利用训练集对模型进行训练就是为了使得模型在train集上使 bias(偏差) 最小化,避免出现underfitting的情况;
但是如果模型设置的太复杂,虽然在train集上 bias 的值非常小,模型甚至可以将所有的数据点正确分类,但是当将训练好的模型应用在dev 集上的时候,却出现了较高的错误率。这是因为模型设置的太复杂则没有排除一些train集数据中的噪声,使得模型出现overfitting的情况,在dev 集上出现高方差的现象。
所以对于bias和variance的权衡问题,对于模型来说是一个十分重要的问题。
假如对于一个数据集,以下几种模型:
| 模型 | 1 | 2 | 3 | 4 |
|---|---|---|---|---|
| 训练集误差 | 1% | 15% | 15% | 0.5% |
| 验证集误差 | 11% | 16% | 30% | 1% |
| 高方差 | 高偏差 | 高偏差、高方差 | 低偏差、低方差 | |
| 过拟合 | 欠拟合 | 欠拟合 |
上面的模型3出现的原因可能如下:
没有找到边界线(蓝色部分),但却在部分数据点上出现了过拟合(紫色),则会导致这种高偏差和高方差的情况。
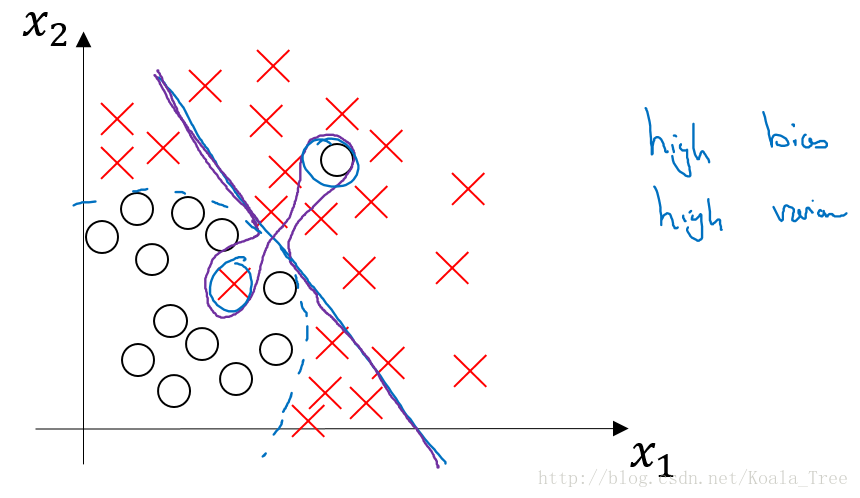
虽然在这里二维的情况下可能看起来较为奇怪,出现的可能性比较低;但是在高维的情况下,出现这种情况就成为可能。
解决高偏差和高方差
在训练机器学习模型的过程中,解决高偏差(High bias)和高方差(High variance)的过程:

- 存在高偏差?
- 增加网络结构,如增加隐藏层数目;
- 训练更长时间;
- 寻找合适的网络架构,使用更大的NN结构;
- 存在高方差?
- 获取更多的数据;
- 正则化( regularization);
- 寻找合适的网络结构;
在大数据时代,深度学习对监督式学习大有裨益,使得我们不用像以前一样太过关注如何平衡偏差和方差的权衡问题,通过以上方法可以使得再不增加另一方的情况下减少一方的值。
正则化
利用正则化来解决高方差的问题,正则化是在 Cost function 中加入一项正则化项,惩罚模型的复杂度。
逻辑回归的正则化
加入正则化项的代价函数:
\[J(w,b)=\dfrac{1}{m}\sum\limits_{i=1}^{m}l(\hat y^{(i)},y^{(i)})+正则化项\]
其中,正则化项有:
- L2正则化:\(\dfrac{\lambda}{2m}||w||_{2}^{2} = \dfrac{\lambda}{2m}\sum\limits_{j=1}^{n_{x}} w_{j}^{2}=\dfrac{\lambda}{2m}w^{T}w\)
- L1正则化:\(\dfrac{\lambda}{2m}||w||_{1}=\dfrac{\lambda}{2m}\sum\limits_{j=1}^{n_{x}}|w_{j}|\)
其中,\(\lambda\)是正则化因子
神经网络的正则化
加入正则化项的代价函数:
\[J(w^{[1]},b^{[1]},\cdots,w^{[L]},b^{[L]})=\dfrac{1}{m}\sum\limits_{i=1}^{m}l(\hat y^{(i)},y^{(i)})+\dfrac{\lambda}{2m}\sum\limits_{l=1}^{L}||w^{[l]}||_{F}^{2}\]
其中,\(||w^{[l]}||_{F}^{2}=\sum\limits_{i=1}^{n^{[l-1]}}\sum\limits_{j=1}^{n^{[l]}}(w_{ij}^{[l]})^{2}\)。而因为\(w\)的大小为\((n^{[l-1]},n^{[l]})\),因此该矩阵范数被称为“Frobenus norm”。
权重衰减
在加入正则化项后,梯度变为:
\[\frac{dL}{dW^{[l]}} = dW^{[l]} = (form\_backprop)+\dfrac{\lambda}{m}W^{[l]}\]
因此梯度更新公式变为:
\[W^{[l]}:= W^{[l]}-\alpha dW^{[l]}\\= W^{[l]}-\alpha [ (form\_backprop)+\dfrac{\lambda}{m}W^{[l]}]\\ = W^{[l]}-\alpha\dfrac{\lambda}{m}W^{[l]} -\alpha(form\_backprop)\\=(1-\dfrac{\alpha\lambda}{m})W^{[l]}-\alpha(form\_backprop)\]
其中,\((1-\dfrac{\alpha\lambda}{m}) < 1\),因此会给原来的\(W^{[l]}\)带来一个衰减的参数。因此L2范数正则化又被称为“权重衰减(weight decay)”。
为什么正则化可以减小过拟合
假设下图的神经网络结构属于过拟合状态:
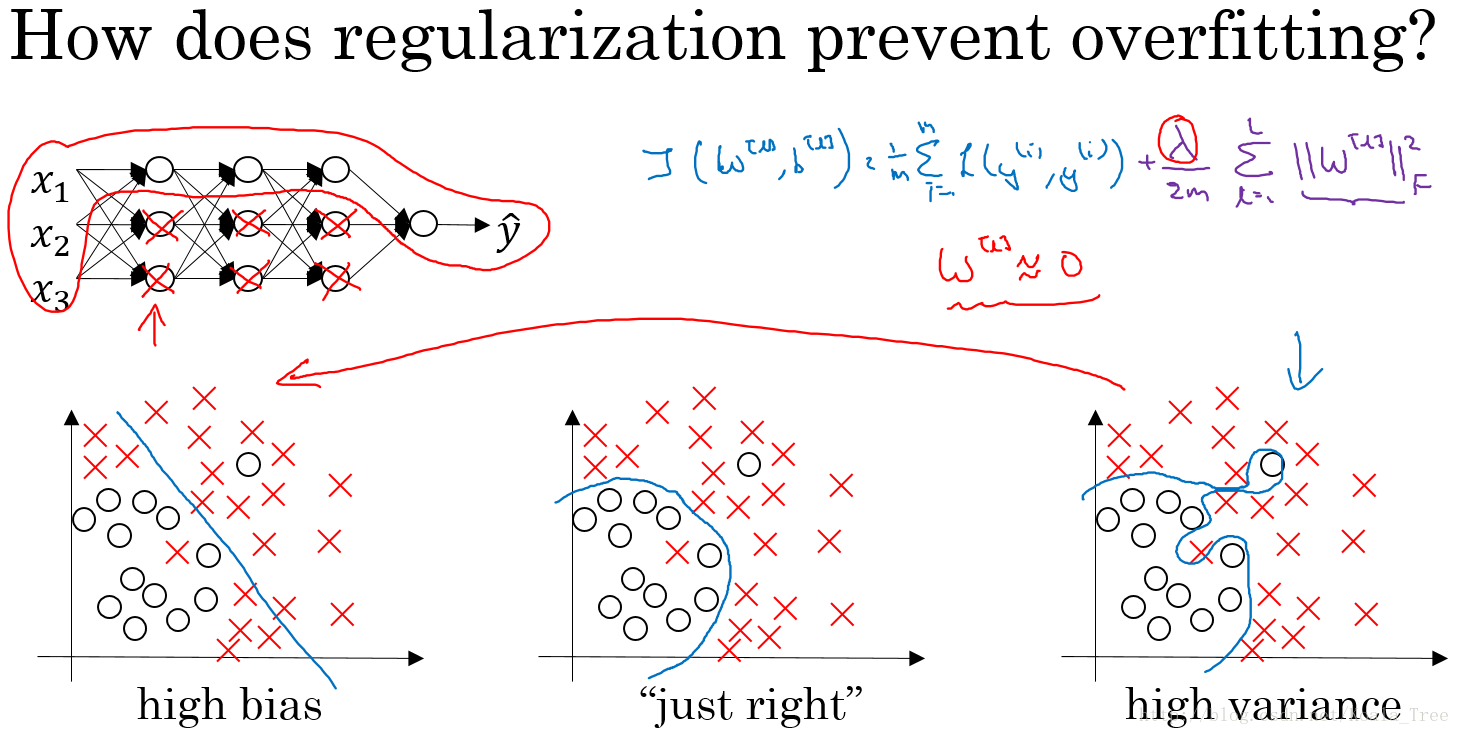
对于神经网络的Cost function:
\[J(w^{[1]},b^{[1]},\cdots,w^{[L]},b^{[L]})=\dfrac{1}{m}\sum\limits_{i=1}^{m}l(\hat y^{(i)},y^{(i)})+\dfrac{\lambda}{2m}\sum\limits_{l=1}^{L}||w^{[l]}||_{F}^{2}\]
直观解释
加入正则化项,直观上理解,正则化因子λ设置的足够大的情况下,为了使代价函数最小化,权重矩阵W就会被设置为接近于0的值。则相当于消除了很多神经元的影响,那么图中的大的神经网络就会变成一个较小的网络。
当然上面这种解释是一种直观上的理解,但是实际上隐藏层的神经元依然存在,但是他们的影响变小了,便不会导致过拟合。
数学解释
假设神经元中使用的激活函数为\(g(z)=tanh(z)\),在加入正则化项后:
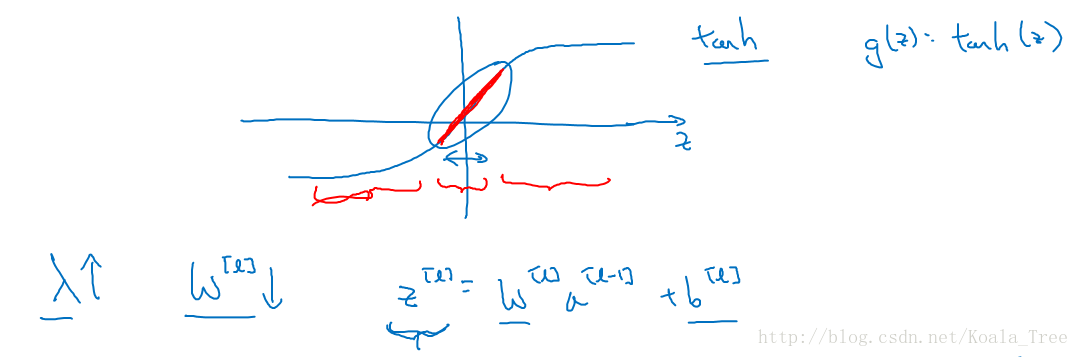
当\(λ\)增大,导致\(W[l]\)减小,\(Z^{[l]}=W^{[l]}a^{[l-1]}+b^{[l]}\)便会减小,由上图可知,在z较小的区域里,\(tanh(z)\)函数近似线性,所以每层的函数就近似线性函数,整个网络就成为一个简单的近似线性的网络,从而不会发生过拟合。
Dropout正则化
Dropout(随机失活)就是在神经网络的Dropout层,为每个神经元结点设置一个随机消除的概率,对于保留下来的神经元,我们得到一个节点较少,规模较小的网络进行训练。

实现方法:反向随机激活(inverted dropout)
假设对 layer 3 进行dropout:
1 | keep_prob = 0.8 # 设置神经元保留概率 |
依照例子中的keep_prob = 0.8 ,那么就有大约20%的神经元被删除了,也就是说\(a[3]\)中有20%的元素被归零了,在下一层的计算中有\(Z^{[4]}=W^{[4]}\cdot a^{[3]}+b^{[4]}\),所以为了不影响Z[4]的期望值,所以需要\(W^{[4]}\cdot a^{[3]}\)的部分除以一个keep_prob。
Notation:在测试阶段不要用dropout,因为那样会使得预测结果变得随机。
缺点
dropout的一大缺点就是其使得 Cost function不能再被明确的定义,因为每次迭代都会随机消除一些神经元结点,所以我们无法绘制出每次迭代J(W,b)下降的图,如下:
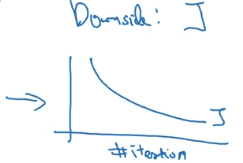
使用Dropout:
- 关闭dropout功能,即设置 keep_prob = 1.0;
- 运行代码,确保\(J(W,b)\)函数单调递减;
- 再打开dropout函数。
其它正则化方法
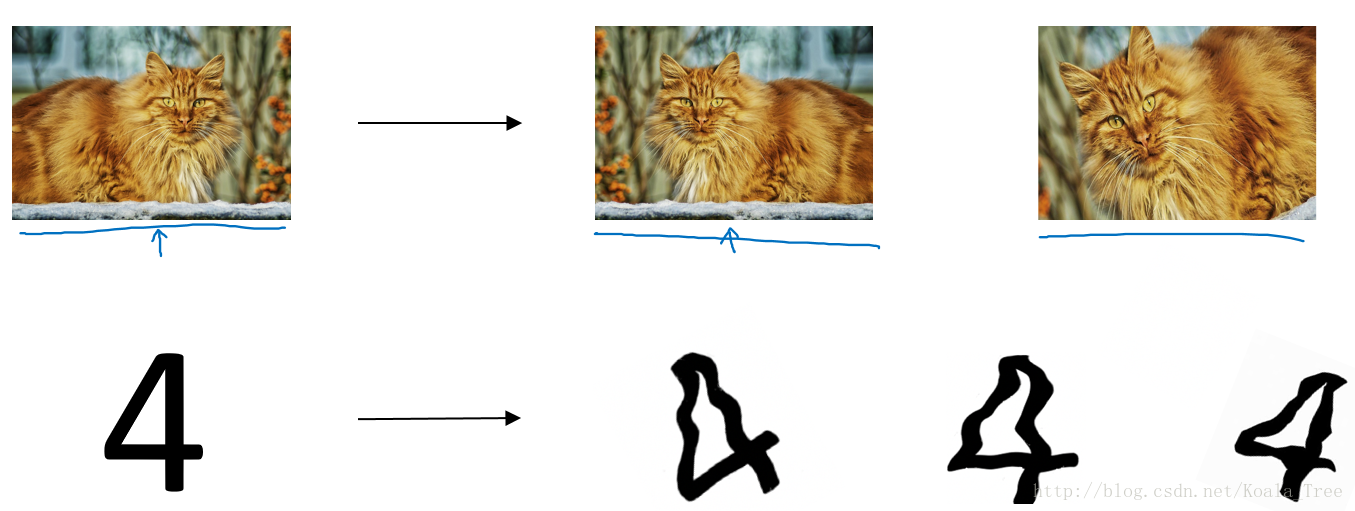
数据扩增(Data augmentation):通过图片的一些变换,得到更多的训练集和验证集;
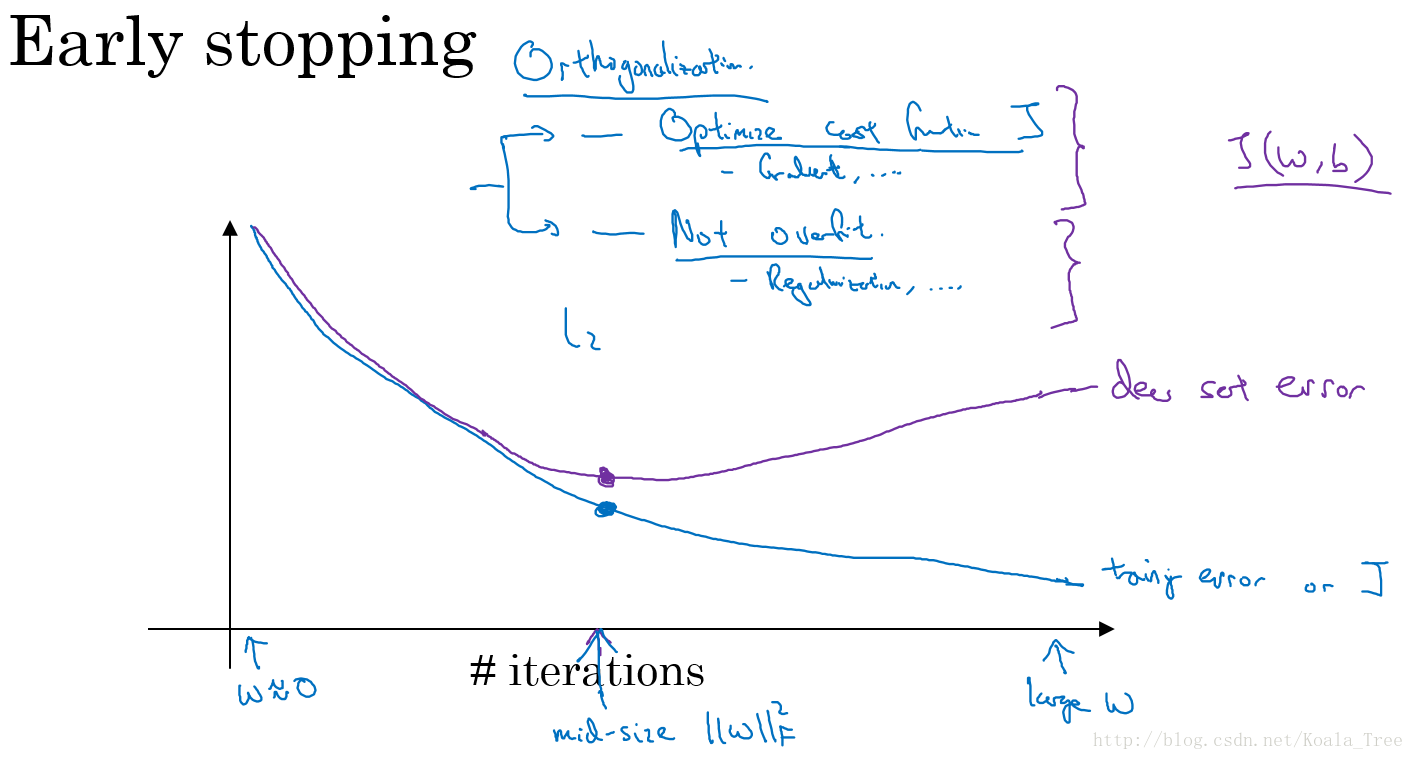
Early stopping:在交叉验证集的误差上升之前的点停止迭代,避免过拟合。这种方法的缺点是无法同时解决bias和variance之间的最优。
归一化输入
对数据集特征x1,x2归一化的过程:
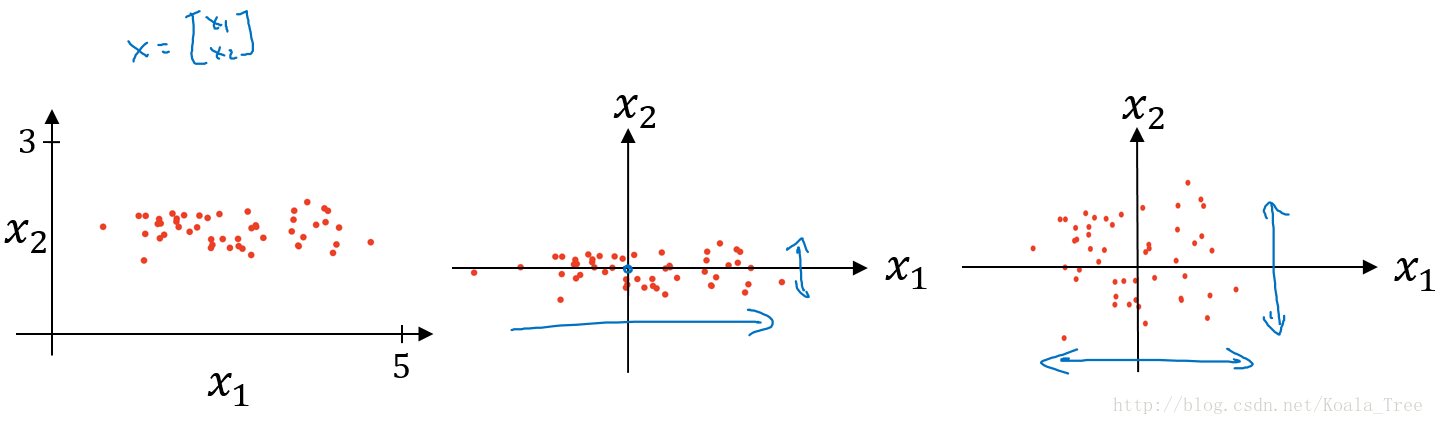
- 计算每个特征所有样本数据的均值:\(\mu = \dfrac{1}{m}\sum\limits_{i=1}^{m}x^{(i)}\)
- 减去均值得到对称的分布\(x : =x-\mu\)
- 归一化方差 : \(\sigma^{2} = \dfrac{1}{m}\sum\limits_{i=1}^{m}x^{(i)^{2}},x = x/\sigma^{2}\)
使用归一化的原因:
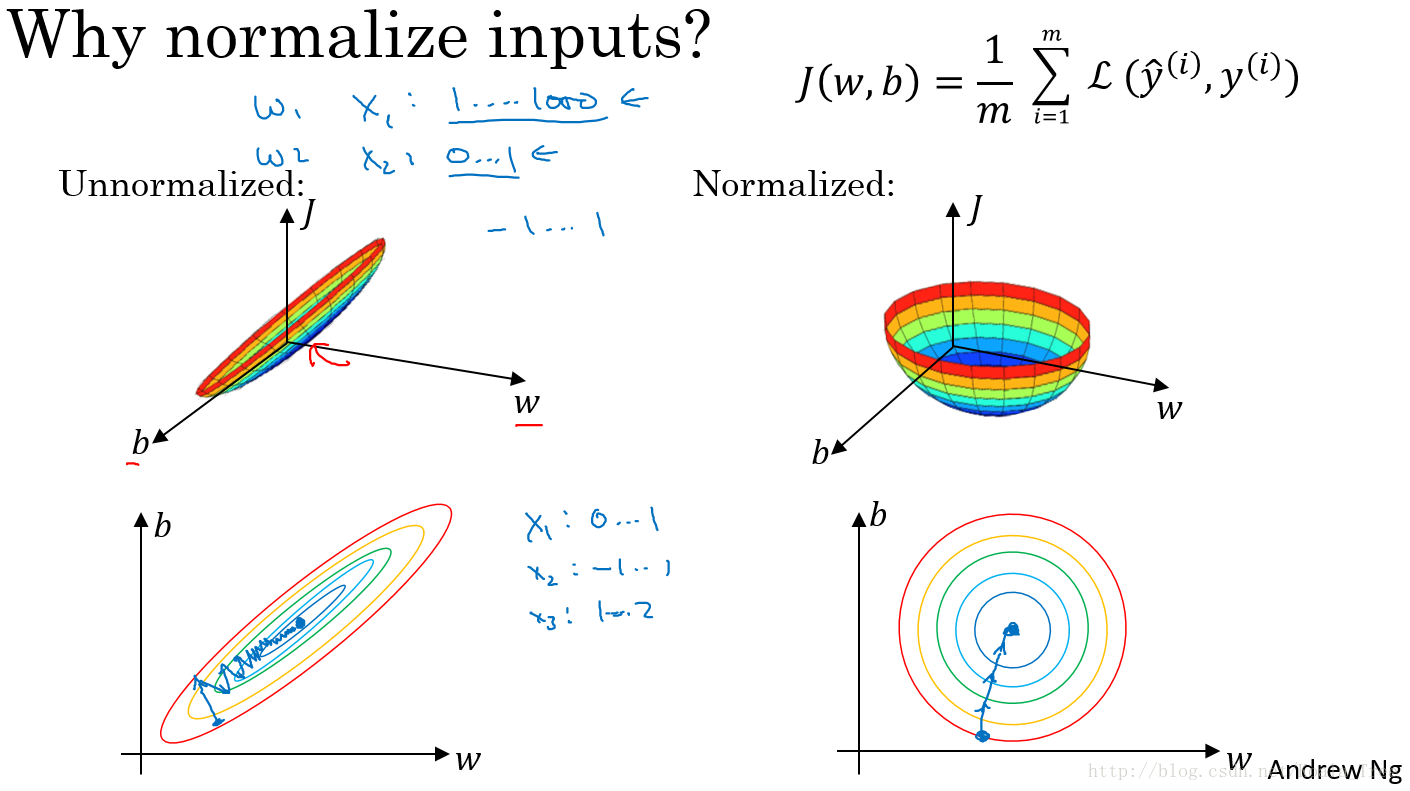
由图可以看出不使用归一化和使用归一化前后Cost function 的函数形状会有很大的区别。
在不使用归一化的代价函数中,如果我们设置一个较小的学习率,那么很可能我们需要很多次迭代才能到达代价函数全局最优解;如果使用了归一化,那么无论从哪个位置开始迭代,我们都能以相对很少的迭代次数找到全局最优解。
梯度相关
梯度消失与梯度爆炸
如下图所示的神经网络结构,以两个输入为例:
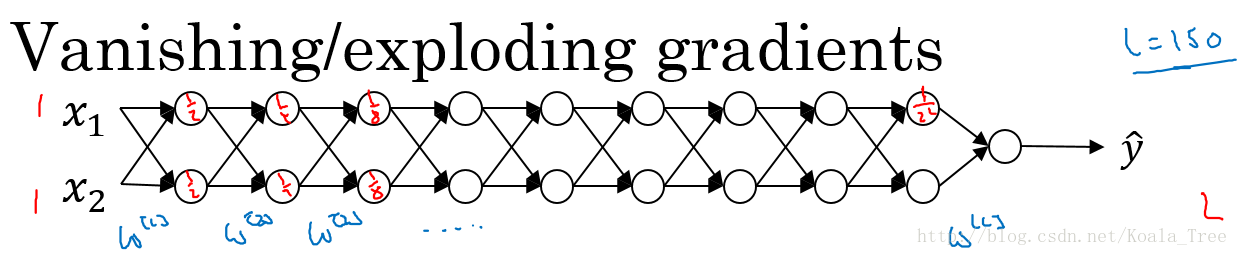
方便起见,我们先假定激活函数\(g(z) = z\),偏置\(b = 0\)。那么目标输出是:
\(\hat y = W^{[L]}W^{[L-1]}\cdots W^{[2]}W^{[1]}X\)
- 如果\(W^{[l]}\)大于1: \(W^{[l]}=\left[ \begin{array}{l} 1.5 & 0 \\ 0 & 1.5\end{array} \right]\),随着一层层的递进,激活函数的值将以指数递增;
- 如果\(W^{[l]}\)小于1: \(W^{[l]}=\left[ \begin{array}{l} 0.5 & 0 \\ 0 & 0.5\end{array} \right]\),随着一层层的递进,激活函数的值将以指数递减;
而对于梯度来说,梯度函数也会以指数级递增或递减,也叫做梯度爆炸或梯度消失。那么就会出现如下的图所示的情况:
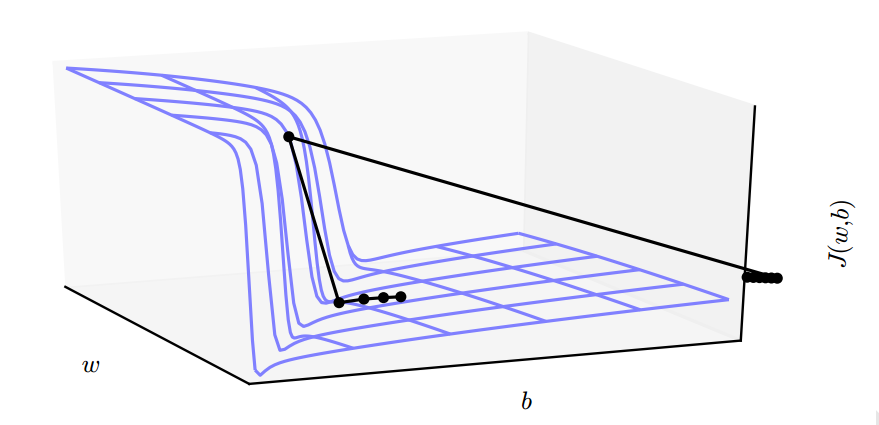
当参数接近这样的悬崖区域时,梯度下降更新会使参数弹得非常远,可能会让大量已完成的优化工作成为无用功。
解决梯度消失与爆炸
利用初始化缓解梯度消失和爆炸
以一个单个神经元为例子:
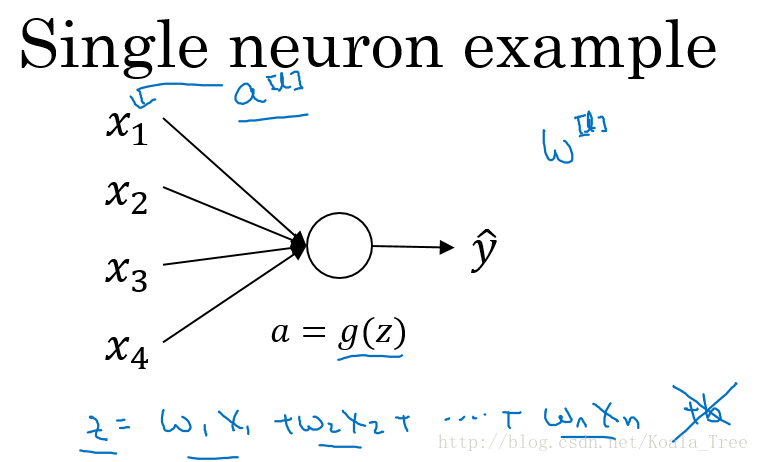
由上图可知,当输入的数量\(n\)较大时,我们希望每个\(w_i\)的值都小一些,这样它们的和得到的\(z\)也较小。这里为了得到较小的\(w_i\),将它初始化为\(Var(w_i)=\frac{1}{n}\),这里称为Xavier initialization。 即:
1 | WL = np.random.randn(WL.shape[0],WL.shape[1])* np.sqrt(1/n) |
这么做是因为,如果激活函数的输入\(x\)近似设置成均值为0,标准方差1的情况,输出\(z\)也会调整到相似的范围内。虽然没有解决梯度消失和爆炸的问题,但其在一定程度上确实减缓了梯度消失和爆炸的速度。
不同激活函数下,也有不同的Xavier initialization:
- 激活函数为Relu时,\(Var(w_{i})=\dfrac{2}{n}\)
- 激活函数为tanh时,\(Var(w_{i})=\dfrac{1}{n}\)
其中n是输入神经元个数,也就是\(n^{[l-1]}\)
启发式梯度截断缓解梯度消失和爆炸
传统的梯度下降的梯度只指明了方向,而步长是定值。而启发式梯度截断的思路是:当传统的梯度建议更新很大一步时,启发式梯度截断会干涉来缩减步长,从而使其不太可能走出梯度近似为最陡方向的悬崖区域。
梯度的数值逼近
使用双边误差的方法去逼近导数:
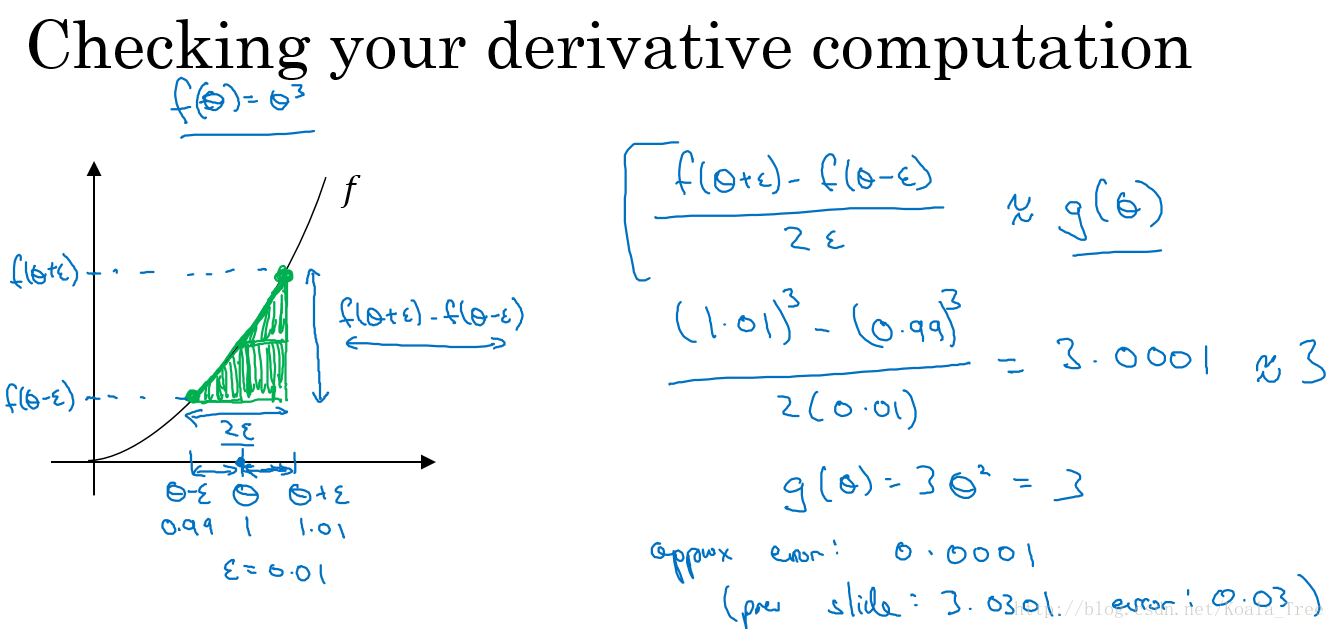
由图可以看出,双边误差逼近的误差是0.0001,先比单边逼近的误差0.03,其精度要高了很多。
涉及的公式:
双边导数: \[f'(\theta) = \lim\limits_{\varepsilon \to 0}=\dfrac{f(\theta+\varepsilon)-(\theta-\varepsilon)}{2\varepsilon}\] 误差:\(O(\varepsilon^{2})\)
单边导数:
\[f'(\theta) = \lim\limits_{\varepsilon \to 0}=\dfrac{f(\theta+\varepsilon)-(\theta)}{\varepsilon}\]
误差:\(O(\varepsilon)\)
梯度检验
众所周知,反向传播算法很难调试得到正确结果,尤其是当实现程序存在很多难于发现的bug时。举例来说,索引的缺位错误(off-by-one error)会导致只有部分层的权重得到训练,再比如忘记计算偏置项。这些错误会使你得到一个看似十分合理的结果(但实际上比正确代码的结果要差)。因此,但从计算结果上来看,我们很难发现代码中有什么东西遗漏了。本节中,我们将介绍一种对求导结果进行数值检验的方法,该方法可以验证求导代码是否正确。
假设我们已经用代码实现了计算\(\frac{dL}{dw}\) 的函数\(g(w)\) ,接着我们使用\(w:=w - \lambda g(w)\)来实现梯度下降算法。那么我们如何检验\(g\)的实现是否正确呢?
回忆导数的数学定义:
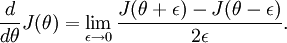
那么对于任意  值,我们都可以对等式左边的导数用:
值,我们都可以对等式左边的导数用:
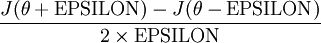
来近似。
实际应用中,我们常将 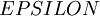 设为一个很小的常量,比如在
设为一个很小的常量,比如在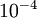 数量级(虽然 的取值范围可以很大,但是我们不会将它设得太小,比如
数量级(虽然 的取值范围可以很大,但是我们不会将它设得太小,比如 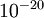 ,因为那将导致数值舍入误差。)
,因为那将导致数值舍入误差。)
给定一个被认为能计算 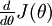 的函数
的函数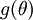 ,我们可以用下面的数值检验公式
,我们可以用下面的数值检验公式
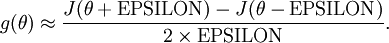
计算两端是否一样来检验函数是否正确。
而在多维情况下,即可计算:
\[\dfrac {||d\theta_{approx}-d\theta||_{2}}{||d\theta_{approx}||_{2}+||d\theta||_{2}}\]
将它与代码计算出来的\(g(\theta)\)进行比较。如果近似,则说明计算没有出错。
也就是:

再判断\(d\theta_{approx}\approx d\theta\)是否成立
其中,“\(||⋅||2\)”表示欧几里得范数,它是误差平方之和,然后求平方根,得到的欧氏距离。
notes
- 不要在训练过程中使用梯度检验,只在debug的时候使用,使用完毕关闭梯度检验的功能;
- 如果算法的梯度检验出现了错误,要检查每一项,找出错误,也就是说要找出哪个\(d\theta_{approx}[i]\)与dθ的值相差比较大;
- 不要忘记了正则化项;
- 梯度检验不能与dropout同时使用。因为每次迭代的过程中,dropout会随机消除隐层单元的不同神经元,这时是难以计算dropout在梯度下降上的代价函数J;
- 在随机初始化的时候运行梯度检验,也可以在训练几次后再进行。
优化算法
Mini-batch 梯度下降法
对整个训练集进行梯度下降法的时候,我们必须处理整个训练数据集,然后才能进行一步梯度下降,即每一步梯度下降法需要对整个训练集进行一次处理,如果训练数据集很大的时候,如有500万或5000万的训练数据,处理速度就会比较慢。
但是如果每次处理训练数据的一部分即进行梯度下降法,则我们的算法速度会执行的更快。而处理的这些一小部分训练子集即称为Mini-batch。
详细地说,就是在做梯度下降的时候,不选取训练集的所有样本计算损失函数,而是切分成很多个相等的部分,每个部分称为一个mini-batch,我们对一个mini-batch的数据计算代价,做完梯度下降,再对下一个mini-batch做梯度下降。比如500w个数据,一个mini-batch设为1000的话,我们就做5000次梯度下降(5000个mini-batch,每个mini-batch样本数为1000,总共500w个样本)。
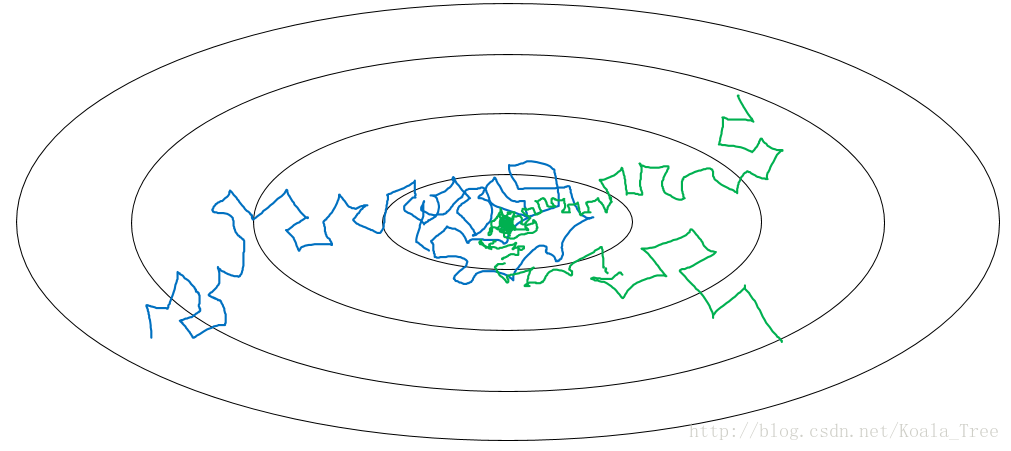
对于batch梯度下降(每次计算所有的样本),随着迭代次数增加,代价不断减少。对于mini-batch梯度下降,mini-batch的迭代过程中,代价是震荡下降的(有时上升有时下降),因为每次下降时只考虑了部分样本,下降方向可能不正确。如下图所示:

mini-batch的size为m时就是batch梯度下降,它的弊端是m很大的时候单次训练需要花费很长的时间。
size为1时就是随机梯度下降(每次只计算一个样本),随机梯度下降在每次梯度下降可能会远离最优点,可能会接近最优点,平均来看会不断靠近最优点,但有时也会方向错误。随机梯度下降最终不会收敛,而是会在最优点附近波动。它的弊端就是失去了向量化带来的加速优势,因为每次只训练一个样本,要用m次循环去迭代。
所以实践中选取不大不小的mini-batch size,这样既利用了向量化的优势,也避免了m太大带来的训练时间太长的弊端。它也会震荡式地靠近最优点,但是相比于随机梯度下降要好很好,最终可能会在最优点附近波动,这个时候可以调整学习率来改善该问题。
数据集小的时候,比如m小于2000,一般直接用batch梯度下降;一般mini-batch的size在64,128,256,512这些值之间考虑(考虑到电脑的内存设置方式,设定为2的次方训练比较快);记得要确保mini-batch的大小要符合你的CPU/GPU大小。
指数加权平均
指数加权平均的关键函数:
\[v_{t} = \beta v_{t-1}+(1-\beta)\theta_{t}\]
以时间-温度为例。我们已知每天的温度为Θ1, Θ2,..。那么时间-温度的指数加权平均函数为:V, 有V0 = 0,V(t) = 0.9 * V(t-1) + 0.1 * Θt。即用(前一天的V乘以0.9)加上(当天的温度乘以0.1)。
对V绘制图,如下图中的红线所示,它大致表示了平均10天的温度
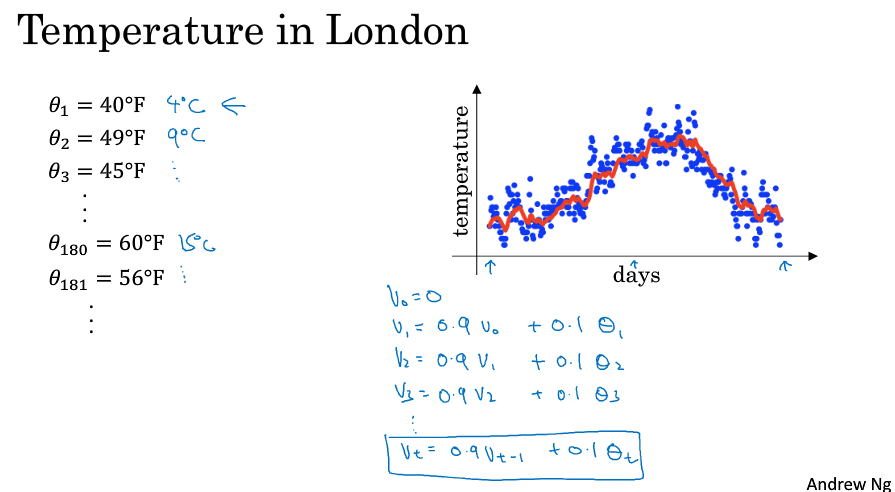
如果我们把它展开:
\[v_{100}=0.1\theta_{100}+0.9(0.1\theta_{99}+0.9(0.1\theta_{98}+0.9v_{97}))\\=0.1\theta_{100}+0.1\times0.9\theta_{99}+0.1\times(0.9)^{2}\theta_{98}+0.1\times(0.9)^{3}\theta_{97}+\cdots\]
我们可以理解为:V就是指数加权了 x天的温度。这个x是多少呢,有个计算方法就是β的x次方约等于1/e,以此求出x,那其实这个x就是1/(1-β)。
- 当β=0.9时,加权了10天,指数加权平均最后的结果如图中红色线所示;
- 当β=0.98时,加权了50天,指数加权平均最后的结果如图中绿色线所示;
- 当β=0.5时,加权了2天,指数加权平均最后的结果如下图中黄色线所示;

指数加权平均的偏差修正
如下图所示,β=0.98时,实际执行上面的计算步骤我们会得到紫色的曲线,而不是绿色曲线。

原因如下:一开始的时候v0 = 0,然后
\[v_{0}=0\\v_{1}=0.98v_{0}+0.02\theta_{1}=0.02\theta_{1}\\v_{2}=0.98v_{1}+0.02\theta_{2}=0.98\times0.02\theta_{1}+0.02\theta_{2}=0.0196\theta_{1}+0.02\theta_{2}\]
如果第一天的值为如40,则得到的\(v_{1}=0.02\times40=8\),则得到的值要远小于实际值,后面几天的情况也会由于初值引起的影响,均低于实际均值。
所以刚开始的几个点都会偏低,不能做出很好的估计,所以需要做一定的偏差修正,修正方法为:
\[\dfrac{v_{t}}{1-\beta^{t}}\]
当t = 2 时,\(1-\beta^{t}=1-(0.98)^{2}=0.0396\),则\(\dfrac{v_{2}}{0.0396}=\dfrac{0.0196\theta_{1}+0.02\theta_{2}}{0.0396}\)
偏差修正得到了绿色的曲线,在开始的时候,能够得到比紫色曲线更好的计算平均的效果。到后面t增大,作为分母的( 1 - β^t ) 趋近于0,所以后面绿色的曲线和紫色的曲线逐渐重合了。
虽然存在这种问题,但是在实际过程中,一般会忽略前期均值偏差的影响。
动量梯度下降(Gradient descent with momentum )
我们把之前学的指数加权平均应用到梯度下降中可以改善问题。
考虑代价函数的等高线如下图所示,使用mini-batch时因为方向不一定是最优方向,所以可能在不断靠近最优点时候会上下波动(下图蓝线)。
这个时候我们希望在上下方向上用较小的学习步长,在往右方向上使用较大的学习步长,那么可以对求得的梯度做指数加权平均的运算得到一个平均值,这时上下波动求平均,一正一负平均为0,往右前进平均还是往右,在抵达最优点的路上我们减少了动荡,能够以理想的步长去靠近最优点(下图红线)。

具体做法:
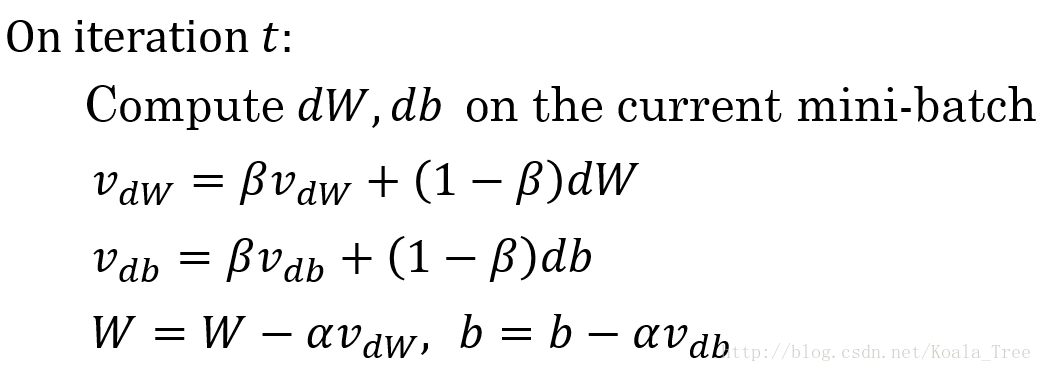
即,每次做梯度下降时,求一下指数加权平均,用这个平均值来做梯度下降。
这就是加了动量的梯度下降法,它不像之前的梯度下降(每次下降都是独立于之前的步骤),这个时候就有两个超参数,α和β,β一般设为0.9,表示平均了最近10次的迭代速度。
对于动量的理解:把微分dW理解成球往山下滚的加速度,momentum项v理解成速度,球因为加速度越滚越快,β稍小于1可以理解为摩擦力的阻碍,所以球不会无限加速下去。
关于偏差修正,实际上一般不用,因为10次迭代后就不需要修正了,我们平时的学习一般都不会少于10次。
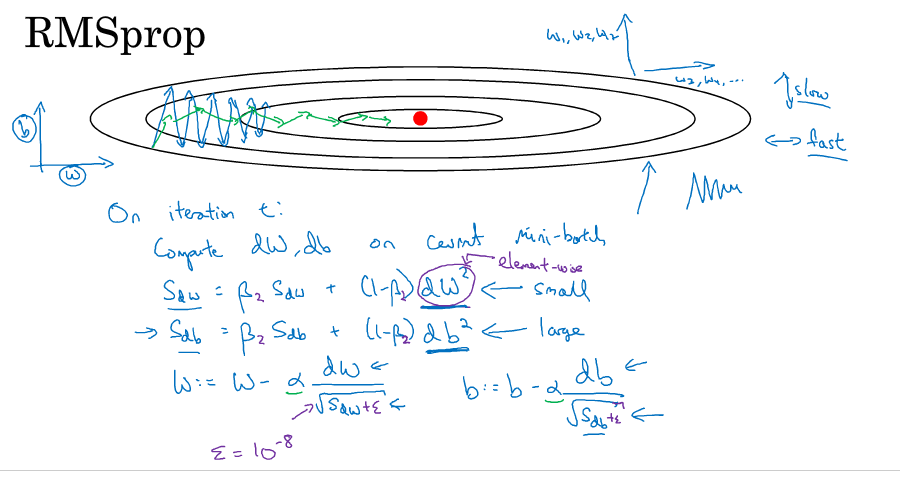
RMSProp(root mean square )
还有一种算法叫RMSProp也可以用来加速mini-batch梯度下降,它是在momentum的基础上做了修改。公式如下图所示,dW变成dW的平方,在下降的时候多除以了一个根号项。可以理解成竖直方向的微分项比较大,所以除以一个比较大的数,水平方向的微分项比较小,所以除以一个比较小的数,这样就可以消除下降中的摆动,可以采用较大的学习率快速学习。为了确保除以的分母不会为0,在实操上会加上一个很小的数ε。
Adam
在深度学习领域,经常有很多新的优化算法被提到然后又遭到质疑。adam和RMSProp是少有的经得起考验的两种优化算法,已经被证明适用于不同的深度学习结构,被用来很好地解决了很多问题。
adam算法基本就是结合了momentum和RMSProp。
算法实现
- 初始化\(V_{dw} = 0,S_{dw}=0,V_{db}=0,S_{db} = 0\)
- 第t次迭代:
- 在当前的mini-batch上计算\(dw,db\)
- \(V_{dw}=\beta_{1}V_{dw}+(1-\beta_{1})dw,V_{db}=\beta_{1}V_{db}+(1-\beta_{1})db\) ——的V就是动量(momentum),与原来的计算方式一样
- \(S_{dw}=\beta_{2}S_{dw}+(1-\beta_{2})(dw)^{2},S_{db}=\beta_{2}S_{db}+(1-\beta_{2})(db)^{2}\) ——S按照RMSprop的方式计算
- \(V_{dw}^{corrected} = V_{dw}/(1-\beta_{1}^{t}),V_{db}^{corrected} = V_{db}/(1-\beta_{1}^{t})\) ——再做一点偏差修正
- \(S_{dw}^{corrected} = S_{dw}/(1-\beta_{2}^{t}),S_{db}^{corrected} = S_{db}/(1-\beta_{2}^{t})\)
- \(w:=w-\alpha\dfrac{V_{dw}^{corrected}}{\sqrt{S_{dw}^{corrected}}+\varepsilon},b:=b-\alpha\dfrac{V_{db}^{corrected}}{\sqrt{S_{db}^{corrected}}+\varepsilon}\) —— 按照RMSprop的方式更新
这个方法有比较多的超参数,比如学习率α需要自己调整,β1一般为0.9,β2的话adam的论文作者推荐0.999,ε的话adam的论文作者推荐10的-8次方。在使用adam的时候一般β和ε使用缺省值就可以了。
adam表示adaptive moment estimate,β1用于计算dw微分的平均,称为first moment,β2用于计算dw的平方的平均,称为second moment,adam由此而来。
学习率衰减
做学习率衰减的原因很简单,就是梯度下降早期离最优点很远,可以用较大的步长靠近,到了后期,离最优点很近的时候就要小心了,因为你跨一大步可能会跨过头,远离最优点。如下图蓝色线所示。
所以到后面步长要变小,也就是学习率要进行衰减。变成绿色线。
学习率衰减常用的方法为:
常用 \[\alpha = \dfrac{1}{1+decay\_rate*epoch\_num}\alpha_{0}\]
1 / ( 1+ decay rate * epoch_num ) 乘上初始学习率α,衰减率作为新的超参,epoch_num表示迭代了第几轮。
指数衰减 \[\alpha = 0.95^{epoch\_num}\alpha_{0}\]
其它 \[\alpha = \dfrac{k}{epoch\_num}\cdot\alpha_{0}\]
离散下降(不同阶段使用不同的学习速率)
局部最优问题
在深度学习的早期,人们总是担心优化问题会陷入局部最优。随着深度学习理论的发展,我们对局部最优的理解也发生了改变,我们对它的理解也还在不断发展中。
我们可能会想象到一个Cost function 如左图所示,存在一些局部最小值点,在初始化参数的时候,如果初始值选取的不得当,会存在陷入局部最优点的可能性。
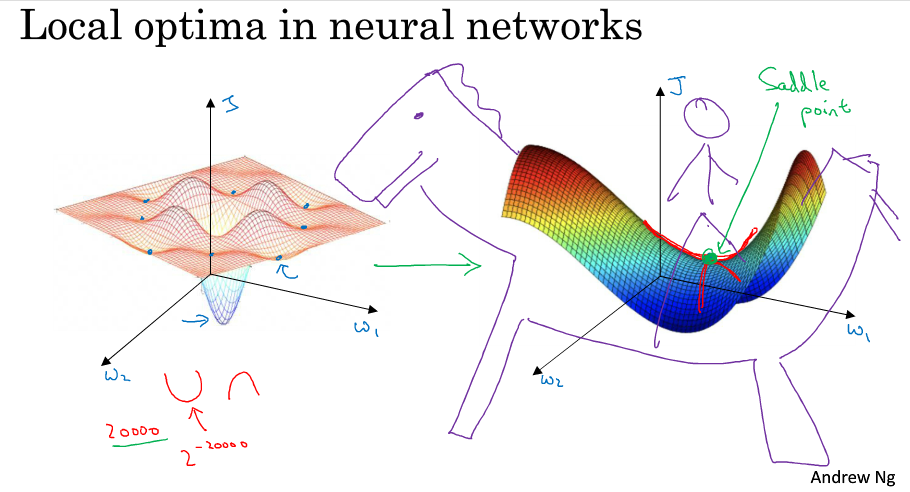
但这些理解并不正确,事实上,如果你要创建一个神经网络,通常梯度为0的点并不是左图那些局部最优点,而是右图的这个鞍点。鞍点可以理解为在某一方向上是极大值点,在另一方向上是极小值点,可以想象成马背上的马鞍。
在高维空间中梯度为0的点,在每个方向上可能是凸函数,也可能是凹函数。比如你在2w维空间中你想得到局部最优,所有的2w个方向都需要是这样的,这样的概率大概是\(2^{-20000}\) ,实在是太小了。
也就是说,我们更有可能遇到的是有些方向向上弯曲,而另一些方向向下弯曲,如右图所示,因此在高维空间我们更有可能碰到的是鞍点。
所以在深度学习中(假设你有大量参数,代价函数被定义在高维空间)你不太可能陷入局部极值点,但是位于鞍点这样的平稳地段你可能学习的非常慢,如下图所示。所以才有了momentum,RMSProp,adam这样的算法来加快运算。
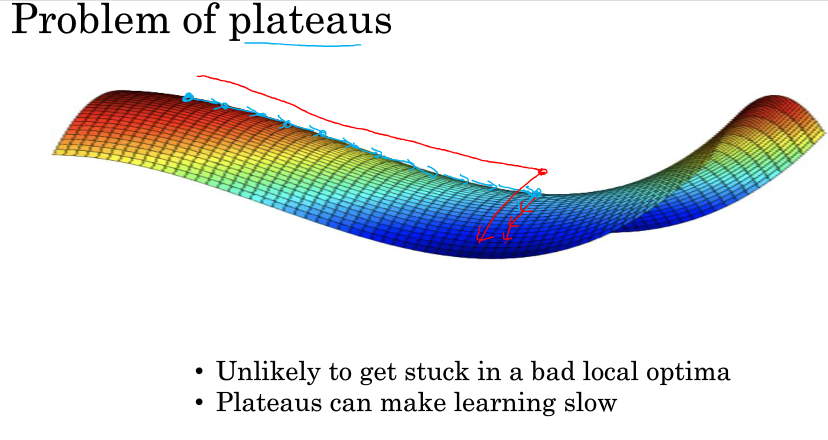
总之,在高纬度的情况下:
- 几乎不可能陷入局部最小值点;
- 处于鞍点的停滞区会减缓学习过程,利用如Adam等算法进行改善。