import pandas as pd
xiaoming=pd.DataFrame([1,2,3],index=['yellow','red','blue'],columns=['hat'])
print(xiaoming)
hat_ranks=pd.get_dummies(xiaoming['hat'],prefix='hat')
print(hat_ranks.head())
hat
yellow 1
red 2
blue 3
hat_1 hat_2 hat_3
yellow 1 0 0
red 0 1 0
blue 0 0 1
其它to DataFrame
dict to DataFrame
pd.DataFrame(d.items())
fillna
用同组的均值填补
>>> df
name value
0 A 1
1 A NaN
2 B NaN
3 B 2
4 B 3
5 B 1
6 C 3
7 C NaN
8 C 3
>>> df["value"] = df.groupby("name").transform(lambda x: x.fillna(x.mean()))
>>> df
name value
0 A 1
1 A 1
2 B 2
3 B 2
4 B 3
5 B 1
6 C 3
7 C 3
8 C 3
Same as the subsample of GBM. Denotes the fraction of observations to be randomly samples for each tree. Lower values make the algorithm more conservative and prevents overfitting but too small values might lead to under-fitting. Typical values: 0.5-1
colsample_bytree [default=1]
Similar to max_features in GBM. Denotes the fraction of columns to be randomly samples for each tree.
Typical values: 0.5-1 ### colsample_bylevel [default=1] Denotes the subsample ratio of columns for each split, in each level. I don’t use this often because subsample and colsample_bytree will do the job for you. but you can explore further if you feel so.
lambda [default=1]
L2 regularization term on weights (analogous to Ridge regression) This used to handle the regularization part of XGBoost. Though many data scientists don’t use it often, it should be explored to reduce overfitting.
alpha [default=0]
L1 regularization term on weight (analogous to Lasso regression) Can be used in case of very high dimensionality so that the algorithm runs faster when implemented
scale_pos_weight [default=1]
A value greater than 0 should be used in case of high class imbalance as it helps in faster convergence. Control the balance of positive and negative weights, useful for unbalanced classes. A typical value to consider: sum(negative cases) / sum(positive cases) See Parameters Tuning for more discussion. Also see Higgs Kaggle competition demo for examples: R, py1, py2, py3
其中: - xgb_params:参数 - xgtrain:训练集 - num_boost_round:树个数(迭代次数) - nfold:kfold的k - metrics:在CV中的评价度量指标 - early_stopping_rounds:Activates early stopping. CV error needs to decrease at least every round(s) to continue. Last entry in evaluation history is the one from best iteration.
#正则表达式获取<tr></tr>之间内容 res_tr = r'<tr>(.*?)</tr>' m_tr = re.findall(res_tr,language,re.S|re.M) for line in m_tr: print line #获取表格第一列th 属性 res_th = r'<th>(.*?)</th>' m_th = re.findall(res_th,line,re.S|re.M) for mm in m_th: print unicode(mm,'utf-8'), #unicode防止乱 #获取表格第二列td 属性值 res_td = r'<td>(.*?)</td>' m_td = re.findall(res_td,line,re.S|re.M) for nn in m_td: print unicode(nn,'utf-8')
#include <iostream>
#include<cstdio>
#include<cmath>
#include<cstdlib>
#include<cstring>
#include<string>
#include<algorithm>
#include <math.h>
using namespace std;
long quick_algorithm(long long a,long long n,int modNum){
a=a%modNum ;
long long ans=1 ;
//这里我们不需要考虑b<0,因为分数没有取模运算
while(n!=0){
if(n&1)
ans=(ans*a)%modNum ;
n>>=1 ;
a=(a*a)%modNum;
}
return ans;
}
long set2(long long n,int modNum){
long long a=3;
long long b=1;
/*for(long long i=0;i<n;i++){
a=a*3;
a=a%modNum;
}*/
a= quick_algorithm(a,n,modNum);
if(n%2==1){
b=-1;
}
//a=a;
a=0.5*a+0.5*b;
return a;
}
int main()
{
int modNum=1000000007;
long long input=999999999;
scanf("%lld",&input);
if(input==0||input==1){
printf("%lld\n",1);
}else{
long long out=set2(input,modNum);
printf("%lld\n",out);
}
return 0;
}


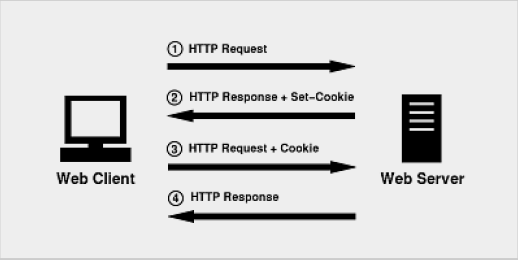 1. 浏览器第一次发起HTTP请求时,没有携带任何Cookie信息,服务器收到请求并返回给浏览器的HTTP响应,同时HTTP响应包括了一个响应头Set-Cookie字段,它的值是要设置的Cookie。 2. 浏览器收到来自服务器的HTTP响应,响应头中发现有Set-Cookie字段,就会将该字段的值保存在内存或者硬盘中。 3. 浏览器下次给该服务器发送HTTP请求时,会将Cookie信息附加在HTTP请求的头字段Cookie中。 4. 服务器收到这个HTTP请求,发现请求头中有Cookie字段,便知道之前就和这个用户打过交道了。
1. 浏览器第一次发起HTTP请求时,没有携带任何Cookie信息,服务器收到请求并返回给浏览器的HTTP响应,同时HTTP响应包括了一个响应头Set-Cookie字段,它的值是要设置的Cookie。 2. 浏览器收到来自服务器的HTTP响应,响应头中发现有Set-Cookie字段,就会将该字段的值保存在内存或者硬盘中。 3. 浏览器下次给该服务器发送HTTP请求时,会将Cookie信息附加在HTTP请求的头字段Cookie中。 4. 服务器收到这个HTTP请求,发现请求头中有Cookie字段,便知道之前就和这个用户打过交道了。