#coding=utf-8 # 首先做一些数据声明 from sklearn.decomposition import TruncatedSVD from matplotlib import pyplot as plt from numpy import random import numpy as np from mpl_toolkits.mplot3d import Axes3D import pandas as pd fig = plt.figure() ax = Axes3D(fig) ax=plt.subplot(111,projection='3d') ax.set_zlabel('Z') #坐标轴 ax.set_ylabel('Y') ax.set_xlabel('X') X = np.arange(0, 4, 0.125) + 0.2 * random.randn(32) Y = np.arange(0, 4, 0.125) + 0.2 * random.randn(32) Z = np.arange(0, 4, 0.125) + 0.2 * random.randn(32) # 数据是3维×32维 data = [[x, y, z] for x, y, z inzip(X, Y, Z)]
#画图 X_ = [x[0] for x in data_inverse] Y_ = [y[1] for y in data_inverse] Z_ = [z[2] for z in data_inverse] ax.scatter(X, Y, Z, c='r')#原始数据是红色 ax.scatter(X_, Y_, Z_, c='b')#分解后的数据是蓝色 plt.savefig("svd.png") plt.show() print svd.explained_variance_ratio_ '''
网络爬虫是捜索引擎抓取系统中重要的组成部分,其主要目的是将互联网上的网页下载到本地形成一个文件或互联网内容的镜像备份。流程如下: a. 从给定的入口网址把第一个网页下载下来 b. 从第一个网页中提取出所有新的网页地址,放入下载列表中 c. 按下载列表中的地址,下载所有新的网页 d. 从所有新的网页中找出没有下载过的网页地址,更新下载列表 e. 重复3、4两步,直到更新后的下载列表为空表时停止 其实就是简化成下面的步骤: a. 按下载列表进行下载 b. 更新下载列表 c. 循环操作a,b,直到列表为空结束 在本次作业中我们使用python编码实现爬虫的功能,其中用到的python组件有: urllib2:用于获取URLs(Uniform Resource Locators)的组件,以urlopen函数的形式提供一个非常简单的接口,具有利用不同协议获取URLs的能力,同时提供了一个比较复杂的接口来处理一般情况,如:基础验证,cookies代理和其他。通过handlers和openers的对象提供。urllib2支持获取不同格式的URLs并利用它们相关网络协议(例如FTP,HTTP)进行获取。 BeautifulSoup:是python的一个库,最主要的功能是从网页抓取数据。它提供简单的、python式的函数用来处理导航、搜索、修改分析树等功能。可以通过解析文档为用户提供需要抓取的数据。在bs4库中导入。 Htmlparser:是一个开源项目,提供了线性和嵌套两种方式来解析网页,主要用于 html 网页的转换(Transformation)以及网页内容的抽取(Extraction)。HtmlParser 有如下一些易于使用的特性:过滤器(Filters),访问者模式(Visitors),处理自定义标签以及易于使用的 JavaBeans。 selenium :是一个模拟浏览器,进行web的自动化测试的工具,它提供一组API可以与真实的浏览器内核交互。用于抓取js动态生成的页面。
信息检索系统模型
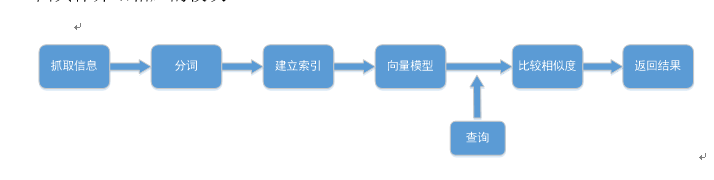
信息检索系统的模型主要有布尔模型、向量模型和概率模型。其中布尔模型 是最早的IR模型,也是应用最广泛的模型,目前仍然应用于商业系统中,布尔模型查询简单但不支持部分匹配,很难控制被检索的文档数量;向量模型(VSM:Vector Space Model)是Salton在上世纪60年代提出的,成功应用于SMART(System for the Manipulation and Retrieval of Text)文本检索系统,其基于关键词,并根据关键词的出现频率计算相似度,向量模型中术语权重的算法提高了检索的性能,部分匹配的策略使得检索的结果文档集更接近用户的检索需求,同时可以根据结果文档对于查询串的相关度使用Cosine Ranking等公式对结果文档进行排序。 在本次作业中信息检索系统采用向量模型,根据相似度返回结果。 ## 结巴(Jieba)分词 结巴(jieba)是一个可以对一段中文进行分词的插件,支持精确模式、全模式及搜索引擎模式三种分词模式,可以适应不同需求。其基本实现原理有:(1)基于Trie树结构实现高效的词图扫描,生成句子中汉字所有可能成词情况所构成的有向无环图(DAG);(2)采用了动态规划查找最大概率路径, 找出基于词频的最大切分组合;(3)对于未登录词,采用了基于汉字成词能力的HMM模型,使用了Viterbi算法。 ## 基于webpy界面设计网页 webpy 是一个轻量级Python web框架,可以快速的完成简单的web页面。在本次实验中使用webpy建立搜索网页,web.py 的模板语言叫做 Templetor,它能负责将 python 的强大功能传递给模板系统。本实验中使用template与html编写网页。
参考文献Practical Lessons from Predicting Clicks on Ads at Facebook6.3指出,欠采样可以加快训练速度,提升模型表现。需要注意的是,就算数据被欠采样,其实也可以通过在欠采样空间中对预测结果进行修正。例如,在采样之前CTR只有0.1%,那么我们对负样本欠采样0.01,那么CTR就会变为10%。为了修正结果,使得CTR恢复到0.1%,我们可以通过公式: \[q=\frac{p}{p+(1-p)/w}\] 其中,\(p\)是欠采样空间下预测的概率, \(w\)是对负样本的采样率。
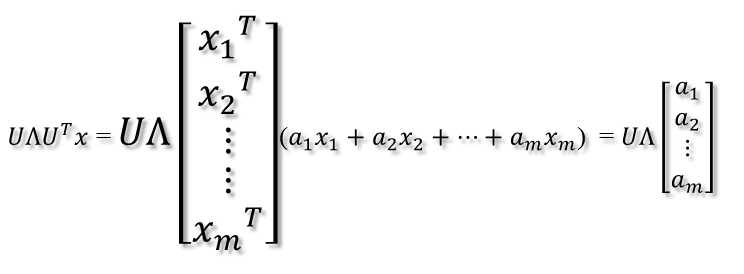 2. 紧接着,在新的坐标系表示下,由中间那个对角矩阵对新的向量坐标换,其结果就是将向量往各个轴方向拉伸或压缩:
2. 紧接着,在新的坐标系表示下,由中间那个对角矩阵对新的向量坐标换,其结果就是将向量往各个轴方向拉伸或压缩: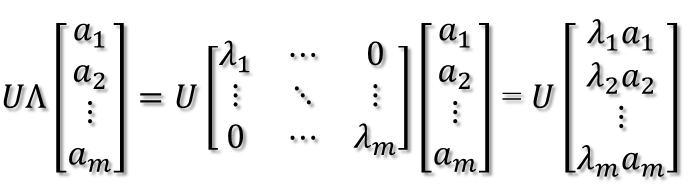 从上图可以看到,如果A不是满秩的话,那么就是说对角阵的对角线上元素存在0,这时候就会导致维度退化,这样就会使映射后的向量落入m维空间的子空间中。 3. 最后一个变换就是U对拉伸或压缩后的向量做变换,由于U和U'是互为逆矩阵,所以U变换是U'变换的逆变换。
从上图可以看到,如果A不是满秩的话,那么就是说对角阵的对角线上元素存在0,这时候就会导致维度退化,这样就会使映射后的向量落入m维空间的子空间中。 3. 最后一个变换就是U对拉伸或压缩后的向量做变换,由于U和U'是互为逆矩阵,所以U变换是U'变换的逆变换。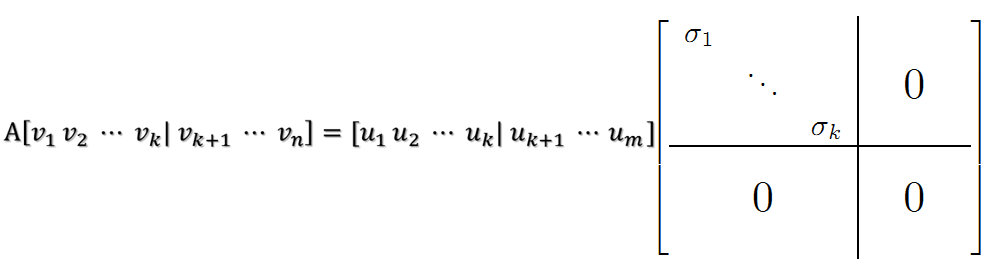
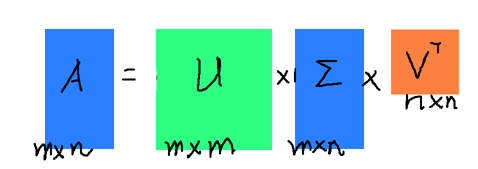
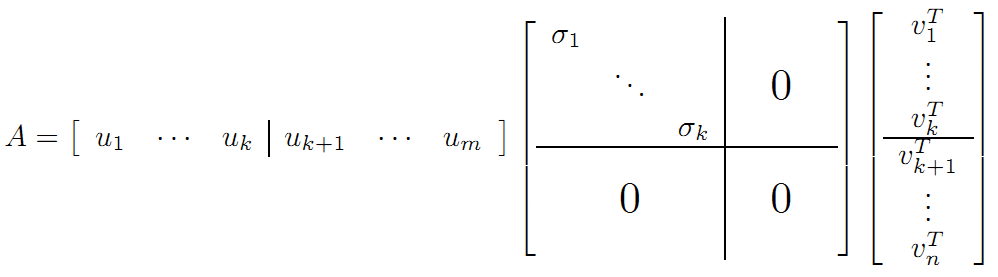
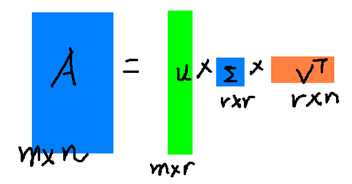 右边的三个矩阵相乘的结果将会是一个接近于A的矩阵,在这儿,r越接近于n,则相乘的结果越接近于A。而这三个矩阵的面积之和(在存储观点来说,矩阵面积越小,存储量就越小)要远远小于原始的矩阵A,我们如果想要压缩空间来表示原矩阵A,我们存下这里的三个矩阵:U、Σ、V就好了。
右边的三个矩阵相乘的结果将会是一个接近于A的矩阵,在这儿,r越接近于n,则相乘的结果越接近于A。而这三个矩阵的面积之和(在存储观点来说,矩阵面积越小,存储量就越小)要远远小于原始的矩阵A,我们如果想要压缩空间来表示原矩阵A,我们存下这里的三个矩阵:U、Σ、V就好了。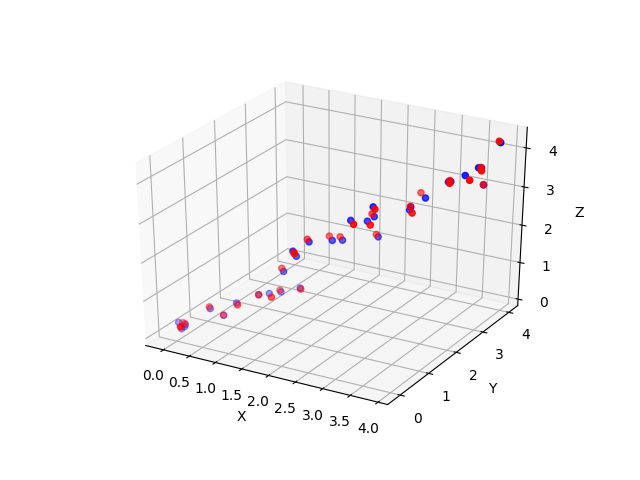 降到一维,再还原,我们看到:
降到一维,再还原,我们看到: 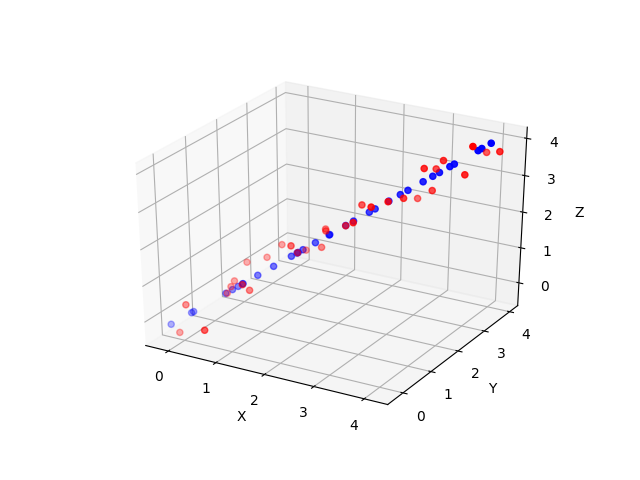

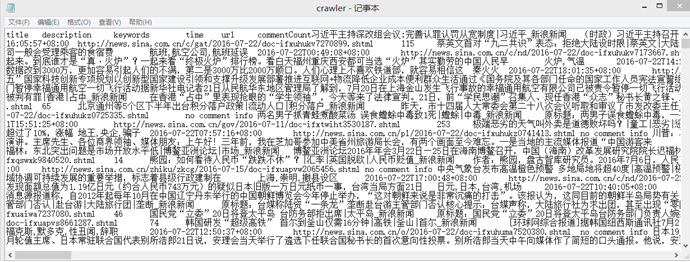 每条新闻包括标题、关键字、时间、网址、评论数(热度)等信息。
每条新闻包括标题、关键字、时间、网址、评论数(热度)等信息。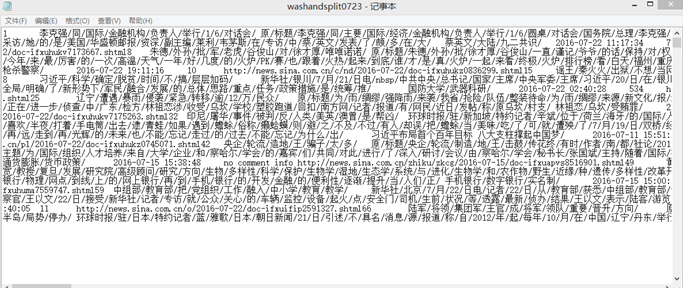 建立索引 对于所有的词,按照其在全部新闻中出现的情况建立倒排索引,将每个词与相应的新闻序号建立联系。 建立向量模型 结合建立的倒排索引表,计算每个新闻条目的向量,其中权重采用tf-idf算法生成,构建向量模型。
建立索引 对于所有的词,按照其在全部新闻中出现的情况建立倒排索引,将每个词与相应的新闻序号建立联系。 建立向量模型 结合建立的倒排索引表,计算每个新闻条目的向量,其中权重采用tf-idf算法生成,构建向量模型。 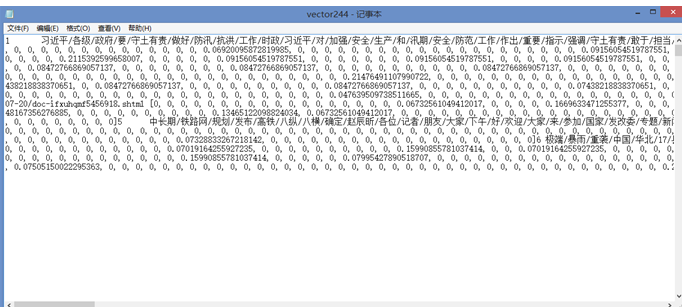 查询返回结果 根据在query中输入的关键词与向量模型进行数量积计算相似度,根据相似度的大小将检索到的新闻按序列出。如:query中输入“南海,菲律宾”,得到的检索结果如下:
查询返回结果 根据在query中输入的关键词与向量模型进行数量积计算相似度,根据相似度的大小将检索到的新闻按序列出。如:query中输入“南海,菲律宾”,得到的检索结果如下: 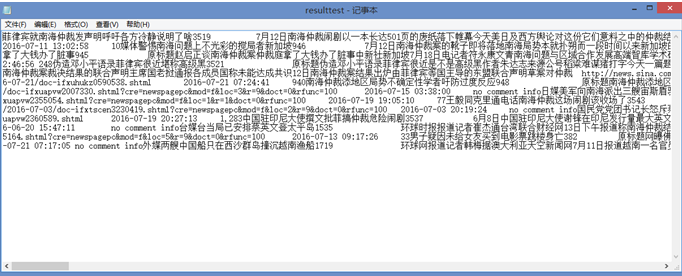 前后端实现 基于webpy界面设计搜索网页,建立交互的界面。在之前系统设计的基 础上,在webpy框架下,利用templates模板语言将后台结果与前端界面进行交互,并在服务器端使用GET和POST函数与客户端web交互并传递参数传递参数,将搜索新闻在网页上呈现出来。其主要步骤为:(1)客户端发送get请求,触发服务端get()函数,调用index.html网页,返回给客户端。(2)客户端发送搜索关键字并通过post方式给服务端,触发服务端post()函数,post()函数将收到的关键字传入之前设计的搜索系统中,得到返回值新闻条目。(3)通过webpy传递给result.html,得到html网页后发给客户端。
前后端实现 基于webpy界面设计搜索网页,建立交互的界面。在之前系统设计的基 础上,在webpy框架下,利用templates模板语言将后台结果与前端界面进行交互,并在服务器端使用GET和POST函数与客户端web交互并传递参数传递参数,将搜索新闻在网页上呈现出来。其主要步骤为:(1)客户端发送get请求,触发服务端get()函数,调用index.html网页,返回给客户端。(2)客户端发送搜索关键字并通过post方式给服务端,触发服务端post()函数,post()函数将收到的关键字传入之前设计的搜索系统中,得到返回值新闻条目。(3)通过webpy传递给result.html,得到html网页后发给客户端。 
 点击search之后的网页界面如下,将我们之前抓取的与“习近平”及“南海”有关的新闻链接按照相似度大小排列,同时列出相应的时间、内容及热度。
点击search之后的网页界面如下,将我们之前抓取的与“习近平”及“南海”有关的新闻链接按照相似度大小排列,同时列出相应的时间、内容及热度。 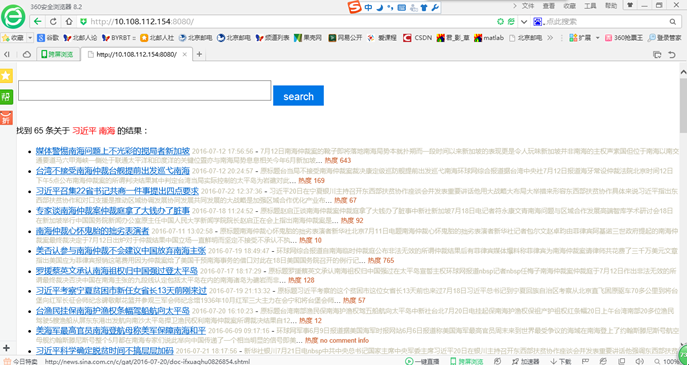 如果输入的关键词并不在之前建立的索引中,则会出现如下界面:
如果输入的关键词并不在之前建立的索引中,则会出现如下界面: 
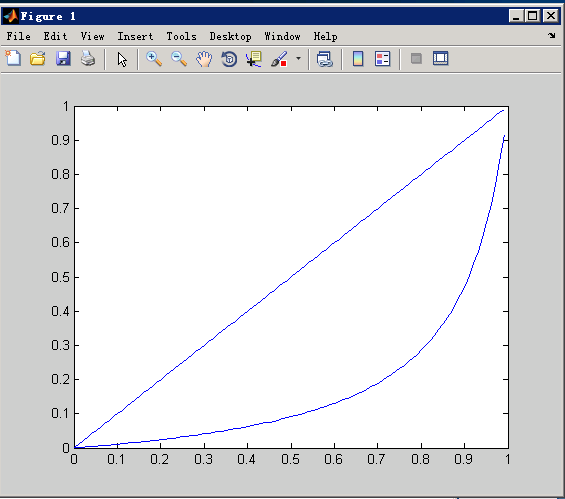
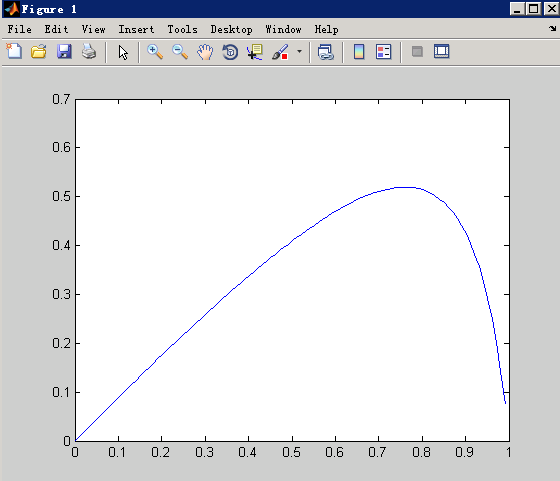
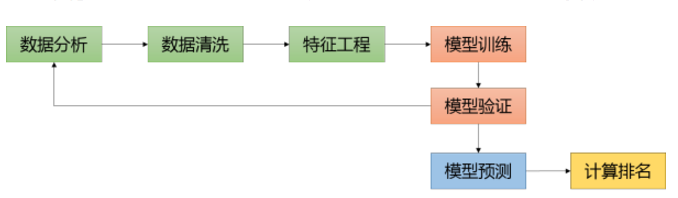
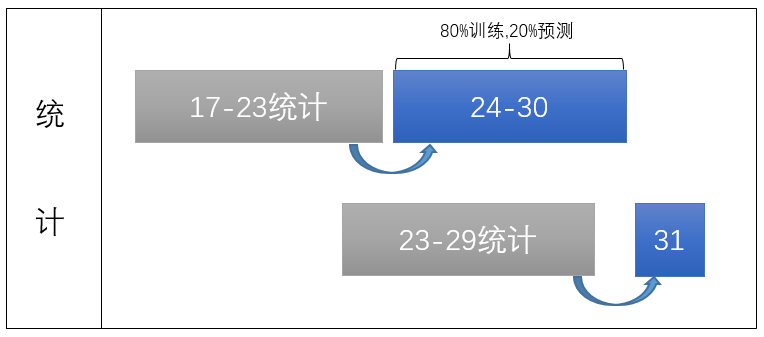
 经测试我们发现,即使我们去掉了30号的部分负样本,还是有一些问题的。因此我们将时间区间改了一下:
经测试我们发现,即使我们去掉了30号的部分负样本,还是有一些问题的。因此我们将时间区间改了一下: 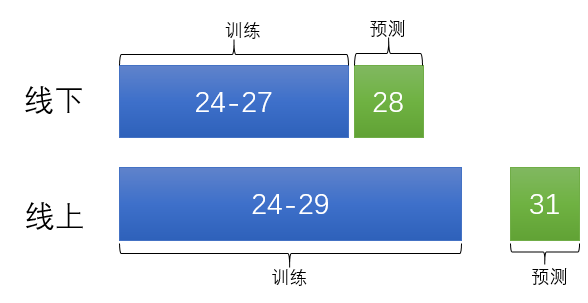 这样做出于两种目的:一是尽量做到了线上线下统一,二是不让模型学习30号的样本数据,防止一些错误样本被模型学到。
这样做出于两种目的:一是尽量做到了线上线下统一,二是不让模型学习30号的样本数据,防止一些错误样本被模型学到。